stats
stats 命令用于对搜索结果计算聚合。
比较 stats、eventstats 和 streamstats
关于 stats、eventstats 和 streamstats 命令的全面比较,包括它们在转换行为、输出格式、聚合范围和用例方面的差异,请参阅 比较 stats、eventstats 和 streamstats。
语法
stats 命令的语法如下:
stats [bucket_nullable=bool] <aggregation>... [by-clause]
参数
stats 命令支持以下参数。
| 参数 | 必需/可选 | 描述 |
|---|---|---|
<aggregation> |
必需 | 聚合函数。 |
<by-clause> |
可选 | 按指定字段或表达式对结果进行分组。语法:by [span-expression,] [field,]... 如果未指定 by-clause,则 stats 命令仅返回一行,即对整个搜索结果的聚合。 |
bucket_nullable |
可选 | 控制是否在分组聚合中包含 null 桶。当为 false 时,忽略 group-by 字段为 null 的记录,从而提高性能。默认值为 plugins.ppl.syntax.legacy.preferred 的值。 |
<span-expression> |
可选 | 按间隔将字段拆分为桶(最多一个)。语法:span(field_expr, interval_expr)。默认情况下,间隔使用字段的默认单位。对于日期/时间字段,聚合结果忽略空值。示例:span(age, 10) 创建 10 岁的年龄桶,span(timestamp, 1h) 创建小时桶。有效时间单位为毫秒 (ms)、秒 (s)、分钟 (m)、小时 (h)、天 (d)、周 (w)、月 (M)、季度 (q)、年 (y)。 |
聚合函数
stats 命令支持以下聚合函数:
COUNT/C– 值的计数SUM– 数值的总和AVG– 数值的平均值MAX– 最大值MIN– 最小值VAR_SAMP– 样本方差VAR_POP– 总体方差STDDEV_SAMP– 样本标准差STDDEV_POP– 总体标准差DISTINCT_COUNT_APPROX– 近似去重计数TAKE– 原始值列表PERCENTILE/PERCENTILE_APPROX– 百分位数计算PERC<percent>/P<percent>– 百分位数快捷函数MEDIAN– 第 50 百分位数(中位数)EARLIEST– 按时间戳最早的值LATEST– 按时间戳最新的值FIRST– 第一个非空值LAST– 最后一个非空值LIST– 将所有值收集到数组中VALUES– 将唯一值收集到排序数组中
有关每个函数的详细文档,请参阅 函数。
示例 1:计算事件计数
以下查询计算 accounts 索引中的事件计数:
source=accounts
| stats count()
该查询返回以下结果:

示例 2:计算字段的平均值
以下计算所有账户的平均年龄:
source=accounts
| stats avg(age)
该查询返回以下结果:
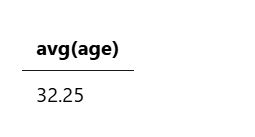
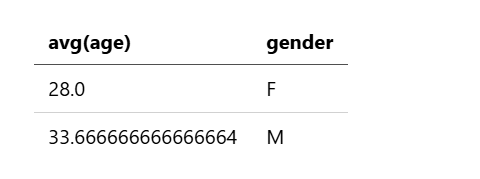
示例 3:按组计算字段的平均值
以下查询按性别分组,计算所有账户的平均年龄:
source=accounts
| stats avg(age) by gender
该查询返回以下结果:
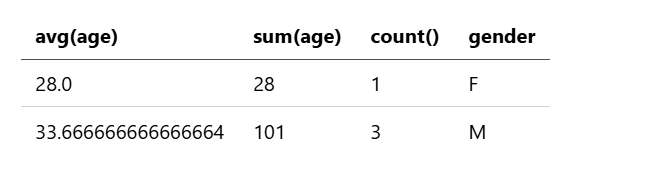
示例 4:按组计算字段的平均值、总和和计数
以下查询按性别分组,计算所有账户的平均年龄、年龄总和以及事件计数:
source=accounts
| stats avg(age), sum(age), count() by gender
该查询返回以下结果:
示例 5:计算字段的最大值
以下查询计算所有账户的最大年龄:
source=accounts
| stats max(age)
该查询返回以下结果:
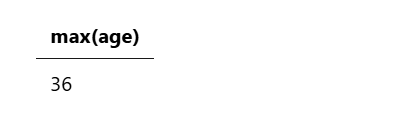
示例 6:按组计算字段的最大值和最小值
以下查询按性别分组,计算所有账户的最大和最小年龄:
source=accounts
| stats max(age), min(age) by gender
该查询返回以下结果:

示例 7:计算字段的去重计数
要检索字段的不同值的计数,可以使用 DISTINCT_COUNT(或 DC)函数代替 COUNT。以下查询计算所有账户中 gender 字段的计数和去重计数:
source=accounts
| stats count(gender), distinct_count(gender)
该查询返回以下结果:
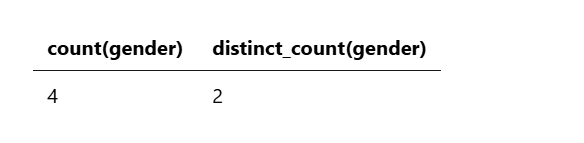
示例 8:按跨度计算计数
以下查询检索按 10 年间隔分组的 age 值计数:
source=accounts
| stats count(age) by span(age, 10) as age_span
该查询返回以下结果:

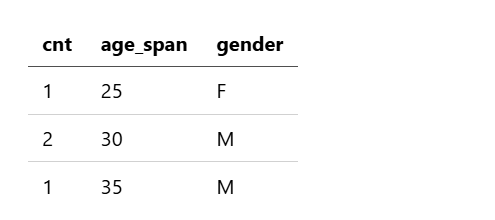
示例 9:按性别和跨度计算计数
以下查询检索按 5 年间隔分组并按 gender 细分的 age 计数:
source=accounts
| stats count() as cnt by span(age, 5) as age_span, gender
该查询返回以下结果:
无论 span 表达式在 by 子句中的位置如何,它始终被视为第一个分组键:
source=accounts
| stats count() as cnt by gender, span(age, 5) as age_span
该查询返回以下结果:

示例 10:按性别和年龄跨度计数并检索电子邮件列表
以下查询计算按 5 年间隔以及按 gender 分组的 age 值计数,并返回每个组最多 5 个电子邮件的列表:
source=accounts
| stats count() as cnt, take(email, 5) by span(age, 5) as age_span, gender
该查询返回以下结果:

示例 11:计算字段的百分位数
以下查询计算所有账户年龄的第 90 个百分位数:
source=accounts
| stats percentile(age, 90)
该查询返回以下结果:
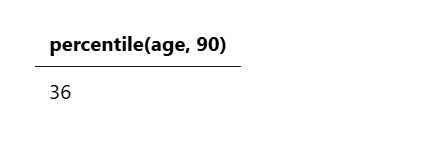
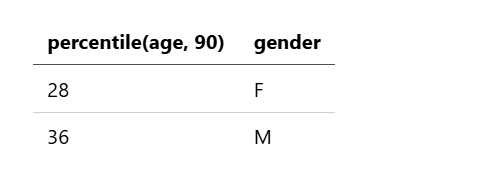
示例 12:按组计算字段的百分位数
以下查询按性别分组,计算所有账户年龄的第 90 个百分位数:
source=accounts
| stats percentile(age, 90) by gender
该查询返回以下结果:
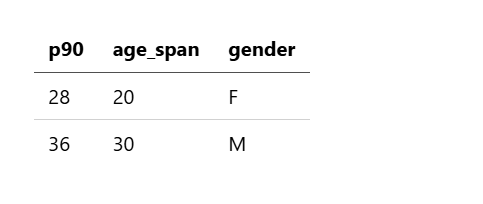
示例 13:按性别和跨度计算百分位数
以下查询计算按 10 年间隔以及按 gender 分组的年龄的第 90 个百分位数:
source=accounts
| stats percentile(age, 90) as p90 by span(age, 10) as age_span, gender
该查询返回以下结果: