search
search 命令用于从索引中检索文档。该命令只能作为 PPL 查询中的第一个命令使用。
语法
search 命令的语法如下:
search source=[<remote-cluster>:]<index> [<search-expression>]
参数
search 命令支持以下参数。
| 参数 | 必需/可选 | 描述 |
|---|---|---|
<index> |
必需 | 要查询的索引。索引名可以加上 <remote-cluster>:(远程集群名称)前缀以进行跨集群搜索。 |
<search-expression> |
可选 | 一个搜索表达式,该表达式将转换为 UDB-SX 查询字符串查询。 |
搜索表达式
搜索表达式语法支持:
全文搜索:
error或"error message"—— 搜索index.query.default_field设置中配置的默认字段(默认值为*,表示所有字段)。有关更多信息,请参阅 默认字段配置。字段值比较:
field=value、field!=value、field>value、field>=value、field<value或field<=value。时间修饰符:
earliest=timeModifier、latest=timeModifier—— 使用隐式@timestamp字段按时间范围过滤结果。有关更多信息,请参阅 时间修饰符。布尔运算符:
AND、OR或NOT。默认值为AND。使用括号分组:
(expression)。用于多个值的
IN运算符:field IN (value1, value2, value3)。通配符:
*(零个或多个字符)、?(恰好一个字符)。
全文搜索
与其他 PPL 命令不同,search 命令同时支持带引号和不带引号的字符串。不带引号的术语仅限于字母数字字符、连字符、下划线和通配符。任何其他字符都需要双引号。
以下查询展示了两种语法类型:
不带引号:
search error、search user-123、search log_*带引号:
search "error message"、search "user@example.com"
字段值
字段值遵循与搜索文本相同的引号规则。
字段值语法示例:
不带引号:
status=active、code=ERR-401带引号:
email="user@example.com"、message="server error"
时间修饰符
时间修饰符使用隐式 @timestamp 字段按时间范围过滤搜索结果。时间修饰符支持以下格式。
| 格式 | 语法 | 描述 | 示例 |
|---|---|---|---|
| 当前时间 | now 或 now() |
当前时间 | earliest=now |
| 绝对时间 | MM/dd/yyyy:HH:mm:ss 或 yyyy-MM-dd HH:mm:ss |
特定的日期和时间 | latest='2024-12-31 23:59:59' |
| Unix 时间戳 | 数值 | 自纪元以来的秒数 | latest=1754020060.123 |
| 相对时间 | [(+/-)<time_integer><time_unit>][@<round_to_unit>] |
相对于当前时间的时间偏移。参见 相对时间组件。 | earliest=-7d、latest='+1d@d' |
相对时间组件
相对时间修饰符使用多个可以组合的组件。下表描述了每个组件。
| 组件 | 语法 | 描述 | 示例 |
|---|---|---|---|
| 时间偏移 | + 或 - |
方向:+(未来)或 -(过去) |
+7d、-1h |
| 时间量 | <time_integer><time_unit> |
数值 + 时间单位 | 7d、1h、30m |
| 舍入单位 | @<round_to_unit> |
舍入到最近的单位 | @d(天)、@h(小时)、@m(分钟) |
以下是一些常见时间修饰符模式的示例:
earliest=now—— 从当前时间开始。latest='2024-12-31 23:59:59'—— 在特定日期和时间结束。earliest=-7d—— 从 7 天前开始。latest='+1d@d'—— 在明天的开始时结束。earliest='-1month@month'—— 从上个月初开始。latest=1754020061—— 在 Unix 时间戳1754020061(2025 年 8 月 1 日 03:47:41 UTC)结束。
在 search 命令中使用时间修饰符时,请注意以下事项:
列名冲突:如果您的数据包含名为
earliest或latest的列,请使用反引号将它们作为常规字段访问(例如,`earliest`="value"),以避免与时间修饰符语法冲突。时间舍入语法:具有链式时间偏移的时间修饰符必须用引号括起来(例如,
latest='+1d@month-10h')以便正确解析查询。
默认字段配置
当搜索未指定字段时,它会使用 index.query.default_field 索引设置配置的默认字段。默认情况下,此设置设为 *,即搜索所有字段。
要检索默认字段设置,请使用以下请求:
GET /accounts/_settings/index.query.default_field
要修改默认字段设置,请使用以下请求:
PUT /accounts/_settings
{
"index.query.default_field": "firstname,lastname,email"
}
按字段类型的搜索行为
不同的字段类型具有特定的搜索能力和限制。下表总结了搜索表达式如何与每种字段类型配合工作。
| 字段类型 | 支持的操作 | 示例 | 限制 |
|---|---|---|---|
| 文本 | 全文搜索、短语搜索 | search message="error occurred" source=logs |
通配符应用于分析后的词元,而非整个字段值 |
| 关键字 | 精确匹配、通配符模式 | search status="ACTIVE" source=logs |
无文本分析;匹配区分大小写 |
| 数值 | 范围查询、精确匹配、IN 运算符 |
search age>=18 AND balance<50000 source=accounts |
不支持通配符或文本搜索 |
| 日期 | 范围查询、精确匹配、IN 运算符 |
search timestamp>="2024-01-01" source=logs |
必须遵循索引映射的日期格式;不支持通配符 |
| 布尔值 | 精确匹配、true 和 false 值、IN 运算符 |
search active=true source=users |
不支持通配符或范围查询 |
| IP | 精确匹配、CIDR 表示法 | search client_ip="192.168.1.0/24" source=logs |
不支持部分 IP 通配符匹配。对于通配符搜索,请使用带关键字的 multi-field:search ip_address.keyword='1*' source=logs 或 WHERE 子句:source=logs | where cast(ip_address as string) like '1%' |
处理不同字段类型时,请考虑以下性能优化:
每种字段类型都有特定的搜索能力和限制。在数据摄入时选择不合适的字段类型可能会对性能和查询准确性产生负面影响。
对于非关键字字段的通配符搜索,请创建
keyword子字段以提高性能。例如,对于text类型的message字段的通配符搜索,请添加message.keyword字段。
示例 1:获取所有数据
通过仅指定源而不带任何搜索条件来检索索引中的所有文档。这对于探索小数据集或验证数据摄入很有用:
source=accounts
该查询返回以下结果:
| account_number | firstname | address | balance | gender | city | employer | state | age | lastname | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Amber | 880 Holmes Lane | 39225 | M | Brogan | Pyrami | IL | 32 | amberduke@pyrami.com | Duke |
| 6 | Hattie | 671 Bristol Street | 5686 | M | Dante | Netagy | TN | 36 | hattiebond@netagy.com | Bond |
| 13 | Nanette | 789 Madison Street | 32838 | F | Nogal | Quility | VA | 28 | null | Bates |
| 18 | Dale | 467 Hutchinson Court | 4180 | M | Orick | null | MD | 33 | daleadams@boink.com | Adams |
示例 2:布尔逻辑和运算符优先级
以下查询演示了布尔运算符和优先级。
布尔运算符
使用 OR 匹配包含任何指定条件的文档:
search severityText="ERROR" OR severityText="FATAL" source=otellogs
| sort @timestamp
| fields severityText
| head 3
该查询返回以下结果:

使用 AND 组合条件以要求所有条件都匹配:
search severityText="INFO" AND `resource.attributes.service.name`="cart-service" source=otellogs
| fields body
| head 1
该查询返回以下结果:

运算符优先级
运算符使用以下优先级进行评估:
括号 > NOT > OR > AND
以下查询演示了运算符优先级:
search severityText="ERROR" OR severityText="WARN" AND severityNumber>15 source=otellogs
| sort @timestamp
| fields severityText, severityNumber
| head 2
前面的表达式被计算为 (severityText="ERROR" OR severityText="WARN") AND severityNumber>15。该查询返回以下结果:

示例 3:NOT 与 != 语义比较
!= 和 NOT 运算符都查找字段值不等于指定值的文档。但是,!= 运算符排除包含空值或缺失字段的文档,而 NOT 运算符包含它们。以下查询显示了这一差异。
!= 运算符
查找 employer 字段存在且不等于 Quility 的所有账户:
search employer!="Quility" source=accounts
该查询返回以下结果:

NOT 运算符
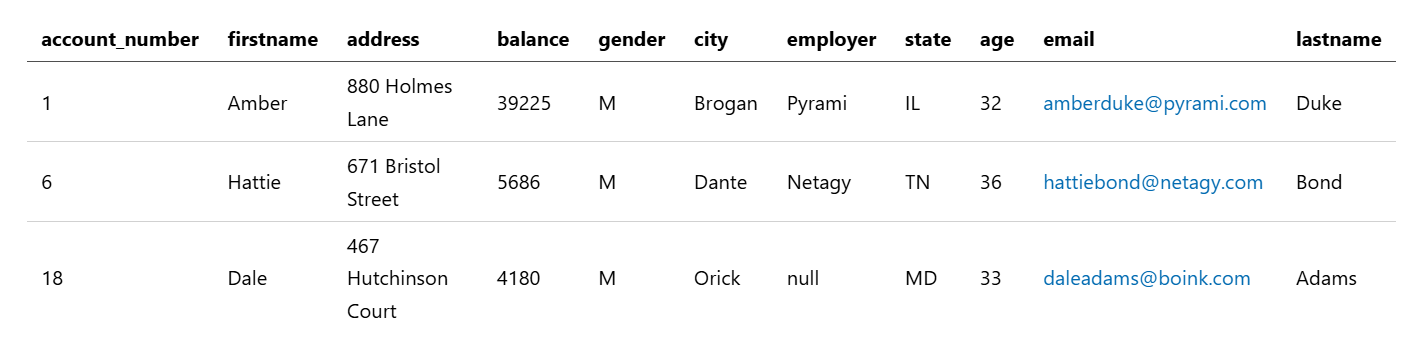
查找所有未指定 Quility 作为雇主的账户(包括那些雇主值为空的账户):
search NOT employer="Quility" source=accounts
该查询返回以下结果。Dale Adams 出现在搜索结果中,因为他的 employer 字段为 null:
示例 4:范围查询
使用比较运算符(>、<、>= 和 <=)在特定范围内过滤数值和日期字段。范围查询对于按年龄、价格、时间戳或任何数字指标进行过滤特别有用:
search severityNumber>15 AND severityNumber<=20 source=otellogs
| sort @timestamp
| fields severityNumber
| head 3
该查询返回以下结果:
| severityNumber |
|---|
| 17 |
| 17 |
| 18 |
该查询返回以下结果:

示例 5:字段值匹配
IN 运算符高效地检查字段是否匹配列表中的任何值,提供了比在相同字段上链接多个 OR 条件更简洁且性能更好的替代方案。
检查字段是否匹配预定义列表中的任何值:
search severityText IN ("ERROR", "WARN", "FATAL") source=otellogs
| sort @timestamp
| fields severityText
| head 3
该查询返回以下结果:

按 severityNumber 过滤日志以查找具有特定数字严重性级别的错误:
search severityNumber=17 source=otellogs
| sort @timestamp
| fields body
| head 1
该查询返回以下结果:

搜索在属性中包含特定用户电子邮件地址的日志:
search attributes.user.email ="user@example.com" source=otellogs
| fields body
该查询返回以下结果:
