UDB-SX简介
UDB-SX 是一个分布式搜索与分析引擎,可支持多种使用场景——从网站搜索框实现到安全数据分析与威胁检测。“分布式” 意味着你可以在多台计算机上运行 UDB-SX;“搜索与分析” 意味着一旦将数据导入 UDB-SX,就可以对其进行搜索与分析。无论数据类型如何,UDB-SX 都能帮助你存储并分析它。
文档
文档 是存储信息(文本或结构化数据)的基本单位。在 UDB-SX 中,文档以 JSON 格式存储。
文档可以理解为:
在学生数据库中,一个文档代表一名学生。
当你执行搜索时,UDB-SX 返回与你查询相关的文档。
在传统数据库中,一个文档相当于一行记录。
例如,一个学校数据库中的一个文档表示一名学生,并包含以下数据:
| ID | 姓名 | GPA | 毕业年份 |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
该文档的 JSON 格式如下:
{
"name": "John Doe",
"gpa": 3.89,
"grad_year": 2022
}
关于文档 ID 的分配方式,可参见 索引文档。
索引
索引 是文档的集合。
索引可以理解为:
在学生数据库中,一个索引代表所有学生。
执行搜索时,你查询的数据存储在索引中。
在传统数据库中,一个索引相当于一张表。
例如,一个学校的学生索引包含该校所有学生:
| ID | 姓名 | GPA | 毕业年份 |
|---|---|---|---|
| 1 | John Doe | 3.89 | 2022 |
| 2 | Jonathan Powers | 3.85 | 2025 |
| 3 | Jane Doe | 3.52 | 2024 |
| ... |
集群与节点
UDB-SX 设计为分布式搜索引擎,可运行在一个或多个 节点(node) 上——每个节点都是存储数据并处理搜索请求的服务器。一个 集群(cluster) 是多个节点的集合。
你可以在笔记本电脑上本地运行 UDB-SX(系统需求较低),也可以在数据中心扩展至数百台服务器。
在单节点集群中,所有任务都由一台机器完成:管理集群状态、索引与搜索数据、以及数据预处理。但随着集群规模扩大,可以细分任务。例如,磁盘性能好且内存充足的节点适合索引和搜索,而 CPU 性能强的节点适合管理集群状态。
每个集群都有一个被选举出的 集群管理节点(cluster manager),负责协调集群级操作,如创建索引。节点之间相互通信,当请求到达某个节点时,该节点会与其他节点交互,收集响应并返回最终结果。
分片
UDB-SX 会将索引拆分为 分片,每个分片存储索引中部分文档,如下图所示:
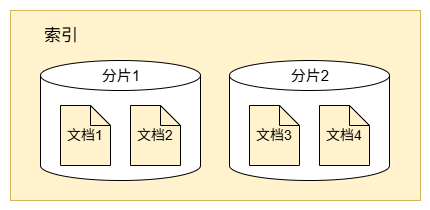
分片用于在集群中实现负载均衡。例如,一个 400 GB 的索引可能过大,单个节点无法承载。
若将其拆分为 10 个 40 GB 的分片,UDB-SX 可以将分片分布在 10 个节点上分别管理。
假设一个集群包含两个索引:index1 和 index2。index1 被拆为 2 个分片,index2 被拆为 4 个分片。分片分布如下:
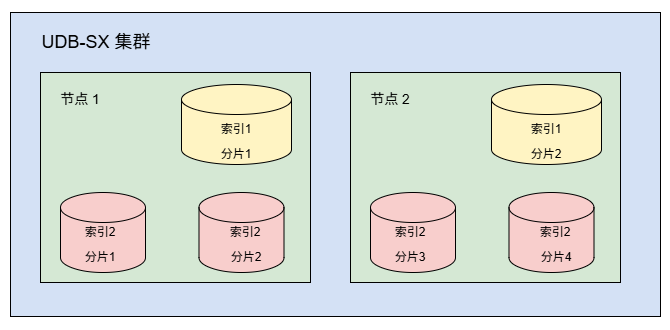
需要注意,每个分片实际上是一个完整的 Lucene 索引进程,会消耗 CPU 与内存。
分片数量越多不一定越好——例如将 400 GB 拆成 1000 个分片会严重影响性能。
经验法则是:单个分片大小建议控制在 10–50 GB 之间。
主分片与副本分片(Primary and Replica Shards)
在 UDB-SX 中,分片可以是 主分片(primary) 或 副本分片(replica)。
默认情况下,每个主分片都会有一个副本分片。
例如,一个索引被拆为 10 个主分片,则 UDB-SX 会创建 10 个副本分片。
继续上节示例,若为每个分片添加一个副本,则集群中将包含 index1 的 2 个主分片 + 2 个副本,index2 的 4 个主分片 + 4 个副本:
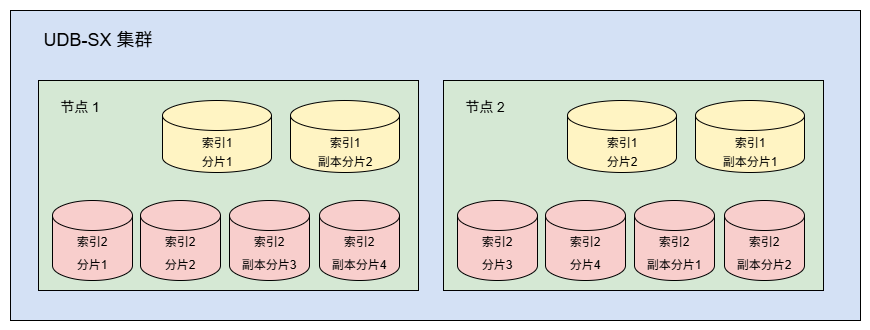
副本分片在节点故障时充当备份(存放在不同节点上),同时也提升搜索性能。对于搜索量大的场景,可以为索引设置多个副本。
倒排索引
UDB-SX 索引基于一种名为 倒排索引 的数据结构,它将单词映射到出现该单词的文档。
例如,一个索引中包含两个文档:
文档 1:“Beauty is in the eye of the beholder”
文档 2:“Beauty and the beast”
对应的倒排索引如下:
| 单词 | 文档 |
|---|---|
| beauty | 1, 2 |
| is | 1 |
| in | 1 |
| the | 1, 2 |
| eye | 1 |
| of | 1 |
| beholder | 1 |
| and | 2 |
| beast | 2 |
此外,UDB-SX 还记录单词在文档中的位置,以支持短语查询(词语相邻的搜索)。
相关性
当你搜索一个文档时,UDB-SX 会将查询中的词与文档中的词匹配,并为每个文档分配一个 相关性分数(relevance score),用于衡量匹配程度。
搜索中的每个词称为 搜索词项(term),其评分依据如下规则:
词项在文档中出现得越频繁,得分越高(词频 Term Frequency)。
词项出现在越多文档中,得分越低(逆文档频率 Inverse Document Frequency)。
长文档的匹配得分通常低于短文档(长度归一化 Length Normalization)。
UDB-SX 使用 BM25 排名算法 计算相关性分数,并按分数排序返回结果。
详情参见 Okapi BM25。
进阶
更新生命周期
一次更新操作的生命周期包括:
事务日志
索引或批量写入请求在文档写入事务日志并刷新到磁盘后返回响应,保证更新持久性。但更新在执行 refresh 之前不可被搜索到。
刷新
UDB-SX 会周期性执行 刷新操作,将内存中的文档写入文件,使其可被搜索。刷新不会执行 fsync,因此文件尚未真正持久化。
刷写
Flush 操作用 fsync 将文件同步至磁盘,确保数据持久化。它还会清除已持久化的 translog,防止日志无限增长。
合并
每个分片是一个 Lucene 索引,由多个 段(segment) 组成。段是不可变的,UDB-SX 会定期将小段合并为大段,从而:
减少段数量;
释放磁盘空间;
提升搜索性能。
当段达到合并策略指定的最大尺寸后,将不再继续合并。