flatten
flatten 命令将结构体或对象字段转换为文档中的独立字段。
生成的扁平化字段按其原始键名的字典序排列。例如,如果一个结构体包含键 b、c 和 Z,则扁平化后的字段顺序为 Z、b、c。
flatten 不应应用于数组。若要将数组字段展开为多行,请使用 expand 命令。请注意,在 UDB-SX 中,数组可能存储在非数组字段中;当扁平化包含嵌套数组的字段时,仅数组的第一个元素会被扁平化。
语法
flatten 命令的语法如下:
flatten <field> [as (<alias-list>)]
参数
flatten 命令支持以下参数。
| 参数 | 必需/可选 | 描述 |
|---|---|---|
<field> |
必需 | 要扁平化的字段。仅支持对象和嵌套字段。 |
<alias-list> |
可选 | 用于替代原始键名的名称列表,以逗号分隔。如果指定多个别名,请将列表括在括号中。别名的数量必须与结构体中的键数匹配,并且别名必须按照对应原始键的字典序排列。 |
示例:使用别名扁平化对象字段
给定以下索引 my-index:
{"message":{"info":"a","author":"e","dayOfWeek":1},"myNum":1}
{"message":{"info":"b","author":"f","dayOfWeek":2},"myNum":2}
其映射如下:
{
"mappings": {
"properties": {
"message": {
"type": "object",
"properties": {
"info": {
"type": "keyword",
"index": "true"
},
"author": {
"type": "keyword",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"index": "true"
},
"dayOfWeek": {
"type": "long"
}
}
},
"myNum": {
"type": "long"
}
}
}
}
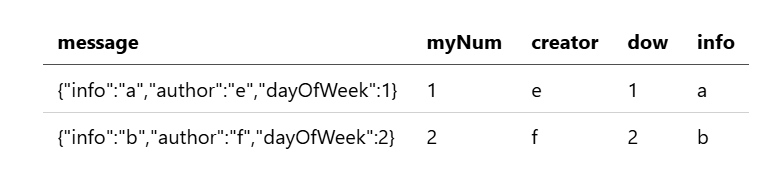
以下查询扁平化了 message 对象字段,并使用别名将扁平化后的字段重命名为 creator, dow, info:
source=my-index
| flatten message as (creator, dow, info)
该查询返回以下结果:
限制
flatten 命令有以下限制:
如果要扁平化的字段不可见,
flatten命令可能无法按预期工作。例如,在查询source=my-index | fields message | flatten message中,flatten message命令无法按预期执行,因为在fields message命令之后,一些扁平化后的字段(如message.info和message.author)被隐藏了。替代方案是使用source=my-index | flatten message。