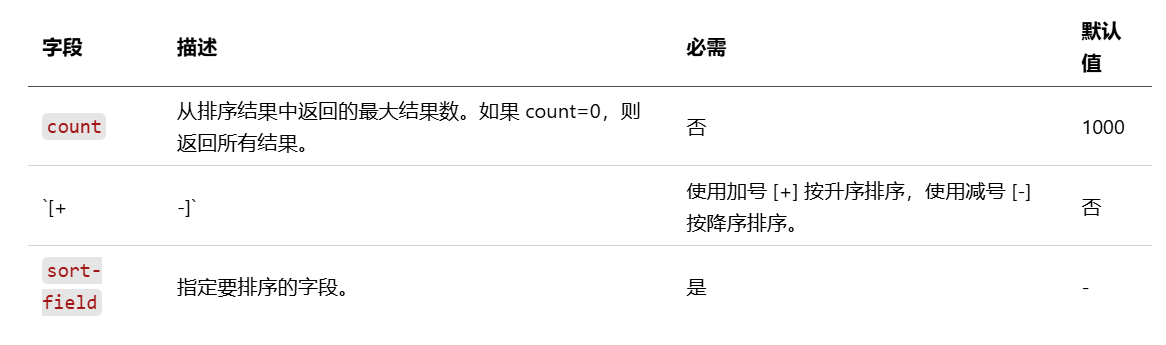
命令
PPL 支持大多数 SQL 通用函数,包括相关性搜索,同时也引入了一些仅在 PPL 中可用的函数(称为 命令)。
dedup
dedup(数据去重)命令根据字段从搜索结果中移除重复文档。
语法
dedup [int] <field-list> [keepempty=<bool>] [consecutive=<bool>]
| 字段 | 描述 | 类型 | 必需 | 默认值 |
|---|---|---|---|---|
int |
为每种组合保留指定数量的重复事件。该数字必须大于0。如果未指定数字,则仅保留第一个出现的事件,并从结果中移除所有其他重复项。 | string |
否 | 1 |
keepempty |
如果为 true,当字段列表中的任何字段具有 null 值或字段缺失时,保留该文档。 | 嵌套对象列表 |
否 | False |
consecutive |
如果为 true,仅移除具有重复值组合的连续事件。 | 布尔值 |
否 | False |
field-list |
指定一个逗号分隔的字段列表。至少需要一个字段。 | 字符串 或逗号分隔的字符串列表 |
是 | - |
示例 1:按一个字段去重
移除具有相同性别的重复文档:
search source=accounts | dedup gender | fields account_number, gender;
| account_number | gender |
|---|---|
| 1 | M |
| 13 | F |
示例 2:保留两个重复文档
保留两个具有相同性别的重复文档:
search source=accounts | dedup 2 gender | fields account_number, gender;
| account_number | gender |
|---|---|
| 1 | M |
| 6 | M |
| 13 | F |
示例 3:默认情况下保留或忽略空字段
保留两个具有 null 字段值的重复文档:
search source=accounts | dedup email keepempty=true | fields account_number, email;
| account_number | |
|---|---|
| 1 | amberduke@pyrami.com |
| 6 | hattiebond@netagy.com |
| 13 | null |
| 18 | daleadams@boink.com |
移除具有 null 字段值的重复文档:
search source=accounts | dedup email | fields account_number, email;
| account_number | |
|---|---|
| 1 | amberduke@pyrami.com |
| 6 | hattiebond@netagy.com |
| 18 | daleadams@boink.com |
示例 4:连续文档去重
移除连续文档的重复项:
search source=accounts | dedup gender consecutive=true | fields account_number, gender;
| account_number | gender |
|---|---|
| 1 | M |
| 13 | F |
| 18 | M |
限制
dedup 命令不会被重写为 UDB-SX DSL,它仅在协调节点上执行。
eval
eval 命令评估一个表达式并将其结果附加到搜索结果。
语法
eval <field>=<expression> ["," <field>=<expression> ]...
| 字段 | 描述 | 必需 |
|---|---|---|
field |
如果字段名不存在,则添加新字段。如果字段名已存在,则覆盖它。 | 是 |
expression |
指定任何受支持的表达式。 | 是 |
示例 1:创建新字段
为每个文档创建新的 doubleAge 字段。doubleAge 是 age 乘以 2 的结果:
search source=accounts | eval doubleAge = age * 2 | fields age, doubleAge;
| age | doubleAge |
|---|---|
| 32 | 64 |
| 36 | 72 |
| 28 | 56 |
| 33 | 66 |
示例 2:覆盖现有字段
用 age 加 1 覆盖 age 字段:
search source=accounts | eval age = age + 1 | fields age;
| age |
|---|
| 33 |
| 37 |
| 29 |
| 34 |
示例 3:使用 eval 命令定义的字段创建新字段
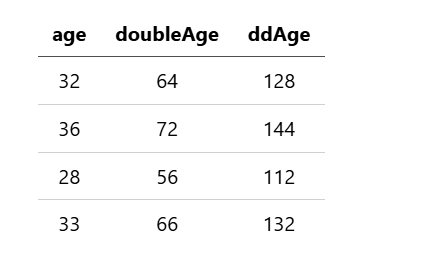
创建新字段 ddAge。ddAge 是 doubleAge 乘以 2 的结果,其中 doubleAge 是在 eval 命令中定义的:
search source=accounts | eval doubleAge = age * 2, ddAge = doubleAge * 2 | fields age, doubleAge, ddAge;
限制
eval 命令不会被重写为 UDB-SX DSL,它仅在协调节点上执行。
fields
使用 fields 命令从搜索结果中保留或移除字段。
语法
fields [+|-] <field-list>
| 字段 | 描述 | 必需 | 默认值 |
|---|---|---|---|
index |
加号 (+) 仅保留字段列表中指定的字段。减号 (-) 移除字段列表中指定的所有字段。 | 否 | + |
field list |
指定一个逗号分隔的字段列表。 | 是 | 无默认值 |
示例 1:从结果中选择指定字段
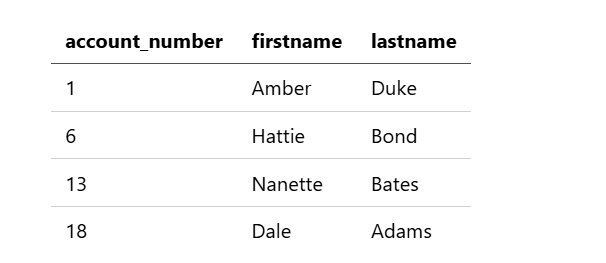
从搜索结果中获取 account_number、firstname 和 lastname 字段:
search source=accounts | fields account_number, firstname, lastname;
示例 2:从搜索结果中移除指定字段
从搜索结果中移除 account_number 字段:
search source=accounts | fields account_number, firstname, lastname | fields - account_number;
| firstname | lastname |
|---|---|
| Amber | Duke |
| Hattie | Bond |
| Nanette | Bates |
| Dale | Adams |
parse
使用 parse 命令通过正则表达式解析文本字段,并将结果附加到搜索结果。
语法
parse <field> <regular-expression>
| 字段 | 描述 | 必需 |
|---|---|---|
| field | 一个文本字段。 | 是 |
| regular-expression | 用于从给定测试字段中提取新字段的正则表达式。如果新字段名已存在,它将替换原始字段。 | 是 |
正则表达式用于通过 Java 正则表达式引擎匹配每个文档的整个文本字段。表达式中的每个命名捕获组将成为一个新的 STRING 字段。
示例 1:创建新字段
该示例展示如何为每个文档创建新字段 host。host 将是 email 字段中 @ 之后的主机名。解析 null 字段将返回空字符串。
os> source=accounts | parse email '.+@(?<host>.+)' | fields email, host ;
fetched rows / total rows = 4/4
| host | |
|---|---|
| amberduke@pyrami.com | pyrami.com |
| hattiebond@netagy.com | netagy.com |
| null | null |
| daleadams@boink.com | boink.com |
示例 2:覆盖现有字段
该示例展示如何使用移除街道编号后的地址覆盖现有的地址字段。
os> source=accounts | parse address '\d+ (?<address>.+)' | fields address ;
fetched rows / total rows = 4/4
| address |
|---|
| Holmes Lane |
| Bristol Street |
| Madison Street |
| Hutchinson Court |
示例 3:过滤和排序转换后的解析字段
该示例展示如何对地址字段中大于 500 的街道编号进行排序。
os> source=accounts | parse address '(?<streetNumber>\d+) (?<street>.+)' | where cast(streetNumber as int) > 500 | sort num(streetNumber) | fields streetNumber, street ;
fetched rows / total rows = 3/3
| streetNumber | street |
|---|---|
| 671 | Bristol Street |
| 789 | Madison Street |
| 880 | Holmes Lane |
限制
使用 parse 命令时存在一些限制:
由 parse 定义的字段不能再次解析。例如,
source=accounts | parse address '\d+ (?<street>.+)' | parse street '\w+ (?<road>\w+)' ;将无法返回任何表达式。由 parse 定义的字段不能被其他命令覆盖。例如,输入
source=accounts | parse address '\d+ (?<street>.+)' | eval street='1' | where street='1' ;,where将不会匹配任何文档,因为street无法被覆盖。parse 使用的文本字段不能被覆盖。例如,输入
source=accounts | parse address '\d+ (?<street>.+)' | eval address='1' ;,street将不会被解析,因为 address 已被覆盖。在
stats命令中使用由 parse 定义的字段后,无法对其进行过滤/排序。例如,source=accounts | parse email '.+@(?<host>.+)' | stats avg(age) by host | where host=pyrami.com ;,where将不会解析列出的域名。
rename
使用 rename 命令重命名搜索结果中的一个或多个字段。
语法
rename <source-field> AS <target-field>["," <source-field> AS <target-field>]...
| 字段 | 描述 | 必需 |
|---|---|---|
source-field |
要重命名的字段名称。 | 是 |
target-field |
要重命名成的新名称。 | 是 |
示例 1:重命名一个字段
将 account_number 字段重命名为 an:
search source=accounts | rename account_number as an | fields an;
| an |
|---|
| 1 |
| 6 |
| 13 |
| 18 |
示例 2:重命名多个字段
将 account_number 字段重命名为 an,并将 employer 重命名为 emp:
search source=accounts | rename account_number as an, employer as emp | fields an, emp;
| an | emp |
|---|---|
| 1 | Pyrami |
| 6 | Netagy |
| 13 | Quility |
| 18 | null |
限制
rename 命令不会被重写为 UDB-SX DSL,它仅在协调节点上执行。
sort
使用 sort 命令按指定字段对搜索结果进行排序。
语法
sort [count] <[+|-] sort-field>...
示例 1:按一个字段排序
按 age 字段升序排序所有文档:
search source=accounts | sort age | fields account_number, age;
| account_number | age |
|---|---|
| 13 | 28 |
| 1 | 32 |
| 18 | 33 |
| 6 | 36 |
语法:用于时间序列数据的固定时间 RCF 命令
ad <shingle_size> <time_decay> <time_field>
| 字段 | 描述 | 必需 |
|---|---|---|
shingle_size |
最近记录的一个连续序列。默认值为 8。 | 否 |
time_decay |
指定在计算异常分数时考虑最近多少过去数据。默认值为 0.001。 | 否 |
time_field |
指定 RCF 用作时间序列数据的时间字段。必须是长整型值(例如以毫秒为单位的时间戳)或字符串值(格式为 "yyyy-MM-dd HH:mm:ss")。 | 是 |
语法:用于非时间序列数据的批量 RCF 命令
ad <shingle_size> <time_decay>
| 字段 | 描述 | 必需 |
|---|---|---|
shingle_size |
最近记录的一个连续序列。默认值为 8。 | 否 |
time_decay |
指定在计算异常分数时考虑最近多少过去数据。默认值为 0.001。 | 否 |
示例 1:使用时间序列数据从出租车乘客数据中检测纽约市的事件
该示例训练一个 RCF 模型并使用该模型检测时间序列乘客数据中的异常。
PPL 查询:
os> source=nyc_taxi | fields value, timestamp | AD time_field='timestamp' | where value=10844.0
| value | timestamp | score | anomaly_grade |
|---|---|---|---|
| 10844.0 | 1404172800000 | 0.0 | 0.0 |
示例 2:使用非时间序列数据从出租车乘客数据中检测纽约市的事件
PPL 查询:
os> source=nyc_taxi | fields value | AD | where value=10844.0
| value | score | anomalous |
|---|---|---|
| 10844.0 | 0.0 | false |
kmeans
kmeans 命令将 ML Commons 插件的 kmeans 算法应用于提供的 PPL 命令的搜索结果。
语法
kmeans <cluster-number>
对于 cluster-number,输入您希望将数据点分组成的簇数。
示例:对 Iris 数据进行分组
该示例展示如何根据每个样本测量的四个特征的组合对三种鸢尾花(Iris setosa、Iris virginica 和 Iris versicolor)进行分类:萼片的长度和宽度以及花瓣的长度和宽度。
PPL 查询:
os> source=iris_data | fields sepal_length_in_cm, sepal_width_in_cm, petal_length_in_cm, petal_width_in_cm | kmeans centroids=3
| sepal_length_in_cm | sepal_width_in_cm | petal_length_in_cm | petal_width_in_cm | ClusterID |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | 1 |
| 5.6 | 3.0 | 4.1 | 1.3 | 0 |
| 6.7 | 2.5 | 5.8 | 1.8 | 2 |