基本查询
使用 SELECT 子句,结合 FROM、WHERE、GROUP BY、HAVING、ORDER BY 和 LIMIT 来搜索和聚合数据。
在这些子句中,SELECT 和 FROM 是必需的,因为它们指定要检索哪些字段以及从哪些索引中检索。所有其他子句都是可选的。请根据需要使用它们。
语法
搜索和聚合数据的完整语法如下:
SELECT [DISTINCT] (* | expression) [[AS] alias] [, ...]
FROM index_name
[WHERE predicates]
[GROUP BY expression [, ...]
[HAVING predicates]]
[ORDER BY expression [IS [NOT] NULL] [ASC | DESC] [, ...]]
[LIMIT [offset, ] size]
基础元素
除了 SQL 的预定义关键字外,最基本的元素是字面量和标识符。 字面量是数值、字符串、日期或布尔常量。标识符是 UDB-SX 索引或字段名。 通过算术运算符和 SQL 函数,使用字面量和标识符构建复杂表达式。
规则 expressionAtom:

表达式进而可以通过逻辑运算符组合成谓词。在 WHERE 和 HAVING 子句中使用谓词,以根据特定条件过滤数据。
规则 expression:
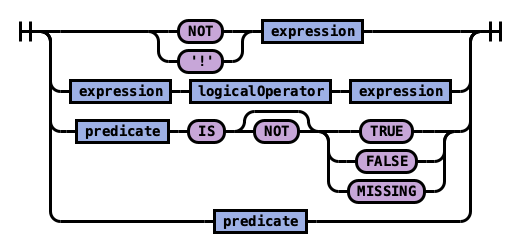
规则 predicate:
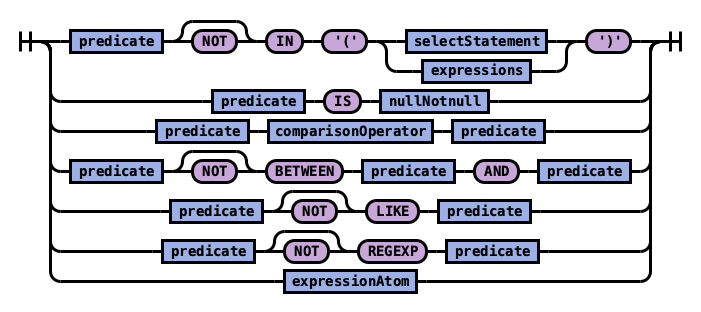
执行顺序
这些 SQL 子句的执行顺序与其出现顺序不同:
FROM index
WHERE predicates
GROUP BY expressions
HAVING predicates
SELECT expressions
ORDER BY expressions
LIMIT size
Select
指定要检索的字段。
语法
规则 selectElements:

规则 selectElement:
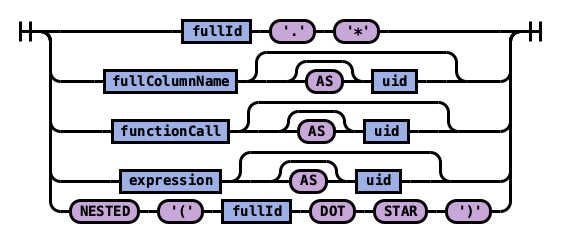
示例 1:使用 * 检索索引中的所有字段:
SELECT *
FROM accounts
| account_number | firstname | gender | city | balance | employer | state | address | lastname | age | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Amber | M | Brogan | 39225 | Pyrami | IL | amberduke@pyrami.com | 880 Holmes Lane | Duke | 32 |
| 16 | Hattie | M | Dante | 5686 | Netagy | TN | hattiebond@netagy.com | 671 Bristol Street | Bond | 36 |
| 13 | Nanette | F | Nogal | 32838 | Quility | VA | nanettebates@quility.com | 789 Madison Street | Bates | 28 |
| 18 | Dale | M | Orick | 4180 | MD | daleadams@boink.com | 467 Hutchinson Court | Adams | 33 |
示例 2:使用字段名仅检索特定字段:
SELECT firstname, lastname
FROM accounts
| firstname | lastname |
|---|---|
| Amber | Duke |
| Hattie | Bond |
| Nanette | Bates |
| Dale | Adams |
示例 3:使用字段别名代替字段名。字段别名用于使字段名更具可读性:
SELECT account_number AS num
FROM accounts
| num |
|---|
| 1 |
| 6 |
| 13 |
| 18 |
示例 4:使用 DISTINCT 子句仅获取唯一的字段值。您可以指定一个或多个字段名:
SELECT DISTINCT age
FROM accounts
| age |
|---|
| 28 |
| 32 |
| 33 |
| 36 |
From
指定您要搜索的索引。
您可以在 FROM 子句中指定子查询。
语法
规则 tableName:
示例 1:使用索引别名跨索引查询。
在此示例查询中,acc 是 accounts 索引的别名:
SELECT account_number, accounts.age
FROM accounts
或
SELECT account_number, acc.age
FROM accounts acc
| account_number | age |
|---|---|
| 1 | 32 |
| 6 | 36 |
| 13 | 28 |
| 18 | 33 |
示例 2:使用索引模式查询匹配特定模式的索引:
SELECT account_number
FROM account*
| account_number |
|---|
| 1 |
| 6 |
| 13 |
| 18 |
Where
指定条件以过滤结果。
| 运算符 | 行为 |
|---|---|
= |
等于。 |
<> |
不等于。 |
> |
大于。 |
< |
小于。 |
>= |
大于或等于。 |
<= |
小于或等于。 |
IN |
指定多个 OR 运算符。 |
BETWEEN |
类似于范围查询。 |
LIKE |
用于全文搜索。有关全文查询的更多信息,请参阅全文查询。 |
IS NULL |
检查字段值是否为 NULL。 |
IS NOT NULL |
检查字段值是否 NOT NULL。 |
将比较运算符(=、<>、>、>=、<、<=)与布尔运算符 NOT、AND 或 OR 结合使用,以构建更复杂的表达式。
示例 1:对数字、字符串或日期使用比较运算符:
SELECT account_number
FROM accounts
WHERE account_number = 1
| account_number |
|---|
| 1 |
示例 2:UDB-SX 允许灵活的模式,因此索引中的文档可能具有不同的字段。使用 IS NULL 或 IS NOT NULL 仅检索缺失的字段或存在的字段。UDB-SX 不区分缺失字段和显式设置为 NULL 的字段:
SELECT account_number, employer
FROM accounts
WHERE employer IS NULL
| account_number | employer |
|---|---|
| 18 |
示例 3:删除满足 WHERE 子句中谓词的文档:
DELETE FROM accounts
WHERE age > 30
Group By
将具有相同字段值的文档分组到桶中。
示例 1:按字段分组:
SELECT age
FROM accounts
GROUP BY age
| id | age |
|---|---|
| 0 | 28 |
| 1 | 32 |
| 2 | 33 |
| 3 | 36 |
示例 2:按字段别名分组:
SELECT account_number AS num
FROM accounts
GROUP BY num
| id | num |
|---|---|
| 0 | 1 |
| 1 | 6 |
| 2 | 13 |
| 3 | 18 |
示例 4:在 GROUP BY 子句中使用标量函数:
SELECT ABS(age) AS a
FROM accounts
GROUP BY ABS(age)
| id | a |
|---|---|
| 0 | 28.0 |
| 1 | 32.0 |
| 2 | 33.0 |
| 3 | 36.0 |
Having
使用 HAVING 子句基于聚合函数(COUNT、AVG、SUM、MIN 和 MAX)在每个桶内聚合。
HAVING 子句过滤来自 GROUP BY 子句的结果:
示例 1:
SELECT age, MAX(balance)
FROM accounts
GROUP BY age HAVING MIN(balance) > 10000
| id | age | MAX (balance) |
|---|---|---|
| 0 | 28 | 32838 |
| 1 | 32 | 39225 |
Order By
使用 ORDER BY 子句将结果排序为您所需的顺序。
示例 1:使用 ORDER BY 按升序或降序排序。除了常规字段名外,还支持使用 ordinal、alias 或 scalar 函数:
SELECT account_number
FROM accounts
ORDER BY account_number DESC
| account_number |
|---|
| 18 |
| 13 |
| 6 |
| 1 |
示例 2:指定是否将缺失字段的文档放在结果的开头或结尾。UDB-SX 的默认行为是将空值或缺失字段放在末尾。要将它们推到非空值之前,请使用 IS NOT NULL 运算符:
SELECT employer
FROM accounts
ORDER BY employer IS NOT NULL
| employer |
|---|
| Netagy |
| Pyrami |
| Quility |
Limit
指定要检索的文档的最大数量。用于防止将大量数据提取到内存中。
示例 1:如果传入单个参数,它映射到 UDB-SX 中的 size 参数,from 参数设置为 0。
SELECT account_number
FROM accounts
ORDER BY account_number LIMIT 1
| account_number |
|---|
| 1 |
示例 2:如果传入两个参数,第一个映射到 UDB-SX 中的 from 参数,第二个映射到 size 参数。您可以将其用于小型索引的简单分页,因为它对于大型索引效率低下。
使用 ORDER BY 确保页面之间的顺序相同:
SELECT account_number
FROM accounts
ORDER BY account_number LIMIT 1, 1
| account_number |
|---|
| 6 |