标准化处理器
normalization-processor 是一个搜索阶段结果处理器,在搜索执行的查询阶段和提取阶段之间运行。它拦截查询阶段结果,然后在将文档传递给提取阶段之前,对不同查询子句的文档分数进行标准化和合并。
分数标准化与合并
许多应用程序同时需要关键词匹配和语义理解。例如,对于包含关键词的查询,BM25 能准确提供相关的搜索结果;而当查询需要自然语言理解时,神经网络表现良好。因此,您可能希望将 BM25 搜索结果与 k-NN 或神经搜索结果相结合。然而,BM25 和 k-NN 搜索使用不同的尺度来计算匹配文档的相关性分数。在合并来自多个查询的分数之前,对其进行标准化,使其处于同一尺度是有益的,实验数据也证明了这一点。关于分数标准化与合并的进一步阅读,包括基准测试和各种技术,请参阅这篇语义搜索博客文章(文章联系售前工作人员获取)。
先查询后提取
UDB-SX 支持两种搜索类型:query_then_fetch 和 dfs_query_then_fetch。下图概述了先查询后提取的过程,其中包括一个标准化处理器。
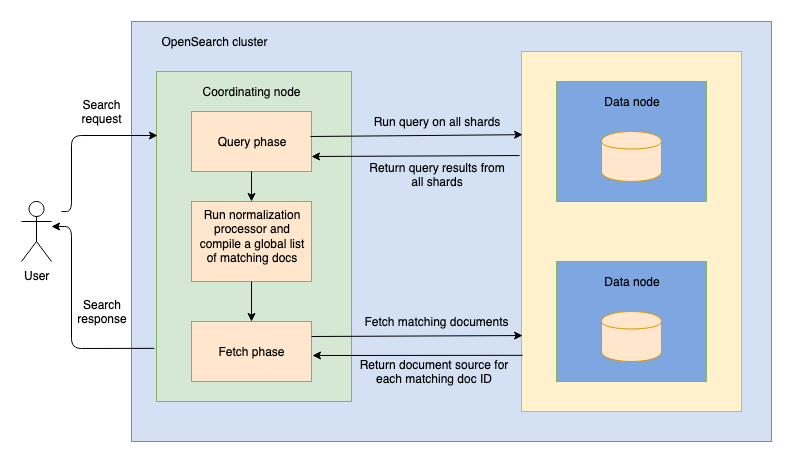
当您向一个节点发送搜索请求时,该节点成为协调节点。在搜索的第一阶段,即查询阶段,协调节点将搜索请求路由到索引中的所有分片,包括主分片和副本分片。然后每个分片在本地运行搜索查询,并返回匹配文档的元数据,其中包括它们的文档 ID 和相关性分数。接着,normalization-processor 对不同查询子句的分数进行标准化和合并。协调节点合并并排序本地的结果列表,编译一个与查询匹配的全局顶级文档列表。此后,搜索执行进入提取阶段,协调节点从文档所在的分片请求全局列表中的文档。每个分片将文档的 _source 返回给协调节点。最后,协调节点向您发送包含结果的搜索响应。
请求正文字段
下表列出了所有可用的请求字段。
| 字段 | 数据类型 | 描述 |
|---|---|---|
normalization.technique |
字符串 | 分数标准化的技术。有效值为 min_max 和 l2。可选。默认为 min_max。 |
combination.technique |
字符串 | 分数合并的技术。有效值为 arithmetic_mean、geometric_mean 和 harmonic_mean。可选。默认为 arithmetic_mean。 |
combination.parameters.weights |
浮点值数组 | 指定每个查询使用的权重。有效值在 [0.0, 1.0] 范围内,表示小数百分比。权重越接近 1.0,查询的权重越大。weights 数组中的值的数量必须等于查询的数量。数组中值的总和必须等于 1.0。可选。如果未提供,则所有查询具有相同的权重。 |
tag |
字符串 | 处理器的标识符。可选。 |
description |
字符串 | 处理器的描述。可选。 |
ignore_failure |
布尔值 | 对于此处理器,该值被忽略。如果处理器失败,管道总是失败并返回错误。 |
示例
以下示例演示了使用带有 normalization-processor 的搜索管道。
创建搜索管道
以下请求创建一个包含 normalization-processor 的搜索管道,该处理器使用 min_max 标准化技术和 arithmetic_mean 合并技术:
PUT /_search/pipeline/nlp-search-pipeline
{
"description": "用于混合搜索的后置处理器",
"phase_results_processors": [
{
"normalization-processor": {
"normalization": {
"technique": "min_max"
},
"combination": {
"technique": "arithmetic_mean",
"parameters": {
"weights": [
0.3,
0.7
]
}
}
}
}
]
}
使用搜索管道
在 hybrid 查询中提供您想要合并的查询子句,并应用上一节创建的搜索管道,以便使用选定的技术合并分数:
GET /my-nlp-index/_search?search_pipeline=nlp-search-pipeline
{
"_source": {
"exclude": [
"passage_embedding"
]
},
"query": {
"hybrid": {
"queries": [
{
"match": {
"text": {
"query": "horse"
}
}
},
{
"neural": {
"passage_embedding": {
"query_text": "wild west",
"model_id": "aVeif4oB5Vm0Tdw8zYO2",
"k": 5
}
}
}
]
}
}
}
有关设置混合搜索的更多信息,请参阅混合搜索。
搜索调优建议
为了提高搜索相关性,我们建议增加样本大小。
如果混合查询没有返回某些预期结果,可能是因为子查询返回的文档太少。normalization-processor 仅转换每个子查询返回的结果;它不执行任何额外的采样。在我们的实验中,我们使用 nDCG@10 来衡量信息检索的质量,这取决于返回的文档数量(大小)。我们发现,对于多达 1000 万文档的数据集,大小在 [100, 200] 范围内效果最佳。我们不建议将大小增加到超出推荐值,因为更高的值不会提高搜索相关性,但会增加搜索延迟。