星形树索引
此为实验性功能,不建议在生产环境中使用。如需了解该功能的最新进展或提供反馈,请加入 UDB-SX 论坛(论坛信息请联系售前工作人员获取) 的讨论。
星形树索引是一种多字段索引,旨在提升聚合查询的性能。
如果查询的字段属于维度字段的一部分,且聚合操作是在星形树指标字段上执行的,UDB-SX 将自动使用星形树索引来优化聚合。这不需要对查询语法或请求参数进行任何更改。
何时使用星形树索引
星形树索引可用于执行更快的聚合操作。在决定使用星形树索引时,请考虑以下标准和特性:
星形树索引原生支持多字段聚合。
星形树索引作为索引过程的一部分实时创建,因此星形树中的数据始终是最新的。
星形树索引整合数据,提高了索引分页效率,并在搜索查询中减少了 IO 使用。
限制
星形树索引存在以下限制:
星形树索引应仅用于数据不会被更新或删除的索引,因为更新和删除操作不会在星形树索引中体现。要强制执行此策略并使用星形树索引,请将
index.append_only.enabled设置设为true。只有当查询字段是星形树维度的子集,且聚合字段是星形树指标的子集时,星形树索引才能用于聚合查询。
星形树索引一旦启用,便无法禁用。要禁用星形树索引,必须在不使用星形树映射的情况下重新索引该索引中的数据。此外,更改星形树配置也需要重新索引操作。
不支持 多值/数组值。
仅支持 有限的查询和聚合类型。更多功能将在未来版本中添加。
维度的基数不应非常高(例如
_id字段)。基数过高会导致存储使用量增加和查询延迟升高。
星形树索引结构
下图展示了一个标准的星形树索引结构。
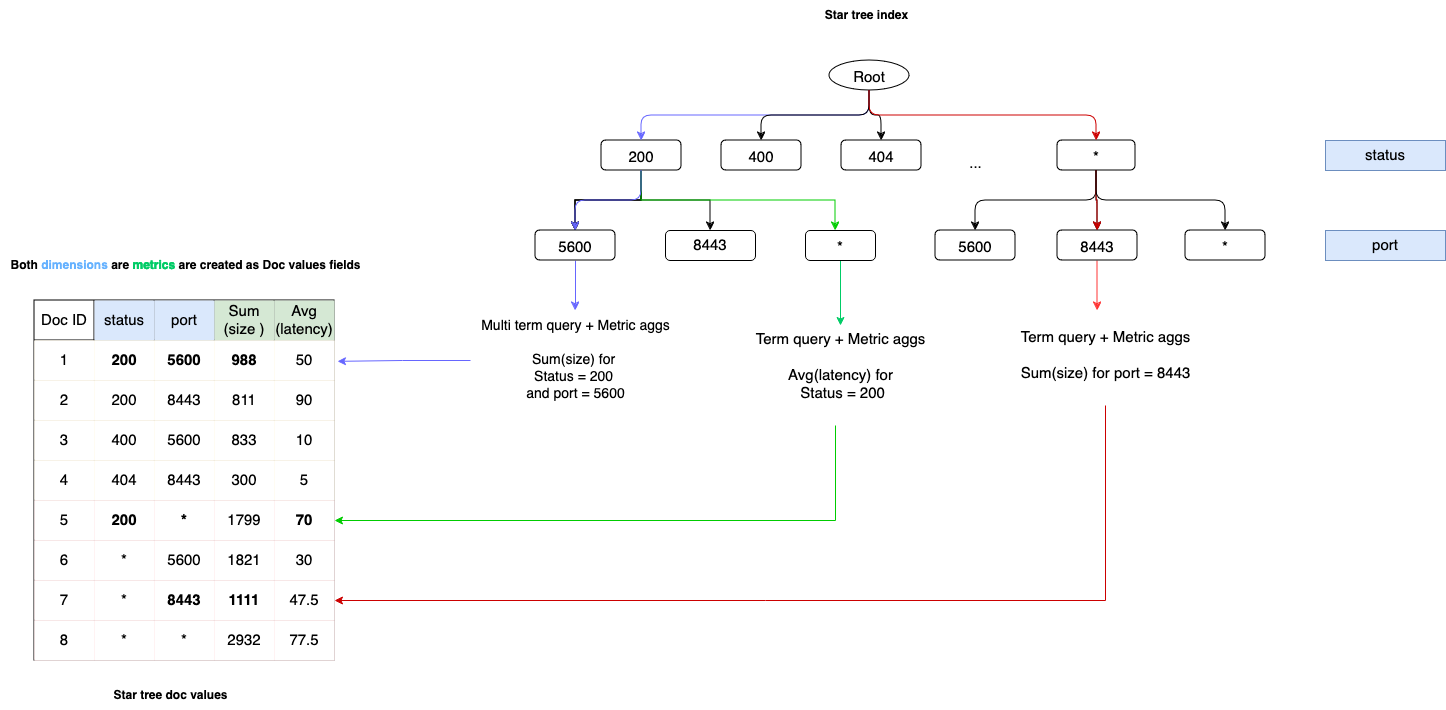
经过排序和聚合的星形树文档由索引中的 doc_values 支持。doc_values 中的列式数据使用以下属性存储:
这些值根据
ordered_dimension设置中指定的字段进行排序。在上图中,维度首先由status设置决定,然后是每个状态下的port。对于每个唯一的维度/值组合,所有指标(如
avg(size)和count(requests))的聚合值都会在数据摄取期间预先计算好。
叶节点
星形树索引中的每个节点指向一个星形树文档的范围。节点可以根据 max_leaf_docs 配置 进一步拆分为子节点。一个叶节点指向的文档数量小于或等于 max_leaf_docs 中设置的值。这确保了为推导聚合值而需要遍历节点的最大文档数最多为 max_leaf_docs 的数量,从而提供了可预测的延迟。
星形节点
星形节点包含特定维度下所有其他节点的聚合数据,充当“统括一切”的节点。当在某个维度中发现星形节点时,聚合过程中将跳过该维度。这将该维度的所有值组合在一起,并允许查询在获取特定字段的聚合值时跳过非竞争性节点。
星形树索引结构图包含了以下三个示例,展示了查询在从星形树节点检索聚合数据时的行为:
蓝色:在一个搜索平均请求大小聚合的
terms查询中,port等于8443,status 等于200。由于查询包含了status和port两个维度的值,查询会遍历 status 节点200,并从其子节点8443返回聚合结果。绿色:在一个搜索聚合请求数量的
term查询中,status等于200。由于查询仅包含status维度的值,查询会遍历200节点的子星形节点,该节点包含了所有port子节点的聚合值。红色:在一个搜索平均请求大小聚合的
term查询中,port 等于5600。由于查询不包含status维度的值,查询会遍历一个星形节点,并从5600子节点返回聚合结果。
对 Terms 查询的支持将在未来版本中添加。更多信息,请参阅 GitHub 问题 #15257(相关问题请联系售前工作人员获取)。
启用星形树索引
要使用星形树索引,请修改以下设置:
将功能标志
opensearch.experimental.feature.composite_index.star_tree.enabled设置为true。有关启用和禁用功能标志的更多信息,请参阅启用实验性功能。将
indices.composite_index.star_tree.enabled设置设为true。有关如何配置 UDB-SX 的说明,请参阅配置设置。在索引创建期间,将
index.composite_index索引设置设为true。在索引创建期间,将
index.append_only.enabled索引设置设为true。确保星形树映射中使用的
dimensions和metrics字段已启用doc_values参数。
示例映射
以下示例中,索引映射定义了星形树配置。星形树索引会预先计算 logs 索引中的聚合。这些聚合是针对 port 和 status 字段索引的所有值组合,在 size 和 latency 字段上计算得出的:
PUT logs
{
"settings": {
"index.number_of_shards": 1,
"index.number_of_replicas": 0,
"index.composite_index": true,
"index.append_only.enabled": true
},
"mappings": {
"composite": {
"request_aggs": {
"type": "star_tree",
"config": {
"date_dimension" : {
"name": "@timestamp",
"calendar_intervals": [
"month",
"day"
]
},
"ordered_dimensions": [
{
"name": "status"
},
{
"name": "port"
},
{
"name": "method"
}
],
"metrics": [
{
"name": "size",
"stats": [
"sum"
]
},
{
"name": "latency",
"stats": [
"avg"
]
}
]
}
}
},
"properties": {
"status": {
"type": "integer"
},
"port": {
"type": "integer"
},
"size": {
"type": "integer"
},
"method" : {
"type": "keyword"
},
"latency": {
"type": "scaled_float",
"scaling_factor": 10
}
}
}
}
支持的查询和聚合
星形树索引可用于优化查询和聚合。
支持的查询
UDB-SX 支持以下查询:
Term 查询
Terms 查询
Match all docs 查询
Range 查询
要将查询与星形树索引一起使用,查询字段必须存在于星形树配置的 ordered_dimensions 部分中。查询还必须与一个支持的聚合配对。没有聚合的查询不能与星形树索引一起使用。目前,不支持对 date 字段的查询,该功能将在后续版本中添加。
支持的聚合
星形树索引支持以下聚合。
指标聚合
UDB-SX 支持以下指标聚合:
[求和]
[最小值]
[最大值]
[值计数]
[平均值]
要将可搜索的聚合与星形树索引一起使用,请确保满足以下先决条件:
字段必须存在于星形树配置的
metrics部分中。指标聚合类型必须是
stats参数的一部分。
以下示例使用 示例映射,获取所有 status=500 的错误日志的 size 字段值的总和:
POST /logs/_search
{
"query": {
"term": {
"status": "500"
}
},
"aggs": {
"sum_size": {
"sum": {
"field": "size"
}
}
}
}
使用星形树索引,结果将从单个聚合文档中检索(因为它遍历了 status=500 节点),而不是扫描所有匹配的文档。这降低了查询延迟。
包含指标聚合的日期直方图
您可以在日历间隔上使用 日期直方图 和指标子聚合。
要使用日期直方图聚合并使其在星形树索引中可搜索,请记住以下要求:
星形树映射配置中的日历间隔可以使用请求的日历字段,也可以使用比请求字段粒度更低的字段。例如,如果聚合使用
month字段,星形树搜索仍然可以使用更低粒度的字段,如day。指标子聚合必须是聚合请求的一部分。
以下示例将日志过滤为仅包含状态码在 200 到 400 之间的日志,并将响应 size 设置为 0,以便仅返回聚合结果。然后,它按日历月对过滤后的日志进行聚合,并计算每个月的请求总 size:
POST /logs/_search
{
"size": 0,
"query": {
"range": {
"status": {
"gte": "200",
"lte": "400"
}
}
},
"aggs": {
"by_month": {
"date_histogram": {
"field": "@timestamp",
"calendar_interval": "month"
},
"aggs": {
"sum_size": {
"sum": {
"field": "size"
}
}
}
}
}
}
不使用星形树索引进行查询
将 indices.composite_index.star_tree.enabled 设置设为 false,可以在不使用星形树索引的情况下运行查询。