Navicat17基础使用
navicat是市面上较为好用的商业版开发,迁移,管理工具。方便易用,功能强大,且支持大多数数据库,包括很多国内外数据品牌。
此文主要以UNVDB数据库的视角展开,再配合PG和MYSQL场景结合实现数据库迁移。
注意:
UNVDB全面兼容PG,所以在NAVICAT中直接以PG驱动连接UNVDB数据库即可。
UNVDB数据迁移工具:
Navicat Premium 不仅具备轻松、便捷的可视化数据查看和编辑功能,还提供强大的高阶功能(如模型、结构同步、协同合作、数据迁移等),这使得Navicat 可以极大地满足 UNVDB 不同用户(初级、进阶和高阶)的全方位需求。接下来,我们将为大家介绍导入/导出、数据传输、数据同步、结构同步、转储和运行SQL或脚本文件。
1.导入/导出向导
导入向导让你从 CSV、TXT、XML、DBF 等格式导入数据到表。你可以将设置保存为一个配置文件以供将来使用或用作设置自动运行任务。若要打开导入向导窗口,请在对象工具栏点击“导入向导”。
【注意】Lite 版只支持导入纯文本格式的文件,例如 TXT、CSV、XML 和 JSON。
【提示】你可以拖拉一个支持格式的文件到表的对象选项卡,或到导航窗格中的一个schema。Navicat 将会自动弹出导入向导窗口。
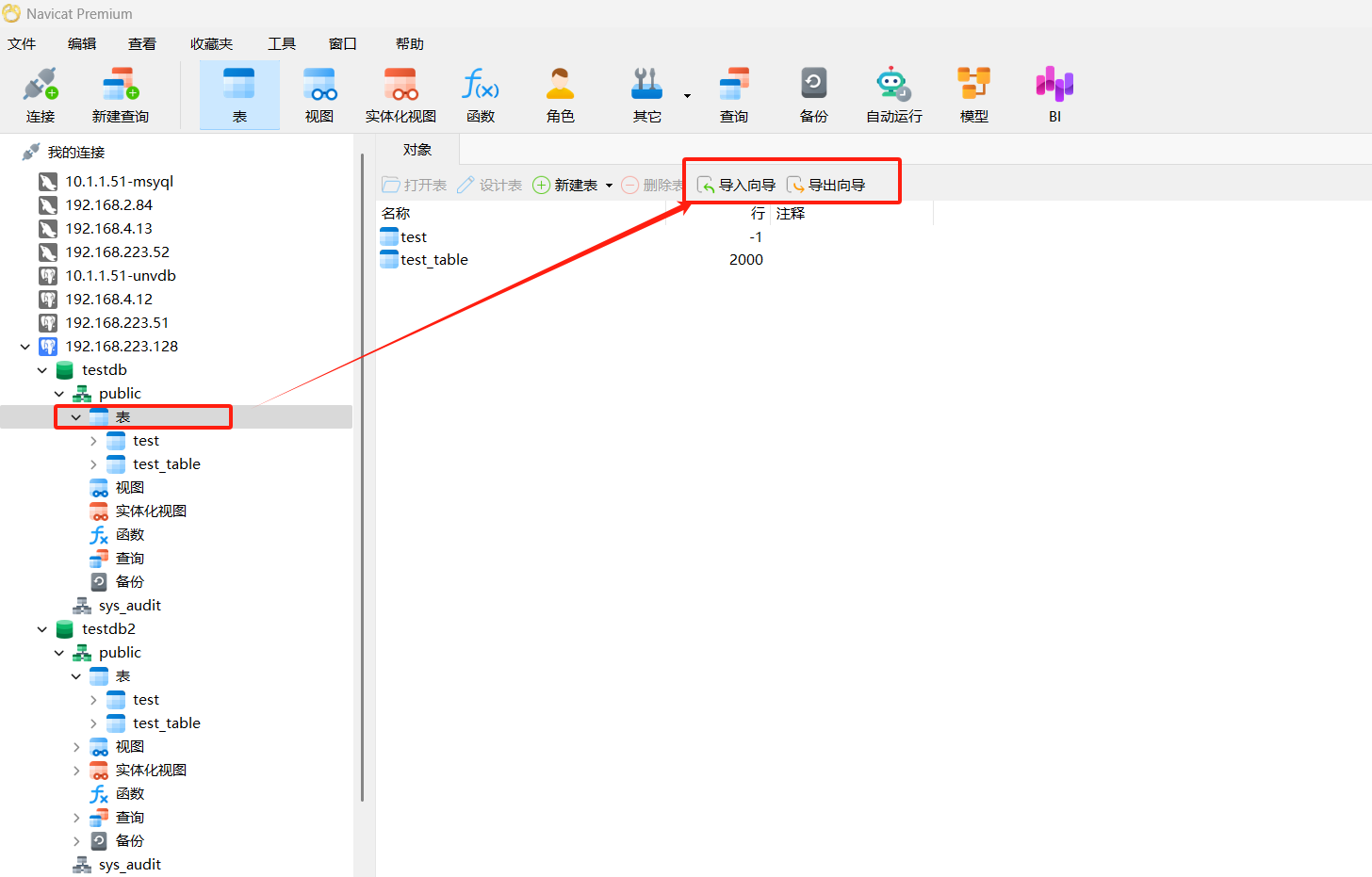
导出向导让你从表、视图或查询结果导出数据到任何可用的格式。你可以将设置保存为一个配置文件以供将来使用或用作设置自动运行任务。若要打开导出向导窗口,请在对象工具栏点击“导出向导”。
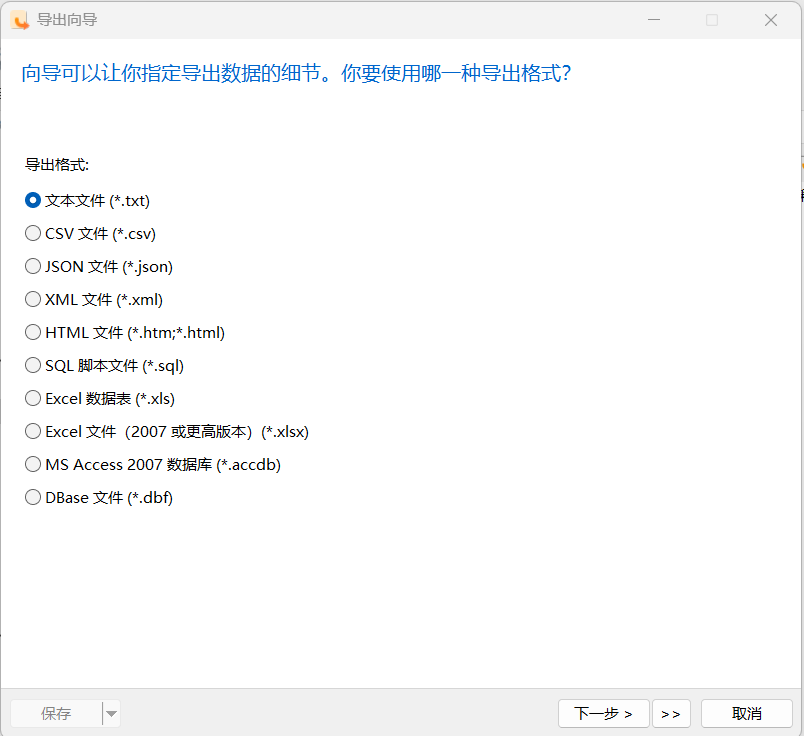
主要如下配置项:
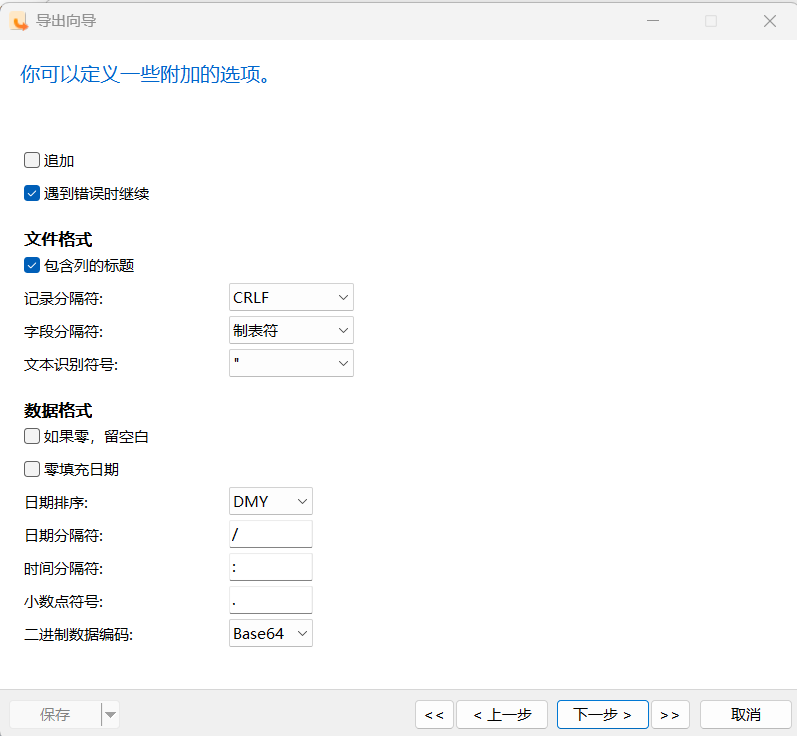
根据需要配置:
追加:主要用于将数据追加到现有文件或表中,而非覆盖原有内容。
记录分隔符:
Navicat从文件导入时记录分隔符代表含义
CR:Carriage Return,对应ASCII中转义字符\r,表示回车 LF:Linefeed,对应ASCII中转义字符\n,表示换行 CRLF:Carriage Return & Linefeed,\r\n,表示回车并换行
字段分隔符:指用于分隔数据库表中不同字段的符号,例如在CSV文件中通常使用逗号(,)作为字段分隔符。也可以用逗号或者制表符作为分隔符。
文本识别符号:文本使用什么符号,有双引号、单引号、none。
数据格式:
如果零,则留空白:当遇到INT类型的”0“,导出的为NULL值。
零填充日期指在导出数据时,若日期字段的值不足两位(如仅输入“1”),系统会自动补足两位(如显示为“01”)。该功能通过“零填充”设置实现,可确保日期格式统一为“YYYY-MM-DD”格式。
2.数据生成
数据生成的目的是依据某个数据模型,从原始数据通过计算得到目标系统所需要的符合该模型的数据。数据生成与数据模型是分不开的,数据生成的结果应该符合某个数据模型对于数据的具体要求。
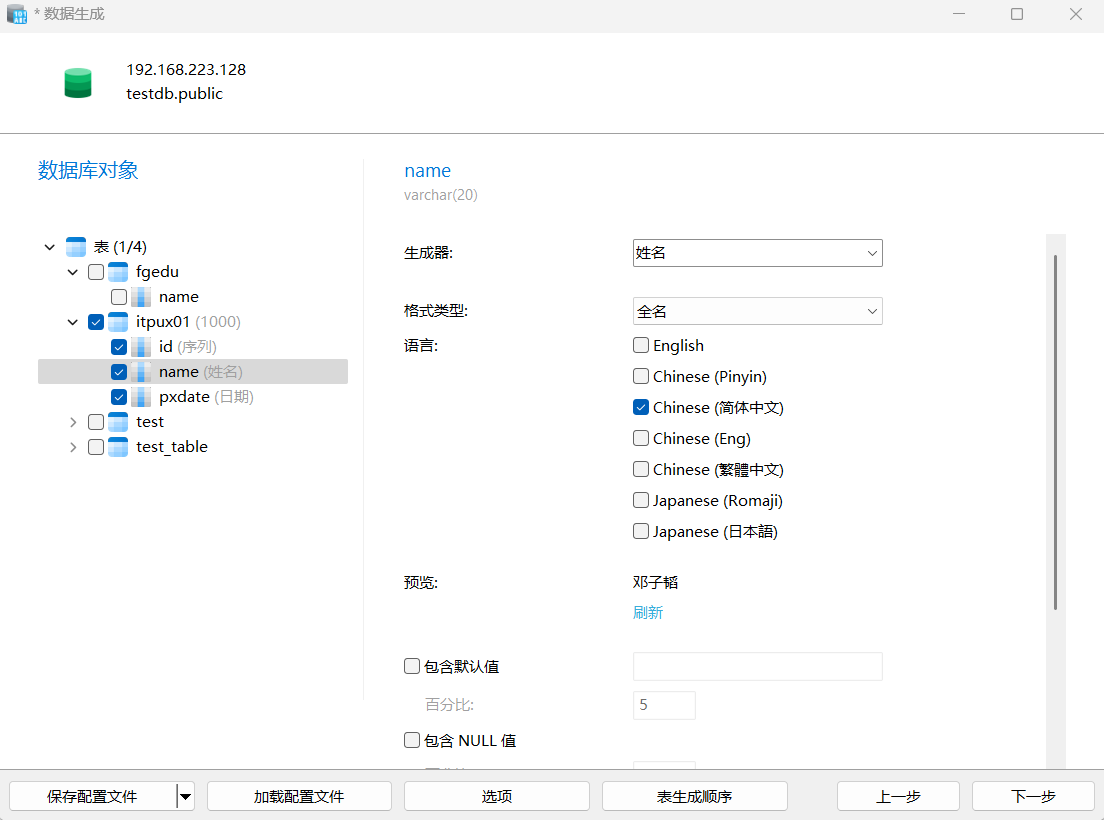
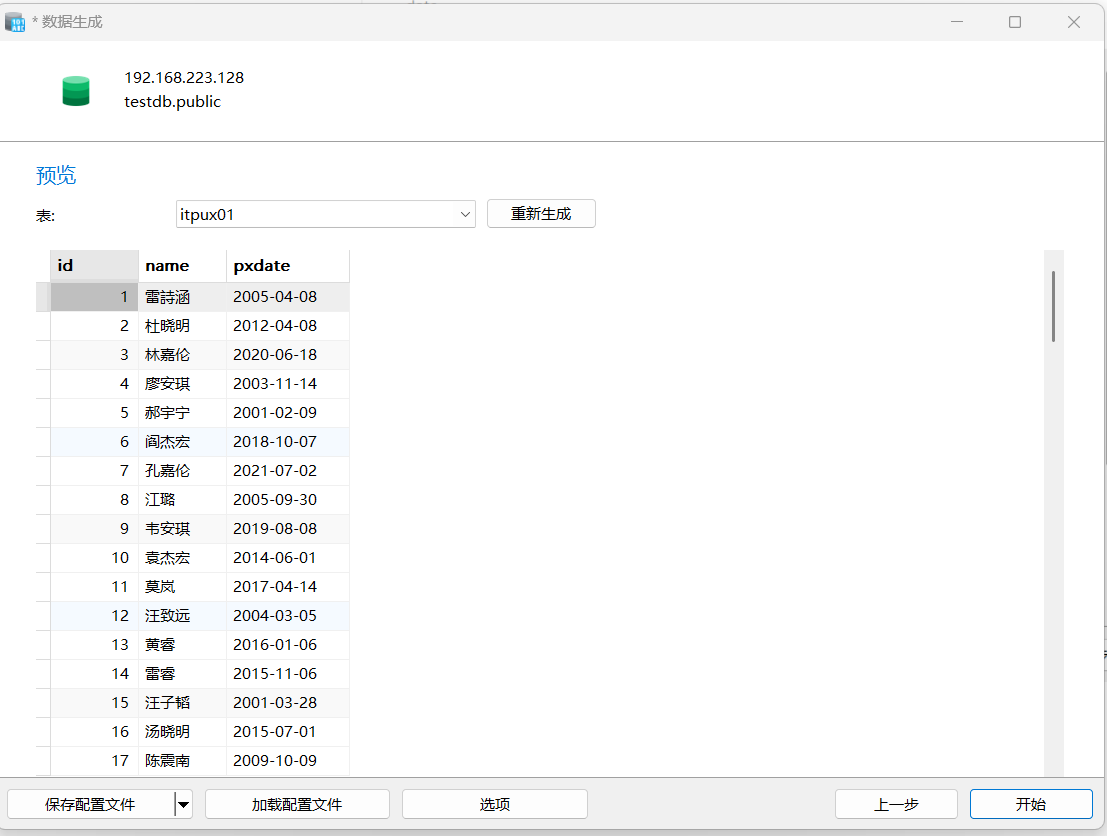
在实际使用中,一般我们新建了一个表结构,要实现模拟数据的插入,就可以使用数据生成功能。
点击“选项”,根据主键的情况选择即可。
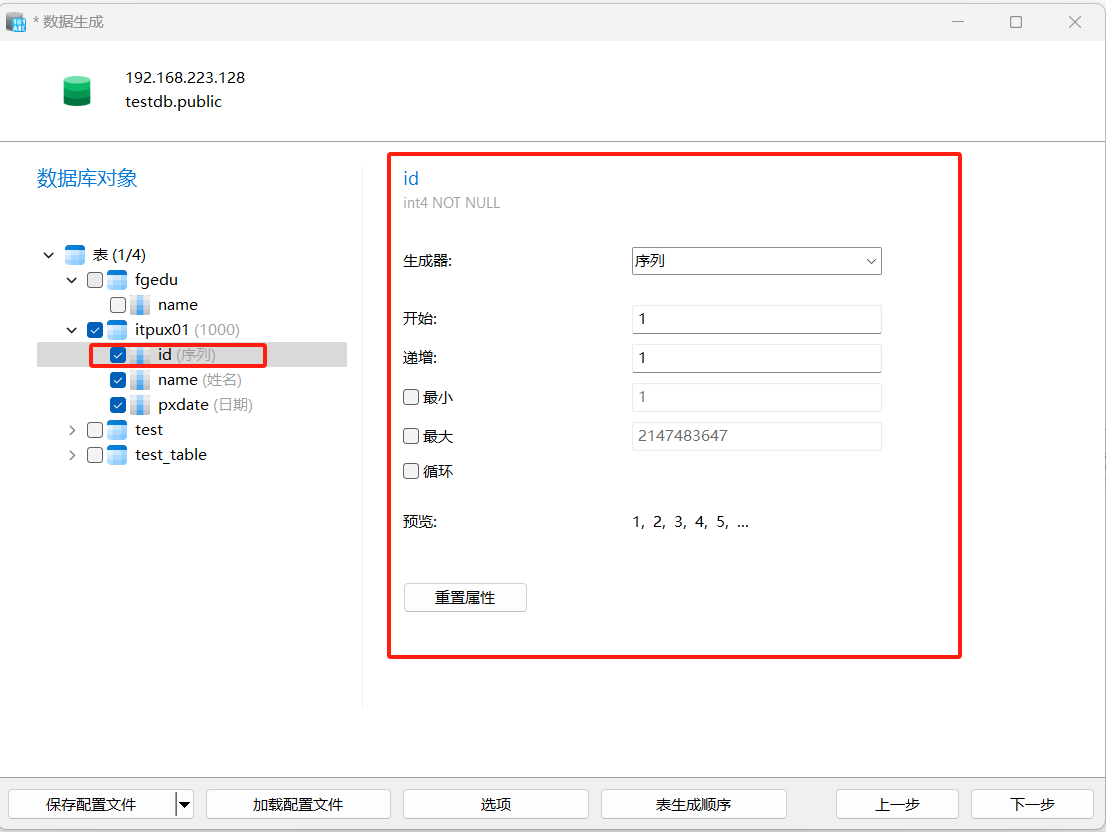
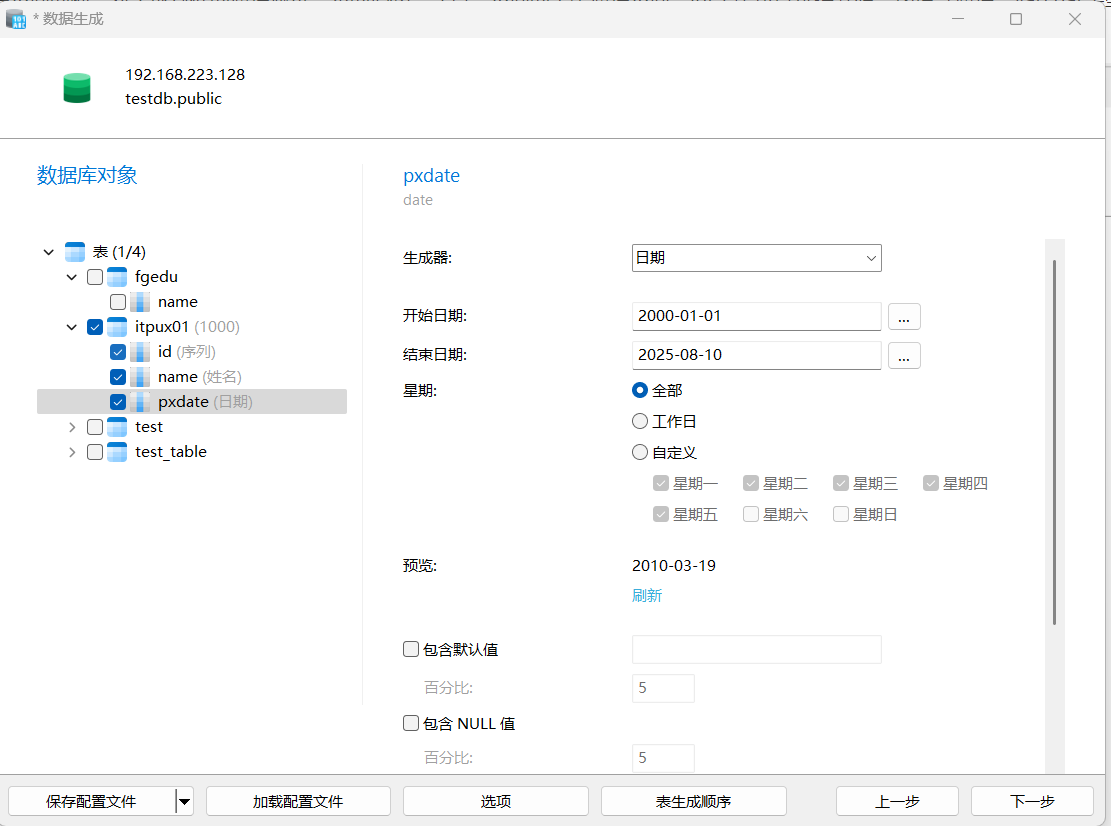
选择不同的列,对生成数据的属性做进一步的调整。注意,不同的类型属性不同,int类型可以选择开始,递增等属性,varchar类型可以选择英文、中文等。具体需要自己根据需要设置。
3. 数据传输
Navicat 让你从一个数据库传输对象到另一个数据库或 SQL 文件。目标数据库可以与源数据库的服务器相同或在其他服务器中。若要打开数据传输窗口,请从菜单栏选择“工具”->“数据传输”。
数据传输优势是可以同构,也可以异构迁移。一般在同构迁移环境中,直接选择源库和目标库,在线迁移即可。如果是异构,则推荐优先导出结构文件,再导出数据文件。这样导出后,我们可以在导出的文件中做二次编辑。经常会出现类型不匹配的情况,需要手动调整。
案例:
使用数据传输功能,将源PG数据库的架构导出到目标库为UNVDB,结构名称为testdb.sql,将数据记录导出到testdb_data.sql。然后利用生成的SQL,在UNVDB中执行。
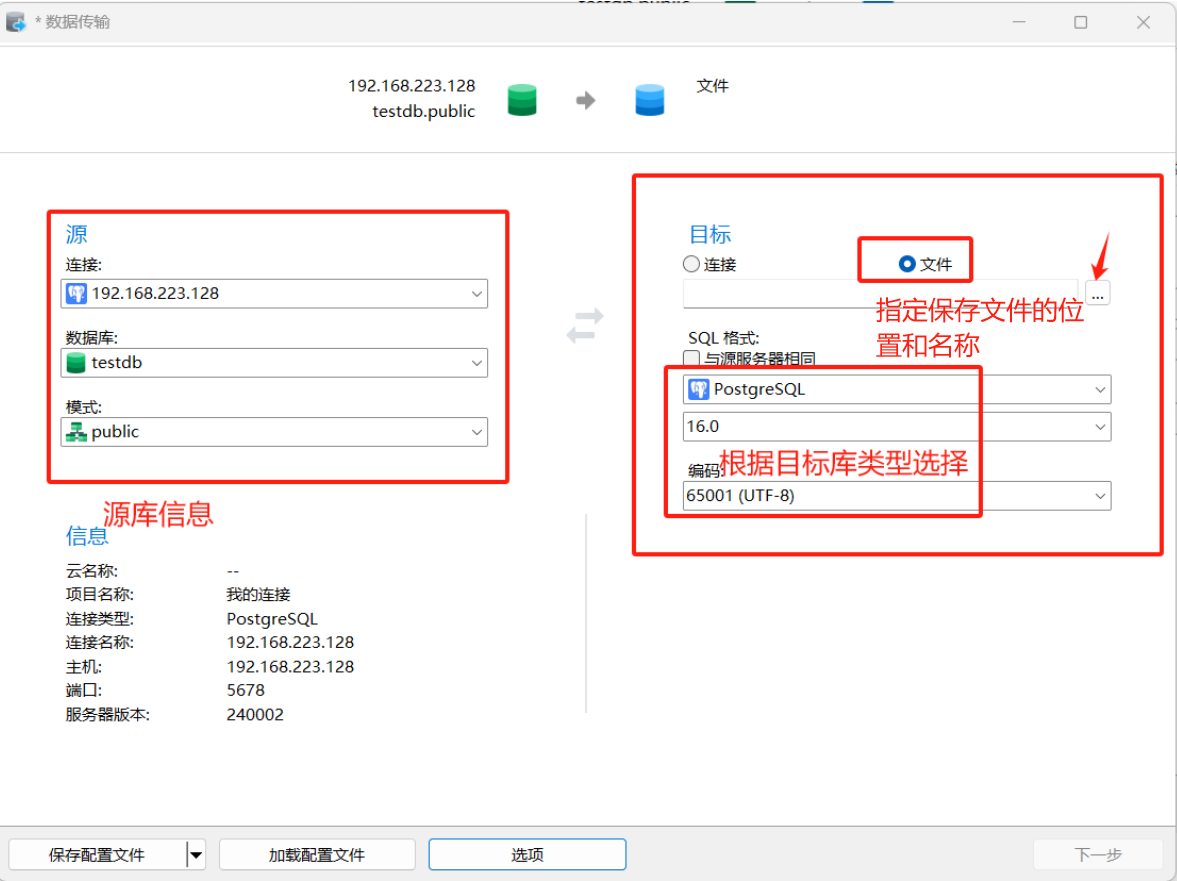
1)结构导出
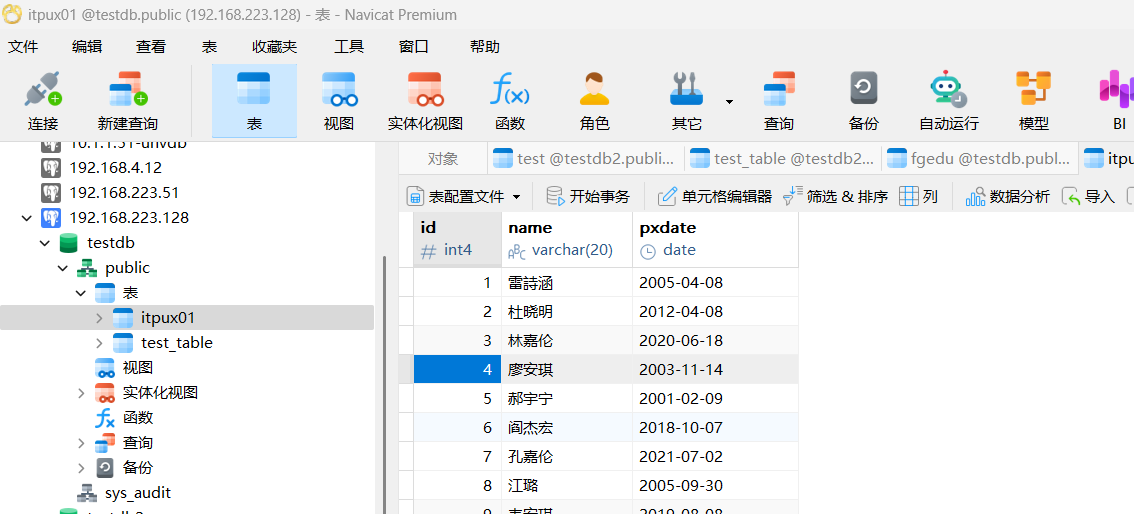
工具-数据传输,填写源库信息,目标选择文件名称和位置
注意:UNVDB兼容PG这里可以选择PG16版本。
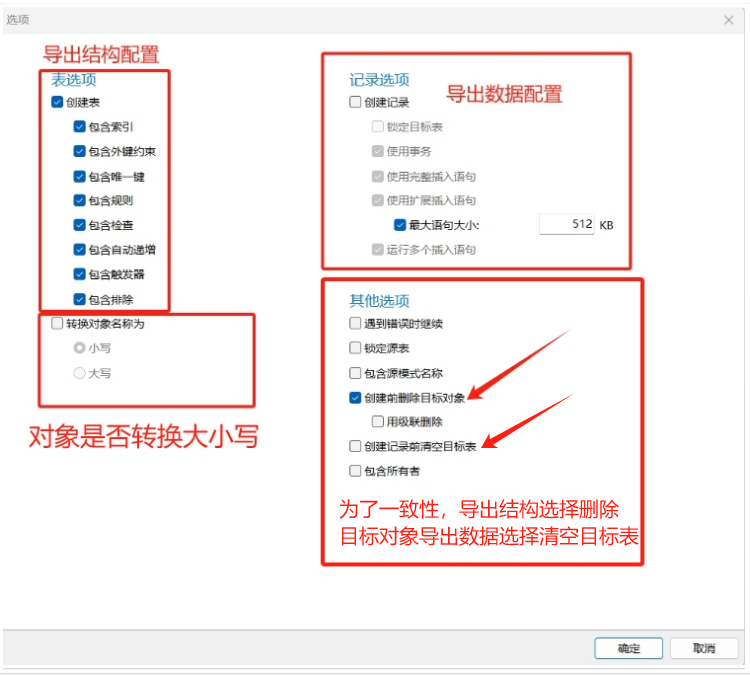
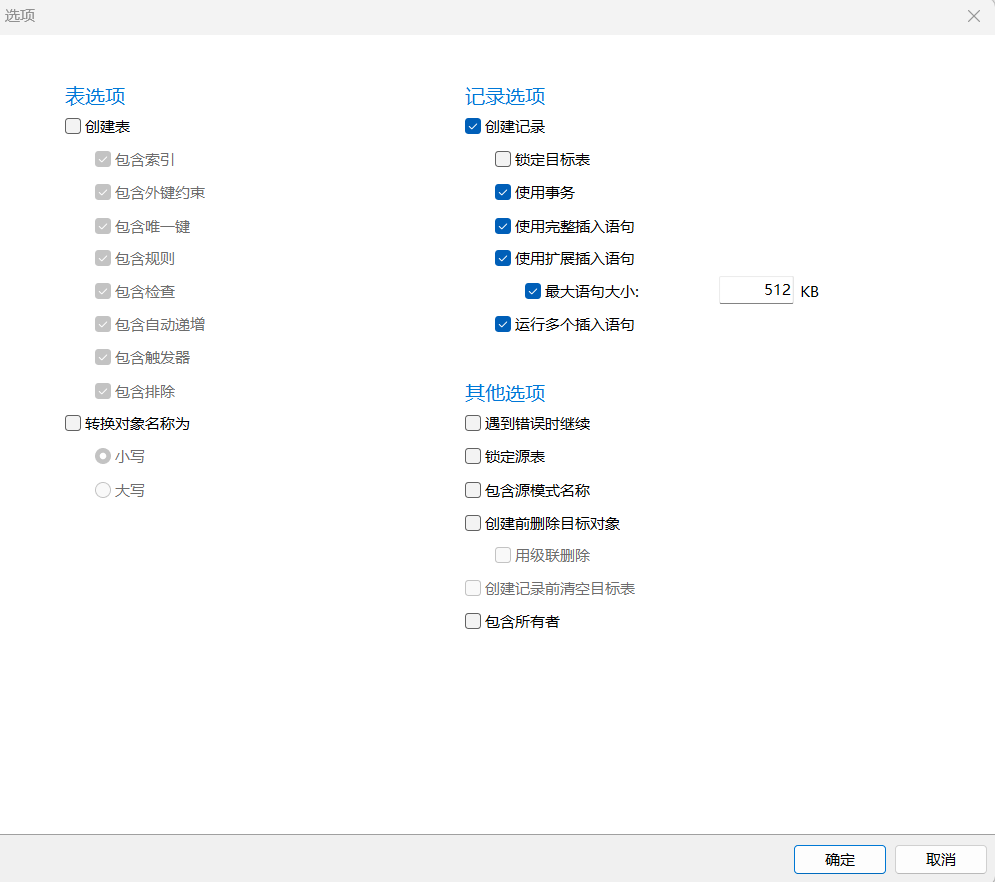
点击“选项”,出现如下图:
注释:
遇到错误时继续:如勾选,则当遇到错误时记录。 锁定源表:一般不用勾选。锁定是为了一致性考虑,只需要保证操作过程中,不要对源表结构变更即可。 包含源模式名称:导出的语句是否包含源模式,一般数据库多模式有对象的情况下,一定要选择。 创建前删除目标对象:为了一致性,如果是导出的结构数据,则建议选择。 用级联删除:删除包含主键值的行的操作,该值由其它表的现有行中的外键列引用。在级联删除中,还删除其外键值引用删除的主键值的所有行。 创建记录前清空目标表:为例一致性,一般在导出数据记录时,则建议选择。 包含所有者:导出对象的所有者信息是否导出,勾选则需要源目标库的user是一致的,不勾选则使用连接的用户作为对象属主。
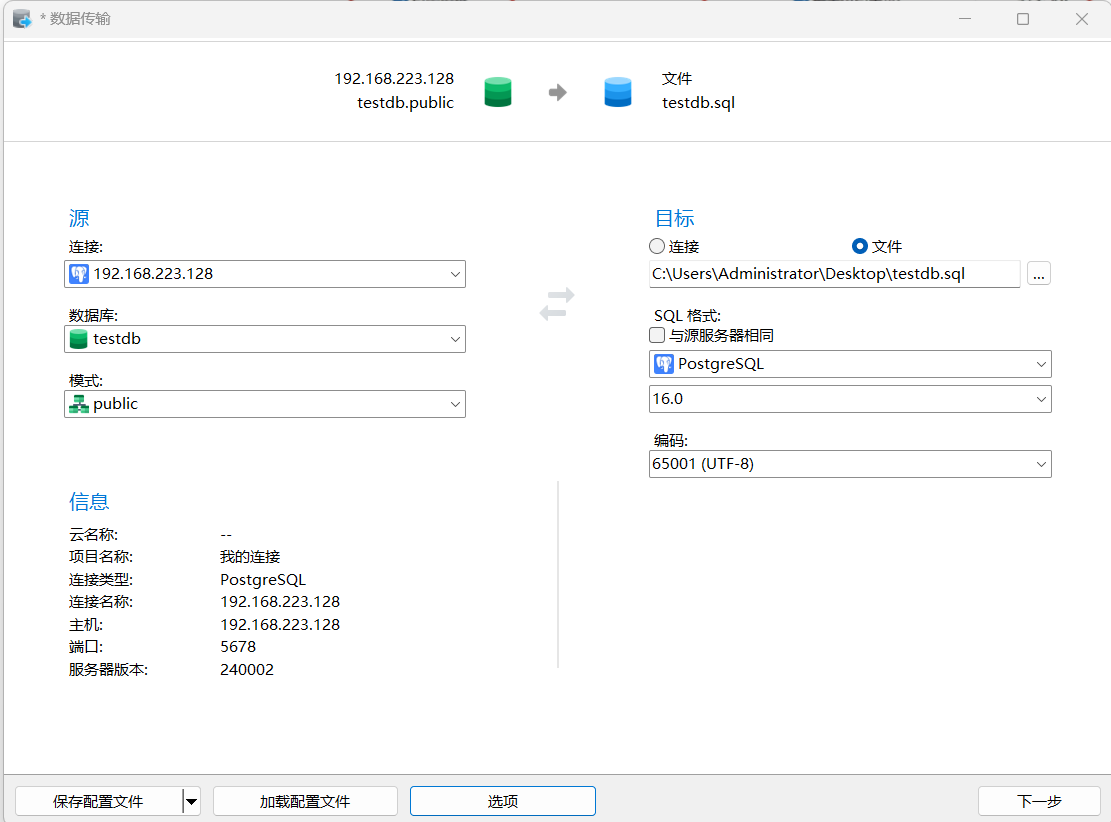
选择类型
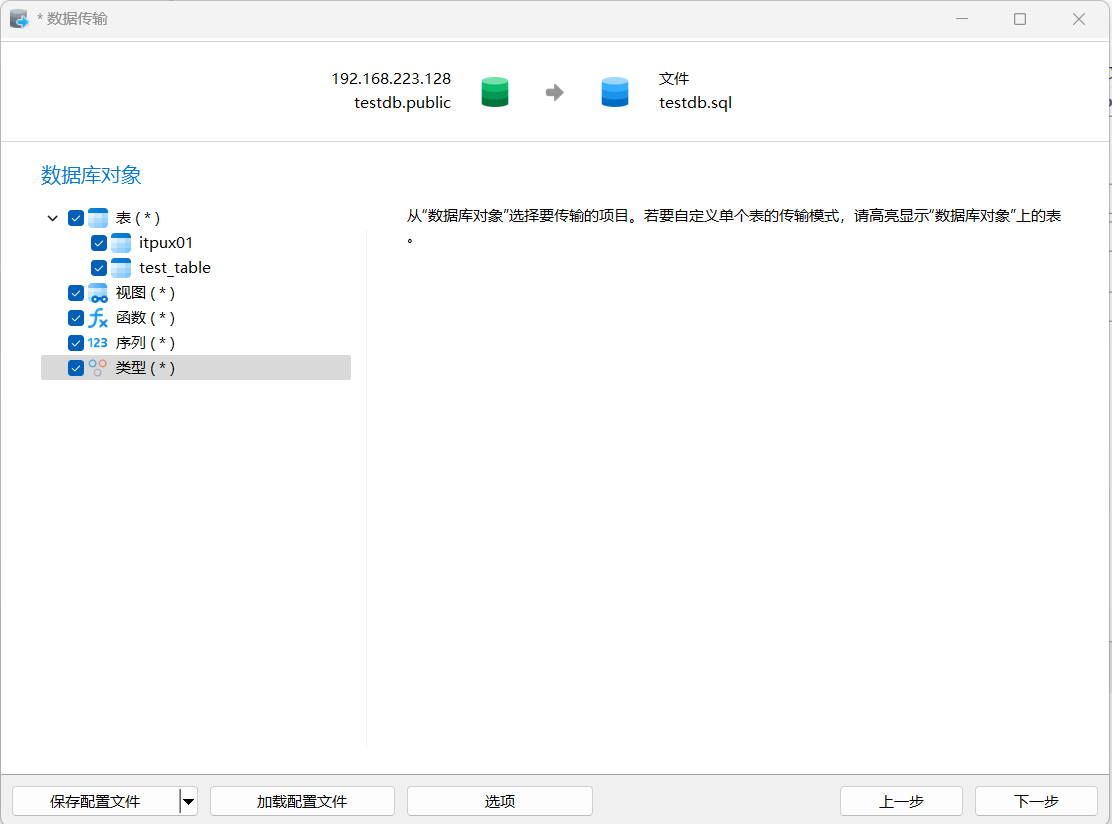
直到最终完成,可以查看目标位置生成的testdb.sql文件。可以发现所有表结构已经都导出了。
/* Navicat Premium Data Transfer
Source Server : 192.168.223.128 Source Server Type : PostgreSQL Source Server Version : 240002 (240002) Source Host : 192.168.223.128:5678 Source Catalog : testdb Source Schema : public
Target Server Type : PostgreSQL Target Server Version : 160000 File Encoding : 65001
Date: 10/08/2025 09:35:19 */
– Table structure for itpux01
DROP TABLE IF EXISTS “itpux01”; CREATE TABLE “itpux01” ( “id” int4 NOT NULL, “name” varchar(20) COLLATE “pg_catalog”.”default”, “pxdate” date ) ;
– Table structure for test_table
DROP TABLE IF EXISTS “test_table”; CREATE TABLE “test_table” ( “id” int4 NOT NULL, “name” varchar(255) COLLATE “pg_catalog”.”default”, “num” int4 ) ;
– Primary Key structure for table itpux01
ALTER TABLE “itpux01” ADD CONSTRAINT “itpux01_pkey” PRIMARY KEY (”id”);
– Primary Key structure for table test_table
ALTER TABLE “test_table” ADD CONSTRAINT “test_table_pkey” PRIMARY KEY (”id”);
2)数据记录导出
工具-数据传输,填写源库信息,目标选择文件名称和位置
注意:UNVDB兼容PG这里可以选择PG16版本。
点击“选项”,出现如下图:
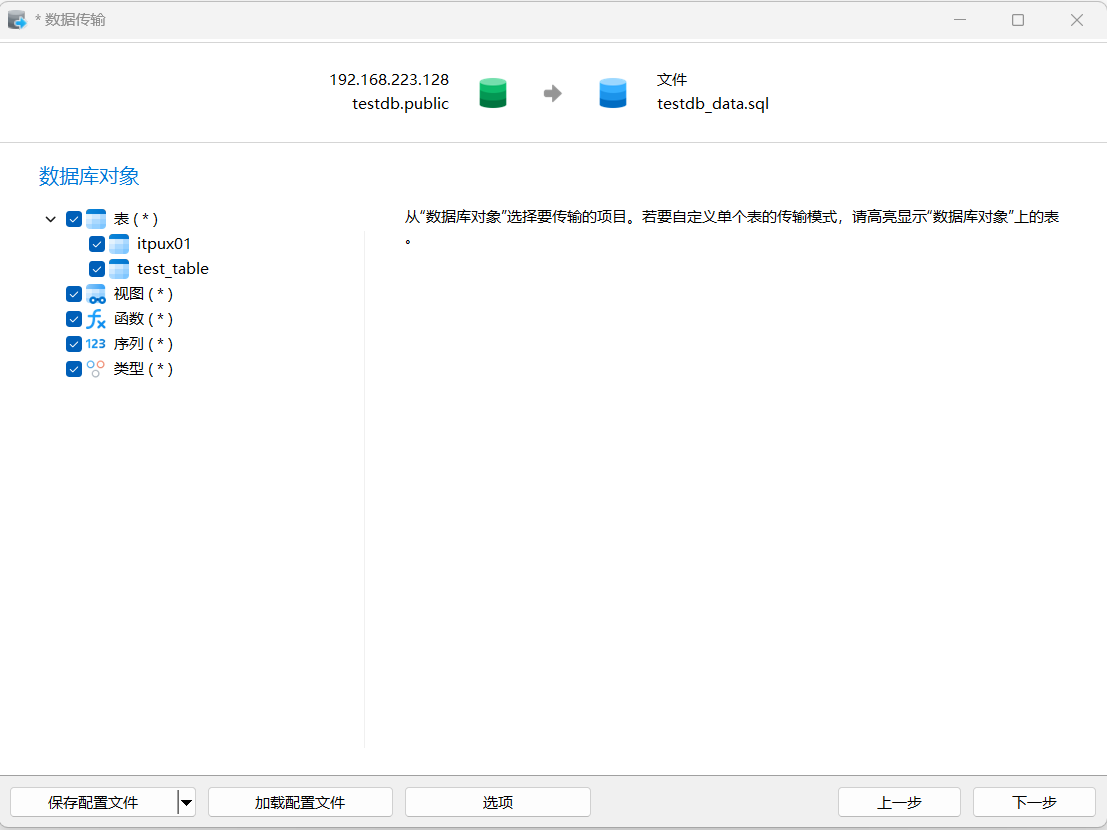
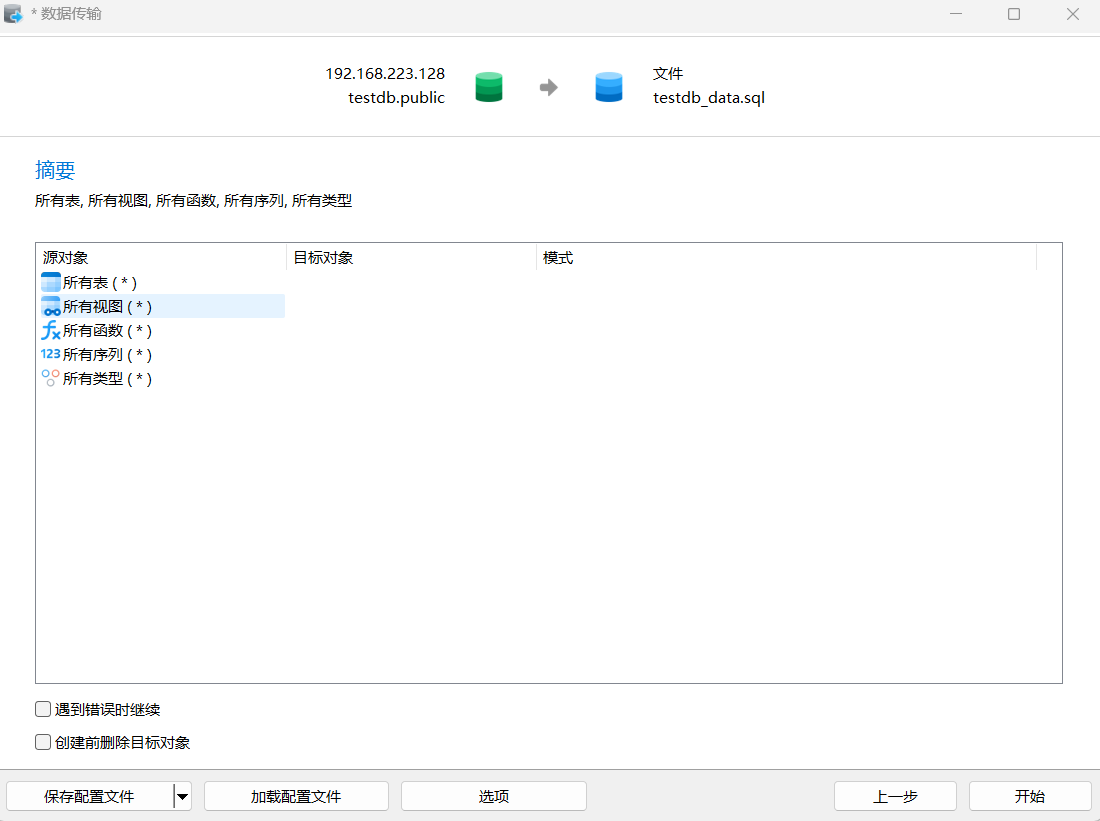
可以查看testdb_data.sql
3)目标数据库结构导入
为了方便,这里我们用同一个数据库服务器(192.168.223.128)的不同数据库testdb2作为目标数据库。最终结果是testdb的数据通过数据传输功能实现了到testdb2的数据迁移效果。
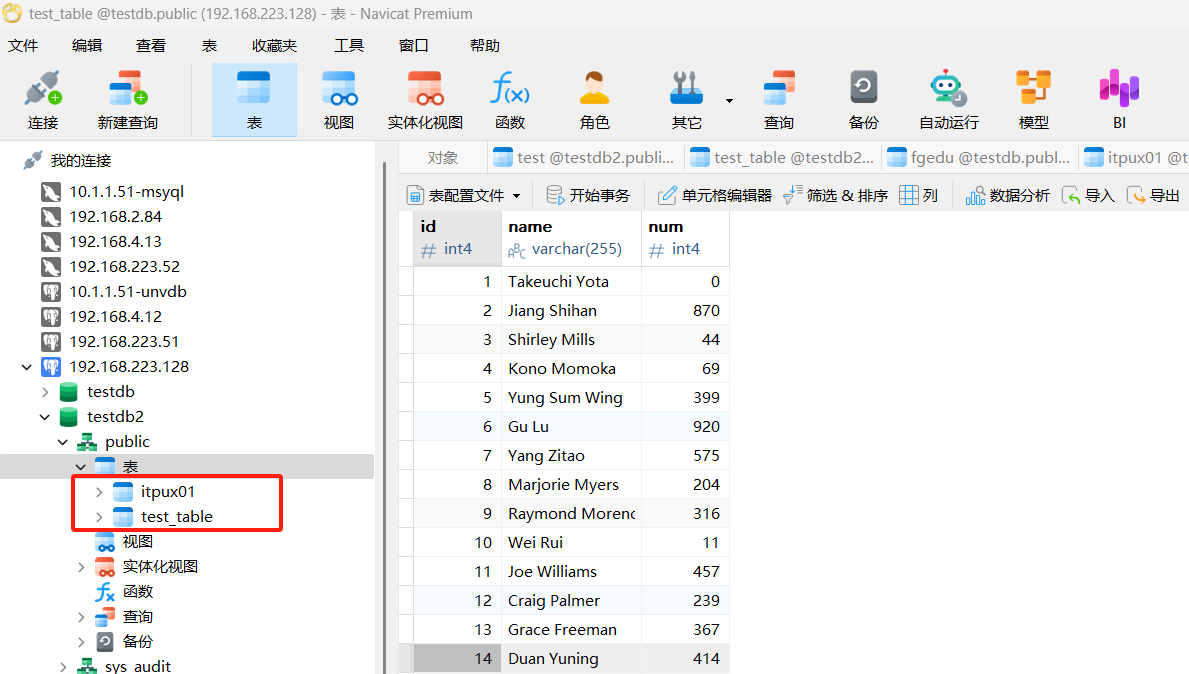
连接数据库-testdb2-右击-运行SQL文件
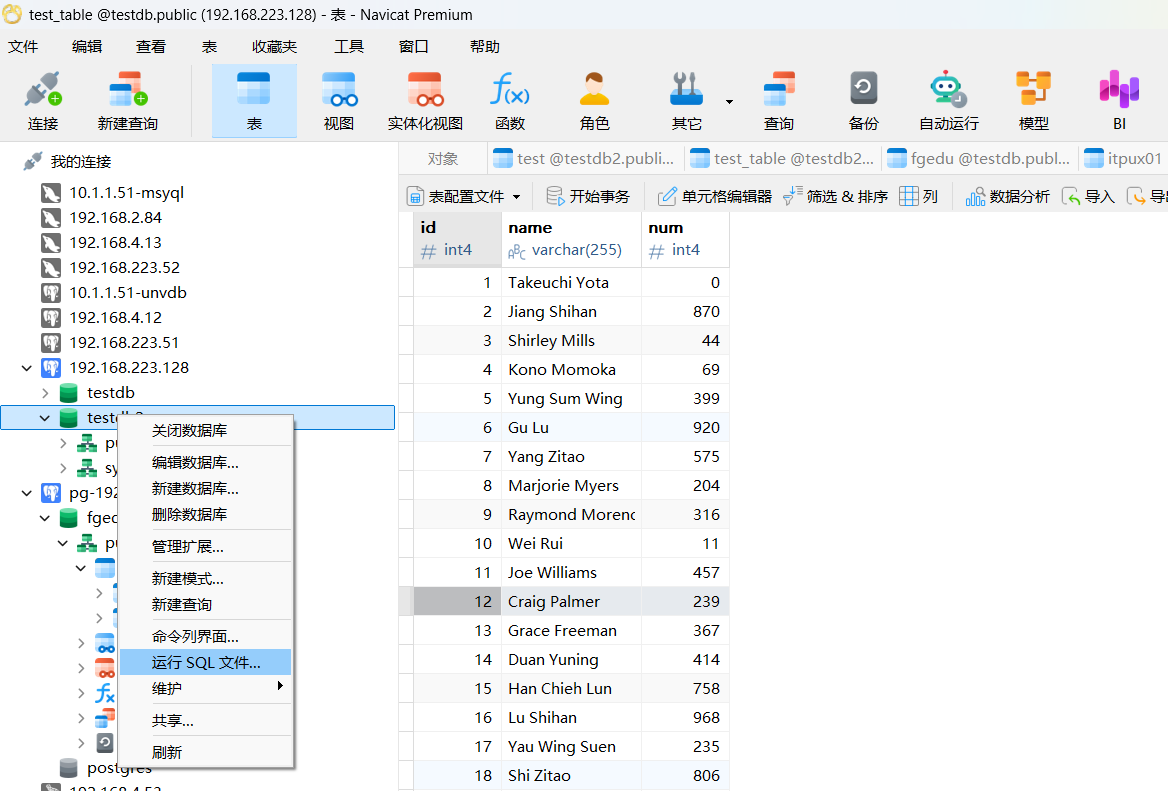
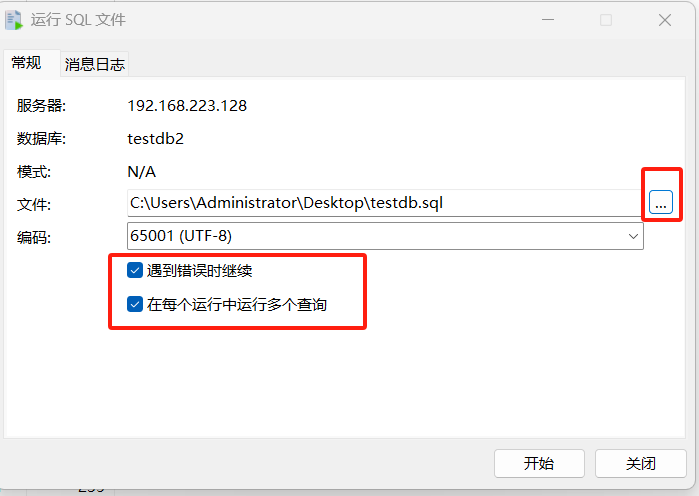
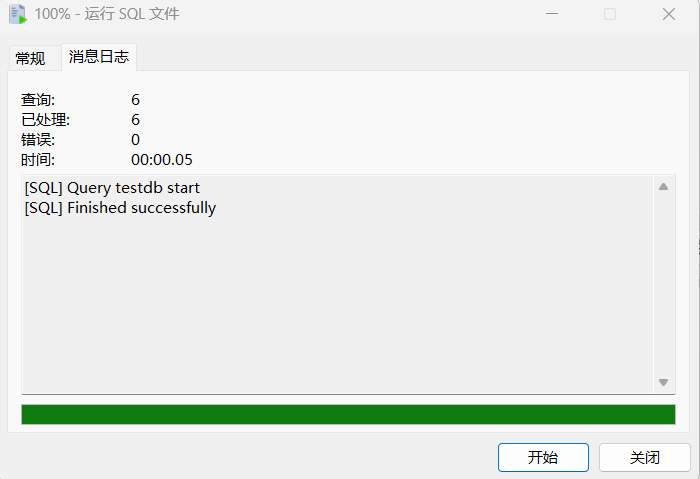
可以看到,相关对象已经生成。
4)数据导入
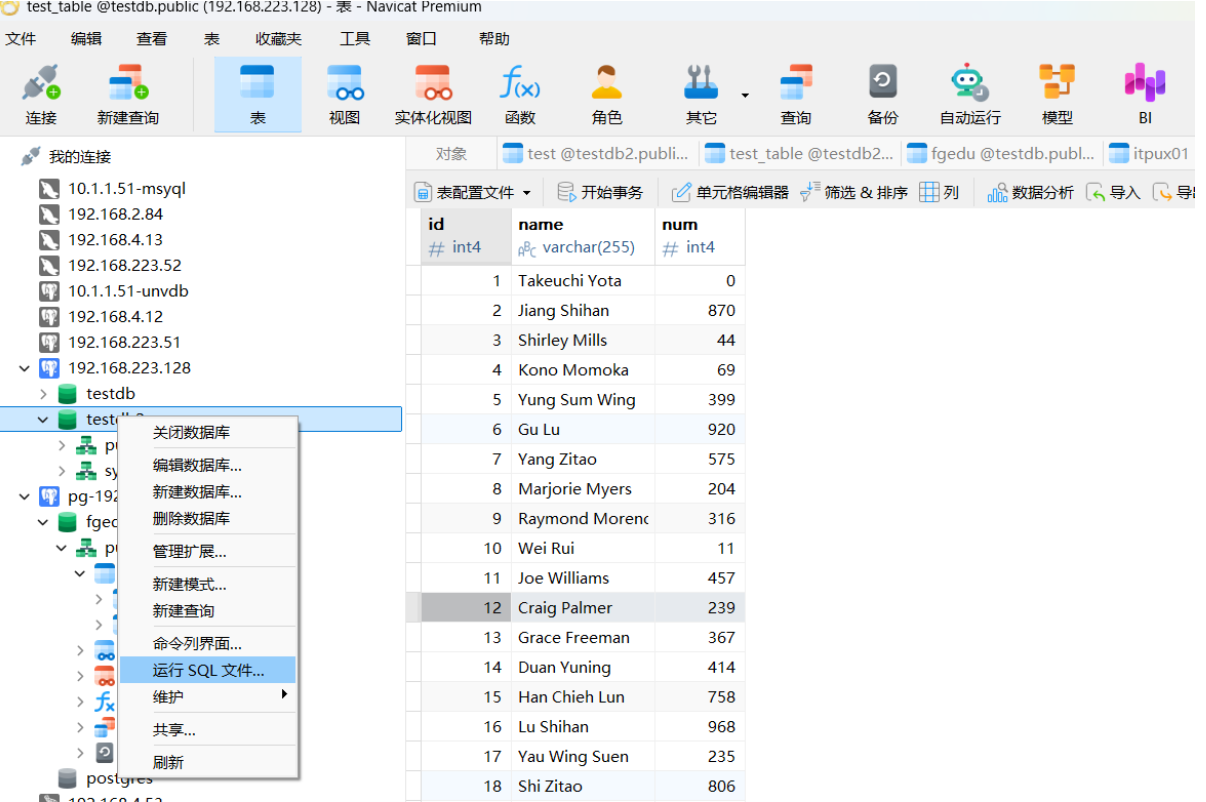
连接数据库-testdb2-右击-运行SQL文件
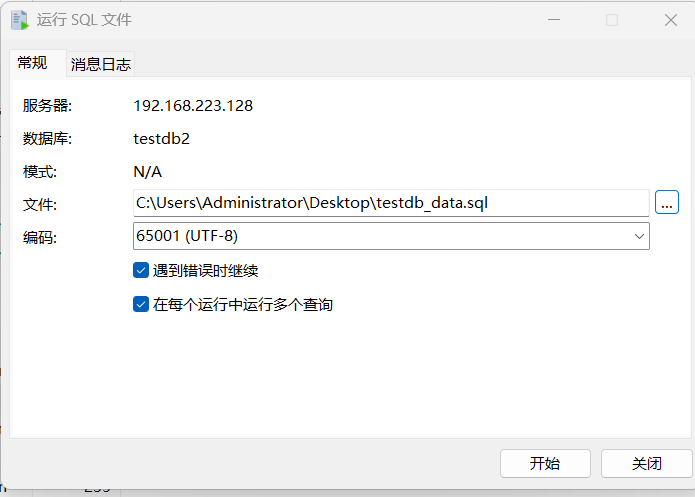
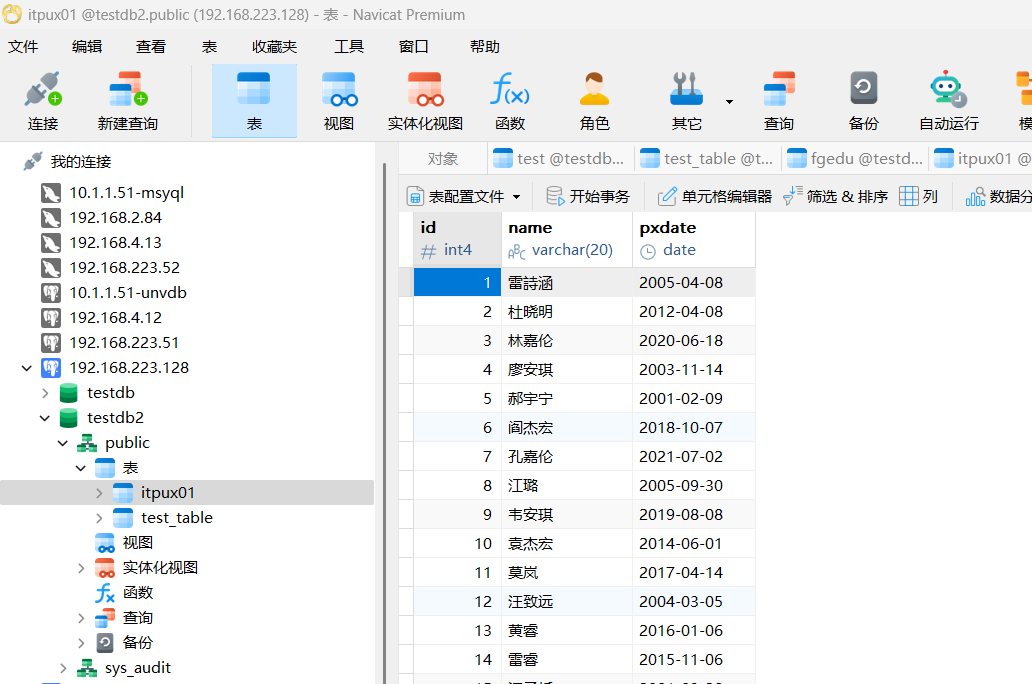
执行后,返现数据记录已经同步。
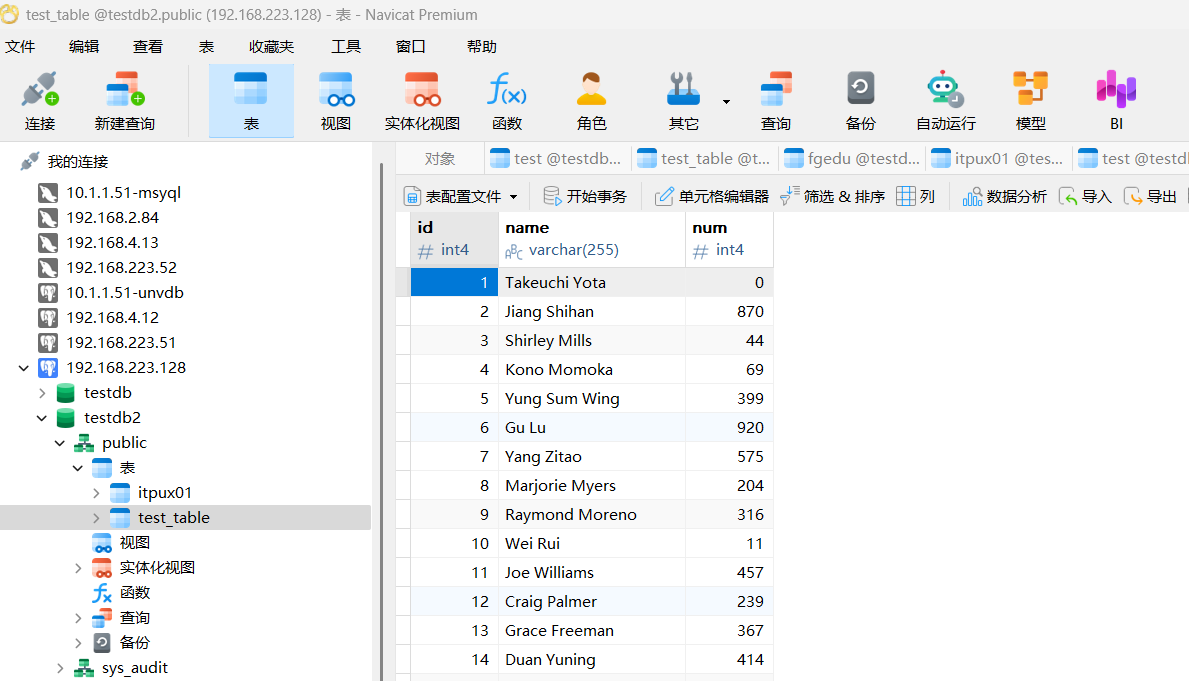
4.结构同步
结构同步是一种高效实现本地库与远程库的结构同步的方法。通过选择结构同步、对比及部署,可以轻松生成并运行对应的语句,是进行版本控制与代码同步的实用工具。但不支持跨数据库类型同步,由于UNVDB和PG的全兼容,二者可以使用Navicat实现结构同步。
注意:
UNVDB系统数据库是unvdb,PG系统数据库为postgres。安全考虑unvdb默认隐藏,postgres没有隐藏,在生产环境中,一定不要使用系统数据库。
结构同步基于表级别选择,不影响已有表。
如果表的属主user两个数据库不同步,可不考虑属主。这样只要连接的用户有权限即可。
演示从PG-UNVDB的表结构同步:
工具-结构同步
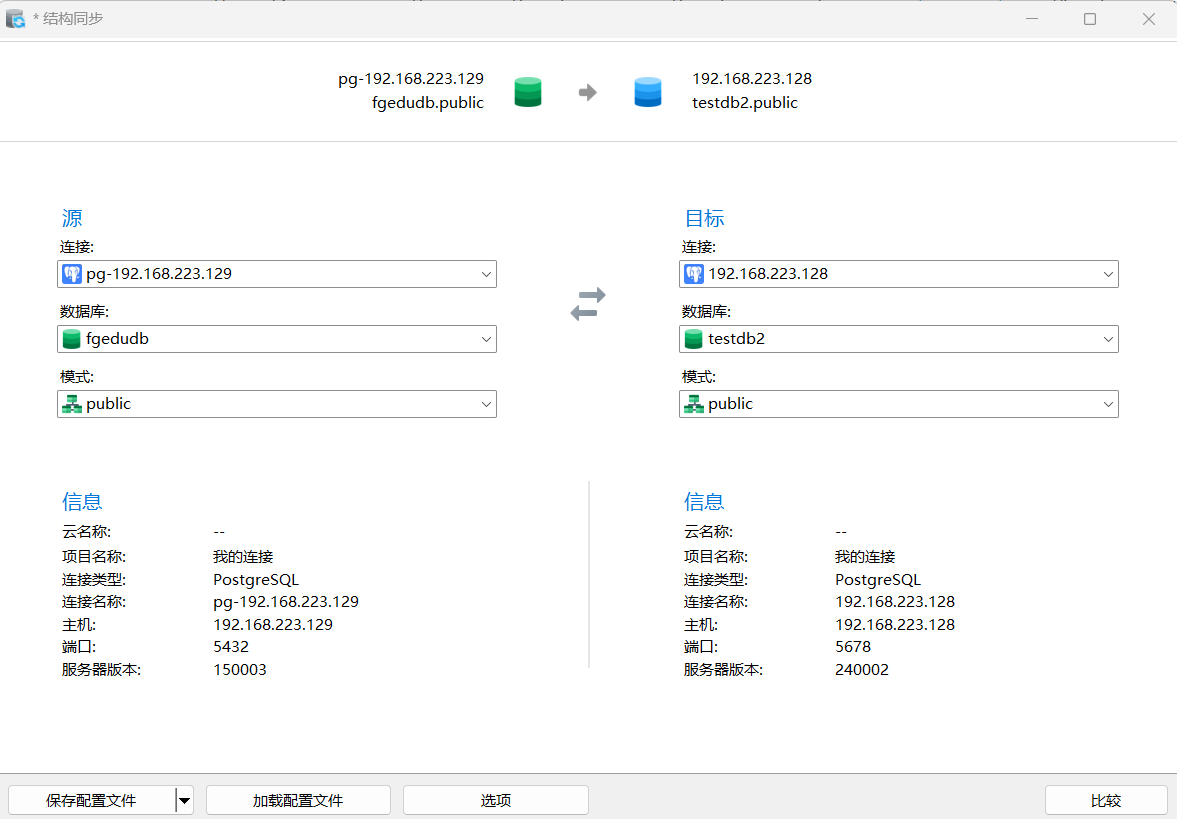
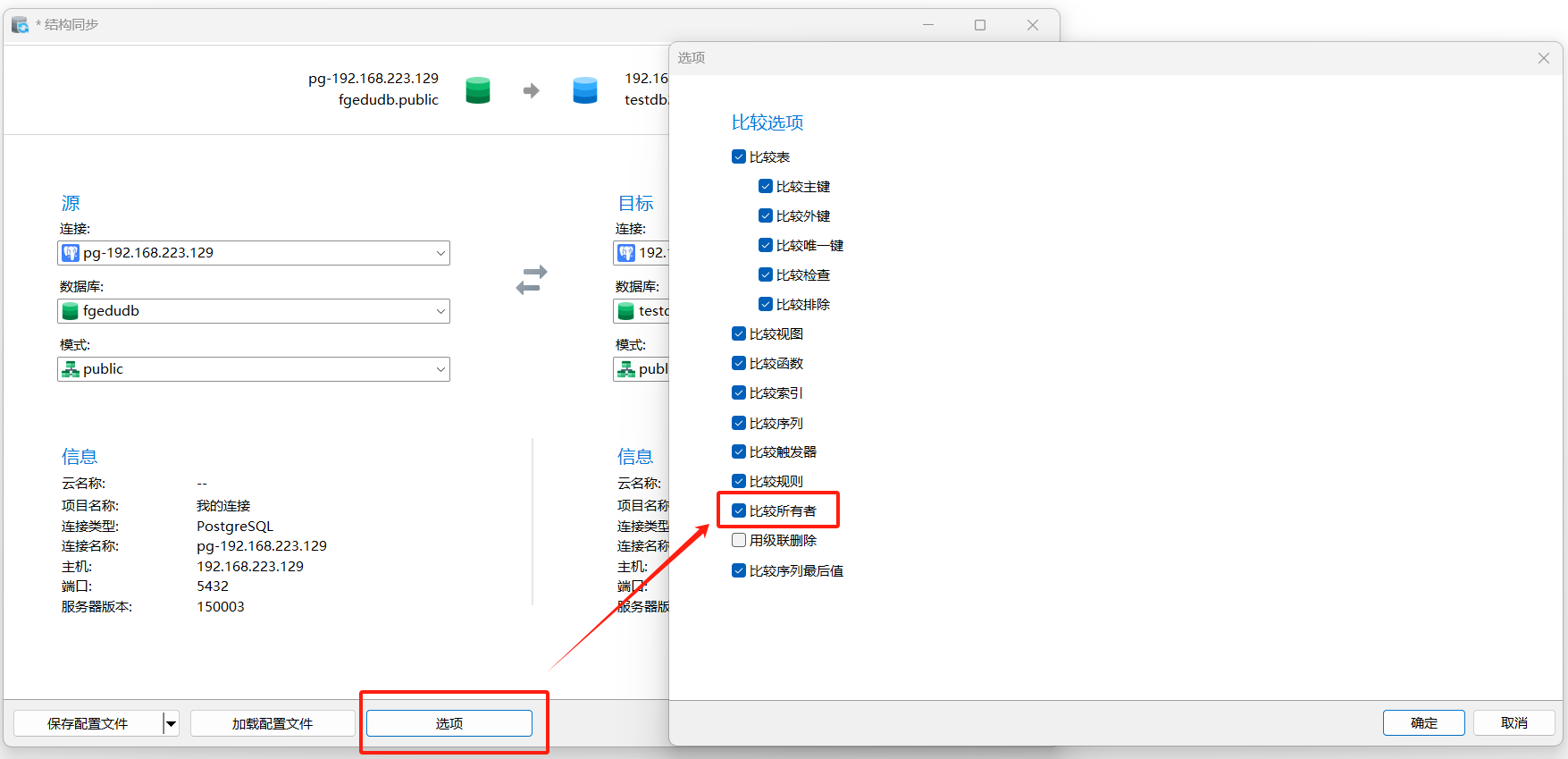
选项-根据情况,勾选相应的选项,两个数据库用户相同,则可以比较所有者,如果用户不同,需要取消勾选,否则后续会报错。
最终影响就是表的属主,勾选则表的属主和源库相同,不勾选,表的属主为连接的用户。
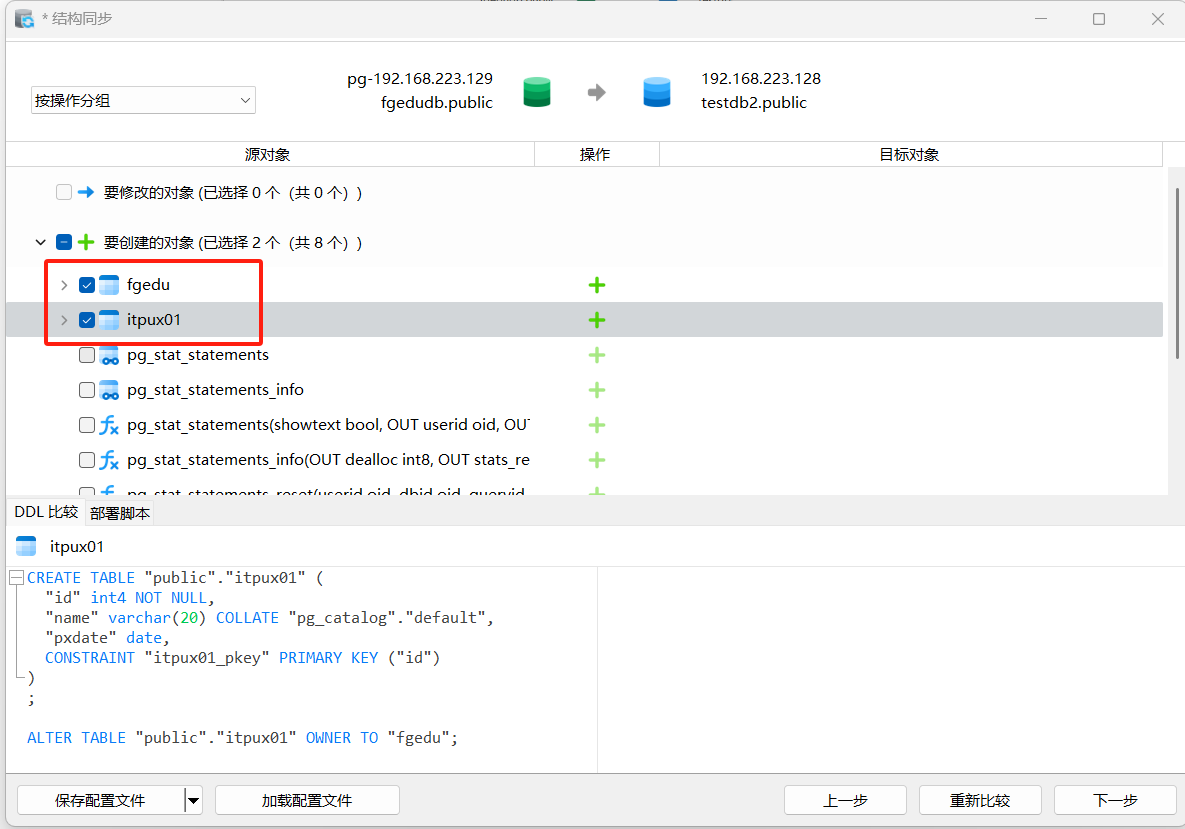
选择要同步的表,系统表一定要忽略,不要全选。
5.数据同步
数据同步是一种高效实现本地库与远程库的数据同步的方法。全部表在源及目标之间主键和全部表结构必须相同,可在数据同步前应用结构同步。但理论上不支持跨数据库类型同步,由于UNVDB和PG的全兼容,二者可以使用Navicat实现数据同步。
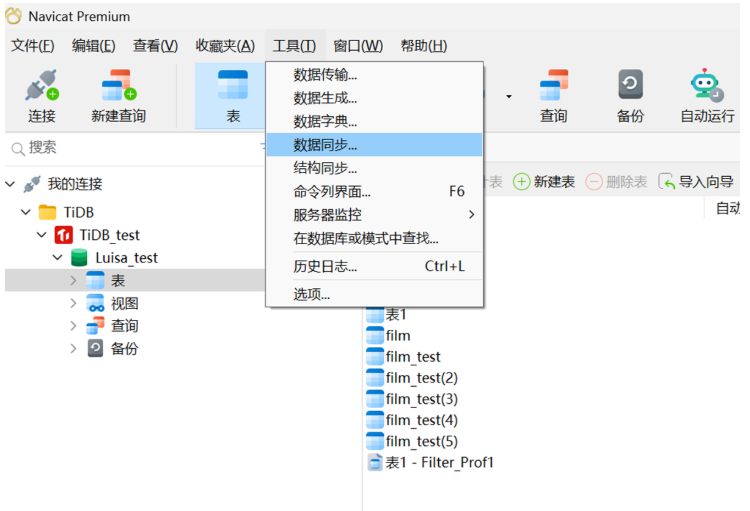
可以通过选项选择同步的操作(包括插入记录、删除记录、更新记录)。
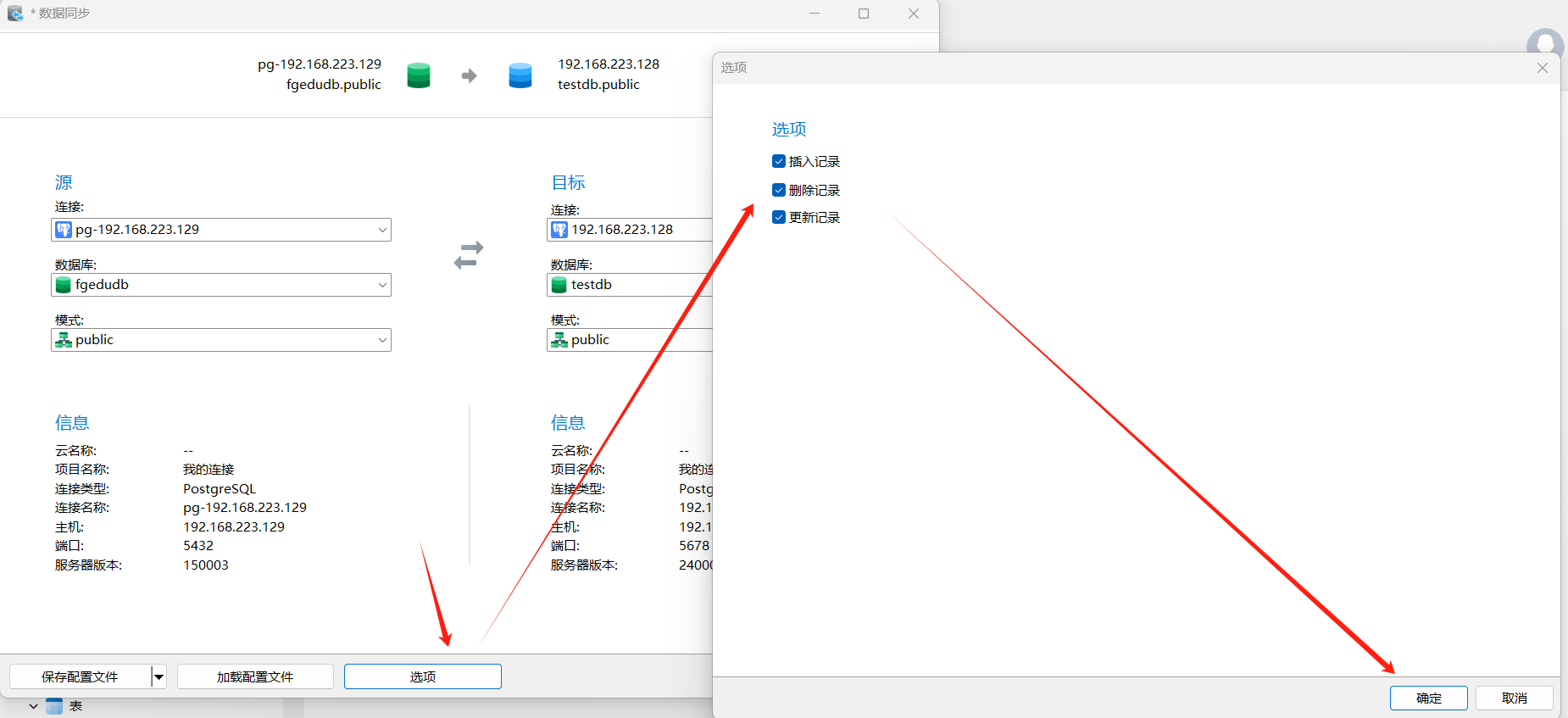
选择表,下面要注意,必须源表和目标表都有对应项,才可以,表明相同优先对应,字段名相同也可以对应。
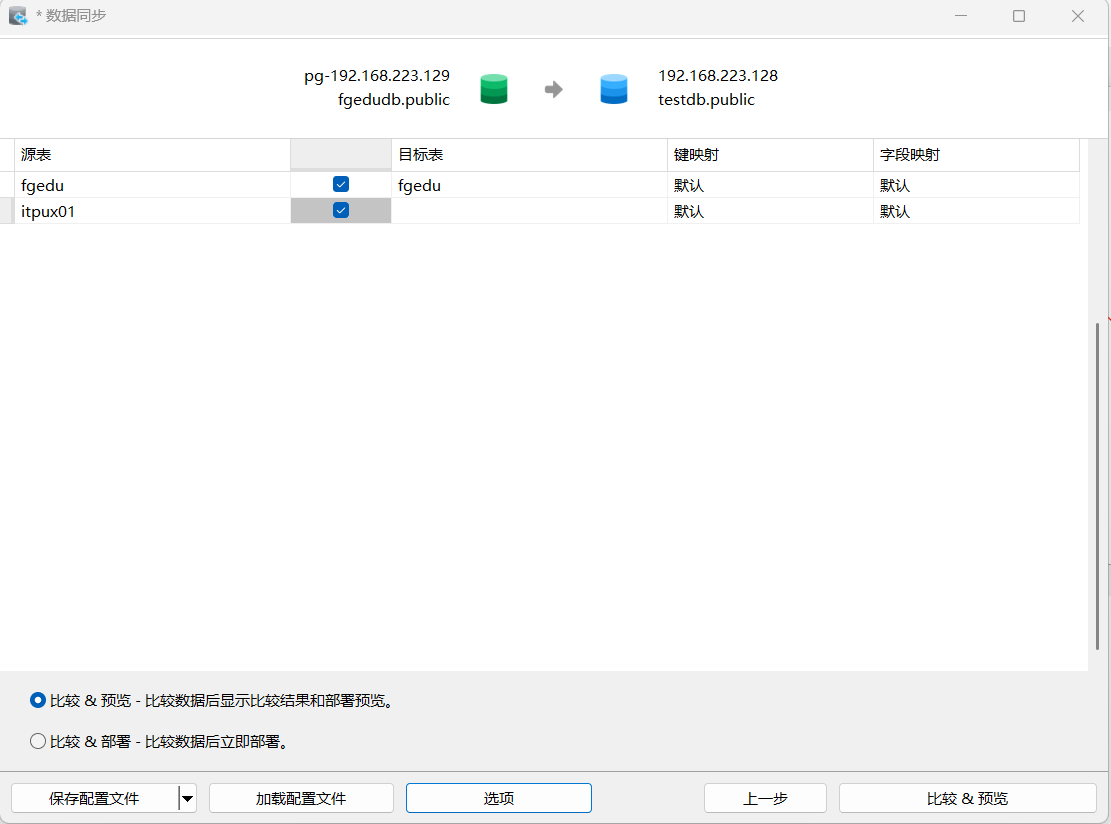
注意:表没有主键也是不可以同步的!
6.数据字典
数据字典可以方便的将整个数据库的数据字典导出到一个PDF文档中。
工具-数据字典
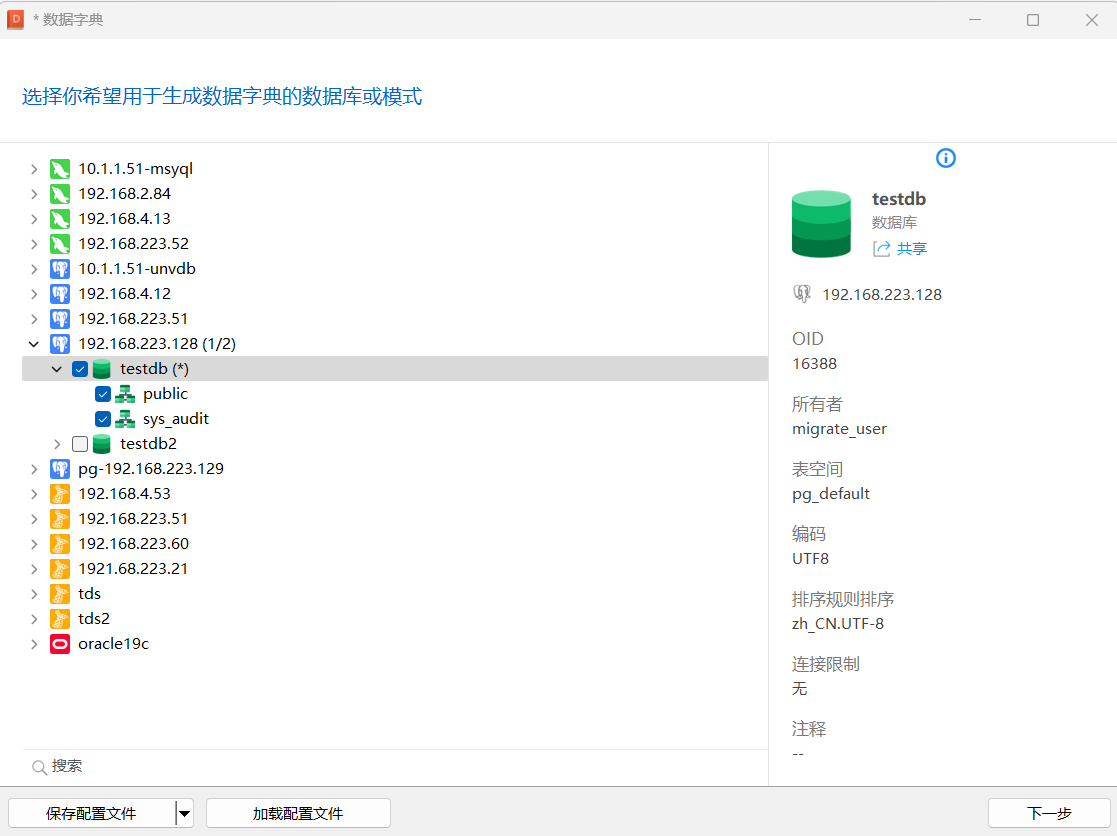
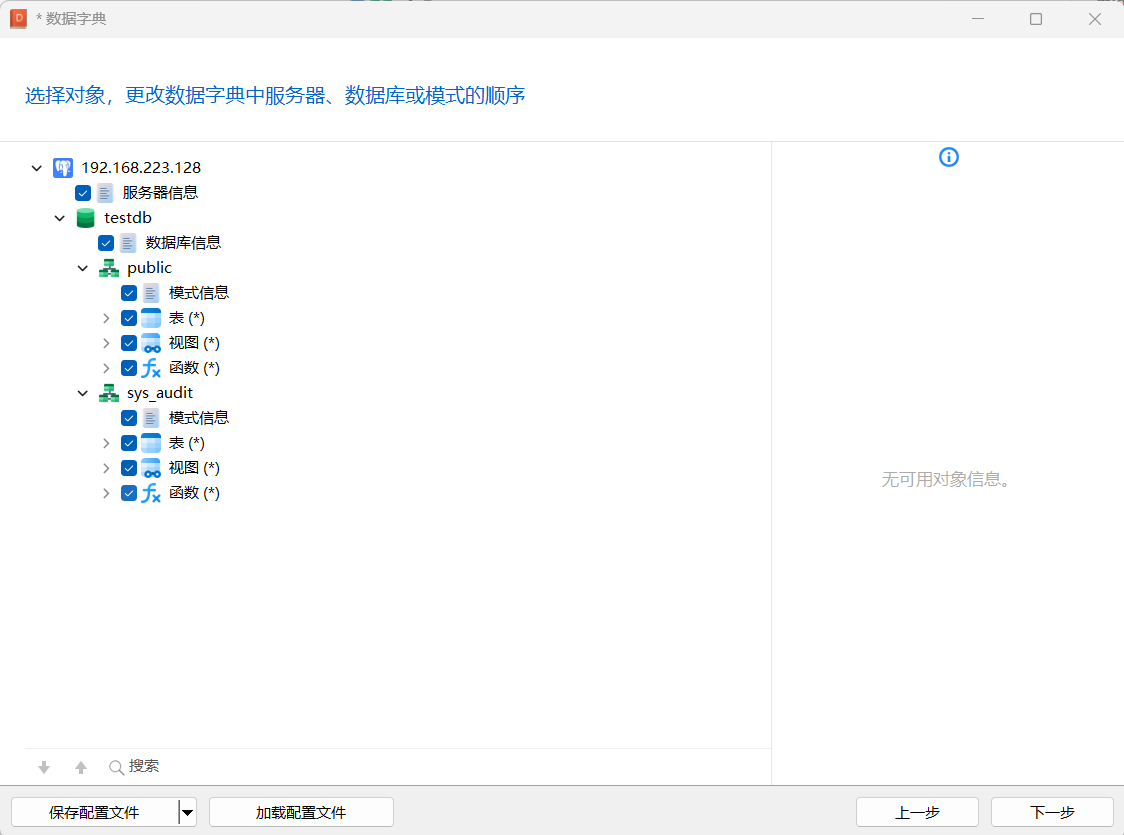
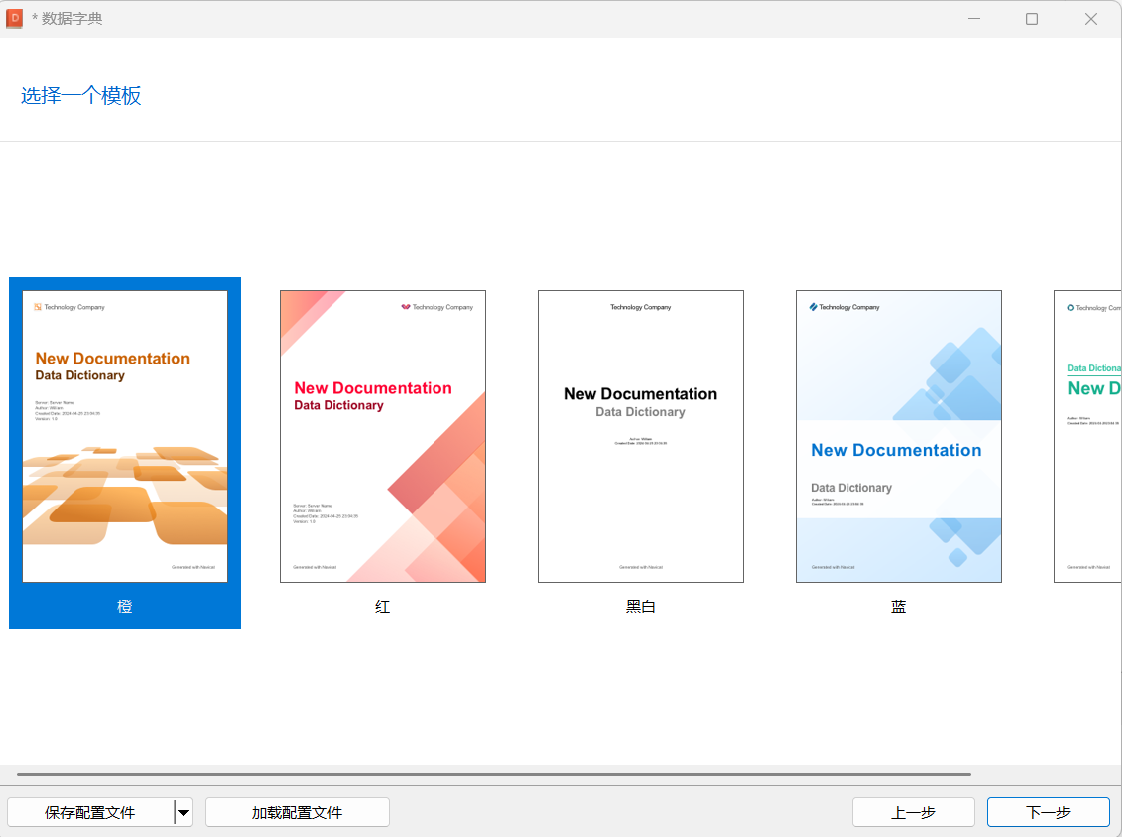
完成后,自动生成选择数据库的数据字典信息
