UDBTV 使用手册
文档名称:《UDBTV使用手册》
对象:DBA/运维/系统管理员/开发人员
关键字列表
| 关键字 | 解释 |
|---|---|
| ud_vectorscale | 专注于高效存储和检索向量数据的模块。 |
| vector | 实现向量存储/搜索功能的模块。 |
| Embedding | 实现向量化,由AI模型(例如大型语言模型LLM)生成的,它会根据不同的算法生成高维度的向量数据。 |
| ud_ai | 增强AI能力的模块,提供调用大模型和自动生成embedding的能力。 |
| AGE | 实现图数据存储/搜索功能的模块。 |
| MCP | 一个开放协议,它为应用程序向LLM提供上下文的方式进行了标准化。 |
阅读说明
本文档为通用指导文档,用户在参考的时候,对如下情况可能需要根据实际进行替换修改:
IP地址
目录名称、目录路径
用户名称
特别提醒:
在ud_sql客户端中,可以通过 \h cmd 快速获取该命令的帮助信息。
向量数据库概述
目前,最受瞩目的科技产品无疑是ChatGPT。ChatGPT的问世重新点燃了曾经静寂已久的人工智能领域,为AI注入了新的活力。大语言模型(LLM)展示了生成式AI能够达到与人类语言高度相似的表达能力,使得AI不再遥不可及,而是已经进入了人们的工作和生活中。大模型能够回答较为普世的问题,但是若要服务于垂直专业领域,会存在知识深度、知识准确度和时效性不足的问题,我们可以将企业知识库文档和数据通过向量特征提取(embedding),然后存储到向量数据库(vector database),应用LLM大语言模型与向量化的知识库检索和比对知识,提供更加专业准确的智能服务,比如电商的自动客服等场景。此外,向量数据库在图像搜索和识别、语义搜索和推荐系统和生物信息学等领域都发挥着巨大的作用,提供有力的数据分析工具。 udbtv向量数据库是九有推出的一种专门用于存储、管理和搜索向量数据的数据库并且具备与大模型融合的能力。udbtv基于九有udbtx数据库,增加了向量存储/搜索、增强AI能力的模块,提供调用大模型和自动生成embedding的能力、图数据存储/搜索功能以及支持MCP协议,这里主要介绍新增能力部分vector、ud_ai、AGE和MCP。针对文本向量化,我们用户也可以使用LangChain框架的接口来进行向量嵌入,然后将向量化结果存入udbtv再使用vector进行检索,实现更多业务场景。 udbtv比较适合的应用场景: -存储向量类型数据。 -向量相似度匹配搜索。 -图数据存储以及搜索。 -与大模型融合。
ud_vectorscale
简介
ud_vectorscale 是 udbtv 数据库的一个高性能扩展,它在 vector 的基础上进行了深度优化和创新,使其在大规模向量数据集上表现更优。该扩展通过三项核心技术突破重新定义了向量数据库的性能标准:首先采用基于改进版 DiskANN 算法的 StreamingDiskANN 索引,将索引存储从内存迁移至 SSD,在 5000 万维向量的基准测试中实现了比主流方案低 28 倍的 p95 延迟和 16 倍的查询吞吐量提升;其次运用新型统计二进制量化技术,在保证 99% 召回率的同时将存储成本降低 75%;最后创新的流式后过滤机制支持在搜索过程中动态应用业务标签过滤,有效解决了传统两阶段过滤带来的精度损失问题。这一技术组合在保持搜索精度的同时,显著提升了大规模向量检索的效率和经济效益。ud_vectorscale 采用 Rust 语言通过 PGRX 框架开发,既保持了与 udbtv 数据库原生功能的完美兼容,又为开发者提供了现代化的扩展开发体验,使得用户无需迁移至专用向量数据库即可获得同等级别的搜索性能,特别适合需要处理大规模向量数据的 RAG、推荐系统等 AI 应用场景。
前提要求
已经安装udbtv24.2。
验证安装
# select * from pg_extension;
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+----------------+----------+--------------+----------------+------------+-----------+--------------
12845 | plpgsql | 10 | 11 | f | 1.0 | |
16384 | vector | 10 | 2200 | t | 0.6.2 | |
16599 | ud_vectorscale | 10 | 2200 | f | 0.7.1 | |
(3 rows)
向量相似度搜索
创建含向量列的表
CREATE TABLE IF NOT EXISTS document_embedding (
id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
metadata JSONB,
contents TEXT,
embedding VECTOR(5)
);
往表中加入数据
INSERT INTO document_embedding (metadata, contents, embedding) VALUES
('{"author": "张三", "tags": ["科技"]}', '人工智能概述', '[0.1, 0.2, 0.3, 0.4, 0.5]'),
('{"author": "李四", "tags": ["文学"]}', '古典诗词赏析', '[0.9, 0.8, 0.7, 0.6, 0.5]'),
('{"author": "王五", "tags": ["科技"]}', '机器学习基础', '[0.15, 0.25, 0.35, 0.45, 0.55]'),
('{"author": "赵六", "tags": ["历史"]}', '中国古代史', '[0.8, 0.7, 0.6, 0.5, 0.4]');
在 embedding 列上创建 StreamingDiskANN 索引
CREATE INDEX document_embedding_idx ON document_embedding
USING diskann (embedding vector_cosine_ops);
执行相似性搜索
SELECT *
FROM document_embedding
ORDER BY embedding <=> '[0.12, 0.22, 0.32, 0.42, 0.52]'
LIMIT 3;
过滤向量搜索
ud_vectorscale支持将向量相似性搜索与元数据过滤相结合。主要提供两种过滤方式,可在同一查询中组合使用:
1. 基于标签的索引过滤(diskann索引): 通过标签实现高性能过滤,基于微软研究的Filtered DiskANN方法开发,在保证高召回率的同时实现高效过滤。
2. 任意WHERE条件过滤(后过滤): 在向量搜索完成后进行过滤,虽然速度较慢,但采用流式处理确保准确性,无需将全部结果加载到内存。
基于diskann索引的标签过滤
创建包含标签数组的表
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
embedding VECTOR(10), -- 10维向量(测试用简化版)
labels SMALLINT[], -- 标签数组(smallint范围)
status TEXT,
created_at TIMESTAMPTZ
);
插入数据
INSERT INTO documents (embedding, labels, status, created_at) VALUES
('[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0]', ARRAY[1], 'active', '2024-01-15'),
('[0.15, 0.25, 0.35, 0.45, 0.55, 0.65, 0.75, 0.85, 0.95, 1.0]', ARRAY[2], 'active', '2024-02-20'),
('[0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.0]', ARRAY[3], 'inactive', '2024-03-10');
创建包含标签列的索引
CREATE INDEX ON documents USING diskann (embedding vector_cosine_ops, labels);
执行标签过滤查询
SELECT * FROM documents
WHERE labels && ARRAY[1, 3]::smallint[]
ORDER BY embedding <=> '[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]'
LIMIT 10;
为标签赋予语义
通过关联表将整数ID映射为有意义的标签名称,兼顾性能与可读性。
创建标签定义表
CREATE TABLE label_definitions (
id INTEGER PRIMARY KEY, -- 标签ID(必须与documents表中的labels数组类型匹配)
name TEXT,
description TEXT,
attributes JSONB -- 扩展属性(如置信度、领域等)
);
插入数据
INSERT INTO label_definitions (id, name, description, attributes) VALUES
(1, '科技', '科技类内容', '{"color": "blue"}'),
(2, '财经', '财经类内容', '{"color": "green"}'),
(3, '体育', '体育类内容', '{"color": "red"}');
插入文档数据时使用整数ID
INSERT INTO documents (embedding, labels)
VALUES ('[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]', ARRAY[1, 2]);
查询时实现语义化
-- 方法A:直接显示标签名称
SELECT
d.*,
array_agg(l.name) AS tag_names -- 将[1,2]转换为["科技","财经"]
FROM documents d
JOIN label_definitions l ON l.id = ANY(d.labels)
GROUP BY d.id;
-- 方法B:通过标签名称过滤
SELECT * FROM documents
WHERE labels && (
SELECT array_agg(id::smallint)
FROM label_definitions
WHERE name IN ('科技', '财经') -- 先查名称对应的ID
);
任意WHERE条件过滤
还可以将任何 WHERE 子句与向量搜索一起使用,但这些条件将作为后过滤应用,对高频过滤条件建议改用标签索引方案。
SELECT * FROM documents
WHERE status = 'active' AND created_at > '2024-01-01'
ORDER BY embedding <=> '[0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]'
LIMIT 10;
vector
简介
vector是udbtv数据库的扩展插件,其设计目的是让用户能够在现有的udbtv数据库上实现向量搜索和计算,而无需引入额外的向量数据库。vector专门用于存储、管理和搜索向量数据。它以向量的形式存储数据,其中向量是抽象实体(如图像、音频文件、文本等)的数学表示。通过存储数据向量并使用向量之间的相似度度量,udbtv向量数据库可以实现高效、准确的数据搜索和分析。 它具有以下特点: 1.支持多种距离度量: vector内置支持多种距离度量,包括欧几里德距离、余弦距离、内积距离和曼哈顿距离。这样的多功能性使得可以根据具体应用需求进行高度定制的基于相似性的搜索和分析。 2.索引支持: vector为矢量数据提供高效的索引选项,例如k-最近邻(k-NN)搜索。即使数据集大小增长,用户也可以实现快速查询执行,并保持较高的搜索准确性。 3.易于查询语言访问: vector使用我们熟悉的SQL查询语法进行向量操作。这简化了具有SQL知识和经验的用户使用矢量数据库的过程,并避免了学习新的语言或系统。
前提要求
已经安装udbtv24.2。
注意事项
vector向量数据库利用单精度浮点数的格式进行向量存储,且向量中的元素必须为有限值。
vector最大支持创建16000个维度的向量。
验证安装
unvdb=# select * from pg_extension;
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+---------+----------+--------------+----------------+------------+-----------+--------------
13676 | plpgsql | 10 | 11 | f | 1.0 | |
16400 | vector | 10 | 2200 | t | 0.7.2 | |
(2 rows)
向量操作符
向量相似的对比方法介绍
-点积 (dot product):向量的点积相似度是指两个向量之间的点积值,它适用于许多实际场景,例如图像识别、语义搜索和文档分类等。但点积相似度算法对向量的长度敏感,因此在计算高维向量的相似性时可能会出现问题。 -内积 (inner product):全称为 Inner Product,是一种计算向量之间相似度的度量算法,它计算两个向量之间的点积(内积),所得值越大越与搜索值相似。 -欧式距离 (L2):直接比较两个向量的欧式距离,距离越近越相似。欧几里得距离算法的优点是可以反映向量的绝对距离,适用于需要考虑向量长度的相似性计算。例如推荐系统中,需要根据用户的历史行为来推荐相似的商品,这时就需要考虑用户的历史行为的数量,而不仅仅是用户的历史行为的相似度。 -余弦相似度 (Cosine):两个向量的夹角越小越相似,比较两个向量的余弦值进行比较,夹角越小,余弦值越大。余弦相似度对向量的长度不敏感,只关注向量的方向,因此适用于高维向量的相似性计算。例如语义搜索和文档分类。
向量类型
每个 vector 占用 4 * dimensions + 8 bytes 的存储空间。每个元素都是一个单精度浮点数(如udbtv中的real类型),并且所有元素都必须是有限的(非NaN/Infinity/-Infinity)。向量最多可以有 16,000 个维度。
支持的向量操作符
vector支持的方法有欧式距离(L2),内积 (inner product),余弦相似度(Cosine)。支持的向量操作符如下: |操作符|描述| |—-|—-| |+|元素相加| |-|元素相减| |*|元素相乘| ||||连接| |<->|欧式距离| |<#>|内积| |<=>|余弦距离| |<+>|曼哈顿距离|
向量函数
| 函数 | 描述 |
|---|---|
| binary_quantize(vector) → bit | 二进制量化 |
| cosine_distance(vector, vector) → double precision | 余弦距离 |
| inner_product(vector, vector) → double precision | 内积 |
| l1_distance(vector, vector) → double precision | 曼哈顿距离 |
| l2_distance(vector, vector) → double precision | 欧式距离 |
| l2_normalize(vector) → vector | 使用欧几里得范数进行归一化 |
| subvector(vector, integer, integer) → vector | 子向量 |
| vector_dims(vector) → integer | 维度数 |
| vector_norm(vector) → double precision | 欧几里得范数 |
向量聚合函数
| 函数 | 描述 |
|---|---|
| avg(vector) → vector | 平均值 |
| sum(vector) → vector | 求和 |
向量存储
创建一个存储向量的表
unvdb=# CREATE TABLE vector_table (id bigserial PRIMARY KEY,embedding vector(5));
CREATE TABLE
插入向量
unvdb=#INSERT INTO vector_table (embedding) VALUES ('[1,2,3,4,5]'), ('[0.1,0.2,0.3,0.4,0.5]');
INSERT 0 2
更新向量
unvdb=#INSERT INTO vector_table (id, embedding) VALUES (1, '[1,2,3,4.5,5]'),(2,'[0.1,0.2,0.3,0.4,0.5]')
ON CONFLICT (id) DO UPDATE SET embedding = EXCLUDED.embedding;
INSERT 0 1
更改向量
unvdb=#UPDATE vector_table SET embedding = '[0,0,0,0,0]' WHERE id=1;
UPDATE 1
删除向量
unvdb=#DELETE FROM vector_table WHERE id = 1;
DELETE 1
向量查询
在vector中,可以使用各种查询运算符对矢量数据进行不同的操作。以下是一些常用的vector查询运算符:
欧式距离
<->:该运算符计算两个向量之间的欧几里德距离。距离值越小越相近。
unvdb=# SELECT embedding <-> '[1,1,1,1,1]' as distance FROM vector_table ORDER BY embedding <-> '[1,1,1,1,1]';
distance
--------------------
1.5968719273367806
5.477225575051661
(2 rows)
余弦距离
<=>:该运算符计算两个向量之间的余弦相似度。两个向量的夹角越小越相似,比较两个向量的余弦值进行比较,夹角越小,余弦值越大。
unvdb=# SELECT embedding <=> '[1,1,1,1,1]' as similarity FROM vector_table ORDER BY embedding <-> '[1,1,1,1,1]' DESC;
similarity
---------------------
0.09546596626670922
0.0954659760693326
(2 rows)
内积
<#>:该运算符计算两个向量之间的内积。值越大越与搜索值相近。
unvdb=# SELECT embedding <#> '[1,1,1,1,1]' as distance FROM vector_table ORDER BY embedding <-> '[1,1,1,1,1]';
distance
----------
-1.5
-15
(2 rows)
在选择适当的运算符时,您应该考虑您的应用需求和数据特性。这可能涉及保持相对距离、强调大小或方向以及关注特定维度等因素。请注意,根据您的数据和用例,运算符的选择可能会对搜索结果的质量以及最终应用程序的有效性产生重大影响。
下面是根据距离已经确定的运算符进行向量查询的例子:
查询最近邻向量:
unvdb=# SELECT * FROM vector_table ORDER BY embedding <-> '[1,1,1,1,1]' LIMIT 1;
id | embedding
----+-----------------------
2 | [0.1,0.2,0.3,0.4,0.5]
(1 row)
按照距离范围进行向量筛选:
unvdb=# SELECT * FROM vector_table WHERE embedding <-> '[1,1,1,1,1]' < 5;
id | embedding
----+-----------------------
2 | [0.1,0.2,0.3,0.4,0.5]
(1 row)
平均向量
获得全部向量的平均值
unvdb=# SELECT AVG(embedding) FROM vector_table;
avg
--------------------------
[0.55,1.1,1.65,2.2,2.75]
(1 row)
获取向量的平均组数
unvdb=# SELECT id, AVG(embedding) FROM vector_table GROUP BY id LIMIT 5;
id | avg
----+-------------
12 | [5,4,3,7,6]
3 | [2,1,5,7,4]
11 | [6,1,7,6,3]
8 | [8,4,8,1,6]
10 | [5,4,3,1,6]
(5 rows)
向量索引
默认情况下,vector执行精确最近邻搜索,从而满足最高的召回率。
您可以添加索引来使用近似最近邻搜索,该搜索方式以牺牲一些召回率的方式换取搜索速度的提升。与典型索引不同,添加近似索引后,您将看到不同的查询结果。
vector支持的索引类型包括:
IVFFlat
HNSW
IVFFlat
它的工作原理是将相似的向量聚类为区域,并建立一个倒排索引,将每个区域映射到其向量。这使得查询可以集中在数据的一个子集上,从而实现快速搜索。 通过调整列表和探针参数,ivfflat可以平衡数据集的速度和准确性,使udbtv有能力对复杂数据进行快速的语义相似性搜索。 通过简单的查询,应用程序可以在数百万个高维向量中找到与查询向量最近的邻居。对于自然语言处理、信息检索等,ivfflat是一个比较好的解决方案。 在建立ivfflat索引时,你需要决定索引中包含多少个list,每个list代表一个”中心”;这些中心通过k-means算法计算而来。一旦确定了所有中心,ivfflat就会确定每个向量最靠近哪个中心,并将其添加到索引中。 当需要查询向量数据时,你可以决定要检查多少个中心,这由ivfflat.probes参数决定。这就是ANN性能/召回率的结果:访问的中心越多,结果就越精确,但这是以牺牲性能为代价的。 与HNSW相比,它具有更快的构建速度并使用更少的内存,但查询性能较差(在速度和召回率权衡方面)。
采用ivfflat找到近似的近邻,该算法的操作假设是最近的向量将位于与查询向量相同的区域。ivfflat采用了以下步骤:
计算查询向量与索引中每个中心点之间的距离
选择距离最小的中心点作为离查询最近的中心点
从倒排索引中检索与最近中心点对应的区域关联的向量
计算查询向量与检索集中每个向量之间的距离
选择距离最小的K个向量作为查询的近似最近的邻居
索引设置
以下是一些关于IVFFlat索引的建议:
在表中有一定数量的数据后创建索引:在创建索引之前,确保表中有足够的数据,以便索引能够提供更好的查询性能。
选择适当数量的列表:可以根据表的大小来选择适当数量的列表。一般来说,可以使用表的行数除以 1000(最多1M行)和平方根(rows)(超过1M行)作为起点。
指定适当的探针数量:在执行查询时,可以指定适当的探针数量来平衡查询速度和召回率。一般来说,可以使用列表数量除以 10(最多1M行)和平方根(lists)(超过1M行)作为起点。 这些建议可以帮助您在近似最近邻搜索中获得良好的准确性和性能。请注意,具体的索引配置可能需要根据您的数据和查询需求进行调整,以达到最佳性能。
要使用的每个距离函数添加一个索引,请参考下面的用例:
欧式距离
unvdb=#CREATE INDEX ON vector_table USING ivfflat (embedding vector_l2_ops) WITH (lists = 100);
NOTICE: ivfflat index created with little data
DETAIL: This will cause low recall.
HINT: Drop the index until the table has more data.
CREATE INDEX
内积
unvdb=#CREATE INDEX ON vector_table USING ivfflat (embedding vector_ip_ops) WITH (lists = 100);
NOTICE: ivfflat index created with little data
DETAIL: This will cause low recall.
HINT: Drop the index until the table has more data.
CREATE INDEX
余弦距离
unvdb=#CREATE INDEX ON vector_table USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
NOTICE: ivfflat index created with little data
DETAIL: This will cause low recall.
HINT: Drop the index until the table has more data.
CREATE INDEX
汉明距离
unvdb=# CREATE INDEX ON items USING ivfflat (embedding bit_hamming_ops) WITH (lists = 100);
CREATE INDEX
支持的类型包括:
vector- 支持最多 2,000 个维度的向量建立索引
halfvec- 支持最多 4,000 个维度的向量建立索引
bit- 支持最多 64,000 个维度的向量建立索引
lists参数表示将数据集分成的列表数,该值越大,表示数据集被分割得越多,每个子集的大小相对较小,索引查询速度越快。但随着lists值的增加,查询的召回率可能会下降。
召回率是指在信息检索或分类任务中,正确检索或分类的样本数量与所有相关样本数量之比。召回率衡量了系统能够找到所有相关样本的能力,它是一个重要的评估指标。您需要通过调整lists参数的值,在查询速度和召回率之间进行权衡,以满足具体应用场景的需求。
查询设置
您可以使用如下两种方式之一来设置ivfflat.probes参数,指定在索引中搜索的列表数量,通过增加ivfflat.probes的值,将搜索更多的列表,可以提高查询结果的召回率,即找到更多相关的结果。
会话级别 设定探针数量(默认为1)
SET ivfflat.probes = 10;
事务级别
BEGIN;
SET LOCAL ivfflat.probes = 10;
SELECT ...
COMMIT;
ivfflat.probes的值越大,查询结果的召回率越高,但是查询的速度会降低,根据具体的应用需求和数据集的特性,lists和ivfflat.probes的值可能需要进行调整以获得最佳的查询性能和召回率。
HNSW
HNSW(Hierarchical Navigable Small World)是一种基于图的索引算法,它由多层的邻近图组成,因此称为分层的NSW方法。它会为一张图按规则建成多层导航图,并让越上层的图越稀疏,结点间的距离越远;越下层的图越稠密,结点间的距离越近。 HNSW算法是一种经典的空间换时间的算法,它的搜索质量和搜索速度都比较高,但是它的内存开销也比较大,因为不仅需要将所有的向量都存储在内存中,还需要维护一个图的结构,也同样需要存储。所以这类算法需要根据实际的场景来选择。
HNSW的原理如下:
构建层级索引:首先,将数据集中的点随机选择一个作为入口点(Entry Point),然后将其他点插入到索引中形成多层级的结构。每一层都是一个Small World网络,其中每个点都连接到其他几个点,以便在搜索时能够速定位到更接近目标的点。
贪心搜索:搜索时,从最高层级(Entry Point所在层级)开始,根据一定的规则选择相邻点,直到达到目标点或者到达最低层级。在每一层级中,选择与目标点更接近的点作为下一层级的起点,并继续向下搜索。
剪枝和修剪:在搜索过程中,可以使用剪枝和修剪策略来减少搜索空间。剪枝是指通过一些阈值或规则判断某些节点是否需要继续扩展搜索,如果不需要,则直接跳过这些节点。修剪是指在搜索过程中,根据实时计算的距离等信息,将一些不相关或不接近目标的节点从搜索路径中移除,以加快搜索速度。
近似最近邻:由于HNSW是一种近似搜索算法,所以找到的最近邻并不一定是精确的最近邻。但是,HNSW能够在高维空间中以较小的误差找到近似的最近邻,同时具有较高的搜索效率。
HNSW 索引可创建多层图结构。它的构建时间较慢,使用比IVFFlat更多的内存,但具有更好的查询性能(在速度和召回率权衡方面)。HNSW没有像IVFFlat这样的训练步骤,因此可以在没有任何数据的情况下创建索引。
索引设置
指定HNSW参数
m- 每层的最大连接数(默认为 16)ef_construction- 用于构造图形的动态候选列表的大小(默认为 64)
unvdb=#CREATE INDEX ON vector_table USING hnsw (embedding vector_l2_ops) WITH (m = 16, ef_construction = 64);
CREATE INDEX
要使用的每个距离函数添加一个索引,请参考下面的用例:
欧式距离
unvdb=#CREATE INDEX ON vector_table USING hnsw (embedding vector_l2_ops);
CREATE INDEX
内积
unvdb=#CREATE INDEX ON vector_table USING hnsw (embedding vector_ip_ops);
CREATE INDEX
余弦距离
unvdb=#CREATE INDEX ON vector_table USING hnsw (embedding vector_cosine_ops);
CREATE INDEX
汉明距离
unvdb=# CREATE INDEX ON vector_table USING ivfflat (embedding bit_hamming_ops) WITH (lists = 100);
CREATE INDEX
Jaccard距离
unvdb=# CREATE INDEX ON vector_table USING hnsw (embedding bit_jaccard_ops);
CREATE INDEX
支持的类型包括:
vector- 支持最多 2,000 个维度的向量建立索引
halfvec- 支持最多 4,000 个维度的向量建立索引
bit- 支持最多 64,000 个维度的向量建立索引
sparsevec- 支持最多 1,000 个非零元素维度的向量建立索引
查询设置
指定用于搜索的动态候选列表的大小(默认为 40),设定较高的值会以牺牲速度为代价得到更好的召回率。
会话级别
SET hnsw.ef_search = 100;
事务级别
BEGIN;
SET LOCAL hnsw.ef_search = 100;
SELECT ...
COMMIT;
Filtering(过滤)机制
有几种方法可以使用WHERE子句为最近邻查询建立索引。
unvdb=# SELECT * FROM vector_table WHERE id = 1 ORDER BY embedding <-> '[3,1,2,4,5]' LIMIT 5;
id | embedding
----+-------------
1 | [1,2,3,4,5]
(1 row)
一个好的方法是在需要过滤的列上建立索引。在许多情况下,这可以提供快速、准确的最近邻搜索。udbtv为此提供了多种索引类型:B 树(默认)、哈希、GiST、SP-GiST、GIN 和 BRIN。
unvdb=# CREATE INDEX ON vector_table (id);
CREATE INDEX
对于多列,请考虑混合索引。
unvdb=# CREATE INDEX ON vector_table (id, embedding);
CREATE INDEX
精确索引适用于与较低百分比的行匹配的条件。否则,近似索引可以更好地工作。
unvdb=# CREATE INDEX ON vector_table USING hnsw (embedding vector_l2_ops);
CREATE INDEX
对于近似索引,将在扫描索引后应用筛选。如果条件匹配 10% 的行,使用 HNSW 和默认值 40,则平均只有 4 行匹配。对于更多行,请增加 hnsw.ef_search。
unvdb=# SET hnsw.ef_search = 200;
SET
您可以启用迭代索引扫描,这将在需要时自动扫描更多索引。
unvdb=# SET hnsw.iterative_scan = strict_order;
SET
如果仅按几个不同的值进行筛选,请考虑使用部分索引。
unvdb=# CREATE INDEX ON vector_table USING hnsw (embedding vector_l2_ops) WHERE (id = 123);
CREATE INDEX
如果按许多不同的值进行筛选,请考虑分区。
unvdb=# CREATE TABLE vector_table (embedding vector(5), id int) PARTITION BY LIST(id);
CREATE INDEX
迭代索引扫描(Iterative Index Scans)
对于近似索引,使用筛选的查询可能返回更少的结果,因为筛选是在扫描索引后应用的。您可以启用迭代索引扫描,它将自动扫描更多索引,直到找到足够的结果。
迭代扫描可以使用严格或宽松排序。
Strict 确保结果按距离准确排序
unvdb=# SET hnsw.iterative_scan = strict_order;
SET
“Relaxed”允许结果按距离略微乱序,但提供更好的召回率
unvdb=# SET hnsw.iterative_scan = relaxed_order;
SET
# or
unvdb=# SET ivfflat.iterative_scan = relaxed_order;
SET
使用宽松排序,您可以使用 materialized CTE 来获得严格的排序
unvdb=# WITH relaxed_results AS MATERIALIZED (
SELECT id, embedding <-> '[1,2,3,4,5]' AS distance FROM vector_table WHERE id = 12 ORDER BY distance LIMIT 5
) SELECT * FROM relaxed_results ORDER BY distance;
id | distance
----+-------------------
12 | 5.477225575051661
(1 row)
对于按距离筛选的查询,请使用 materialized CTE 并将距离筛选器放在其外部以获得最佳性能
unvdb=# WITH nearest_results AS MATERIALIZED (
SELECT id, embedding <-> '[1,2,3,4,5]' AS distance FROM vector_table ORDER BY distance LIMIT 5
) SELECT * FROM nearest_results WHERE distance < 5 ORDER BY distance;
id | distance
----+-----------------
1 | 0
5 | 3.3166247903554
3 | 4
(3 rows)
注意:将任何其他过滤器放在 CTE 中
迭代扫描选项
由于扫描近似索引的大部分成本很高,因此可以选择选项来控制何时结束扫描。
HNSW
指定要访问的最大元组数(默认为 20,000)
unvdb=# SET hnsw.max_scan_tuples = 20000;
SET
注: 这是近似值,不会影响初始扫描
指定要使用的最大内存量,作为 work_mem(默认为 1) 的倍数
unvdb=# SET hnsw.scan_mem_multiplier = 2;
SET
注意:如果没有提高召回率,请尝试增加 hnsw.max_scan_tuples 的值
IVFFlat
指定最大探测数
unvdb=# SET ivfflat.max_probes = 100;
SET
注意:如果此值低于ivfflat.probes,将使用 ivfflat.probes
半精度向量(Half-Precision Vectors)
使用 halfvec 类型来存储半精度向量
unvdb=# CREATE TABLE items (id bigserial PRIMARY KEY, embedding halfvec(3));
CREATE TABLE
Halfvec 型
每个 half vector 占用 2 * dimensions + 8 bytes 的存储空间。每个元素都是一个半精度浮点数,并且所有元素都必须是有限的(非NaN/Infinity/-Infinity)。半精度向量最多可以有 16,000 个维度。
Halfvec 运算符
| 操作符 | 描述 |
|---|---|
| + | 元素相加 |
| - | 元素相减 |
| * | 元素相乘 |
| || | 连接 |
| <-> | 欧式距离 |
| <#> | 内积 |
| <=> | 余弦距离 |
| <+> | 曼哈顿距离 |
Halfvec 函数
|函数 | 描述 | |— | — | |binary_quantize(halfvec) → bit | 二进制量化 | |cosine_distance(halfvec, halfvec) → double precision | 余弦距离 | |inner_product(halfvec, halfvec) → double precision | 内积 | |l1_distance(halfvec, halfvec) → double precision | 曼哈顿距离 | |l2_distance(halfvec, halfvec) → double precision | 欧式距离 | |vector_norm(halfvec) → double precision | 欧几里得范数 | |l2_normalize(halfvec) → halfvec | 使用欧几里得范数进行归一化 | |subvector(halfvec, integer, integer) → halfvec | 子向量 | |vector_dims(halfvec) → integer | 维度数 |
Halfvec 聚合函数
| 函数 | 描述 |
|---|---|
| avg(halfvec) → halfvec | 平均值 |
| sum(halfvec) → halfvec | 求和 |
半精度索引(Half-Precision Indexing)
半精度索引是为了提供较小的索引
unvdb=# CREATE INDEX ON vector_table USING hnsw ((embedding::halfvec(3)) halfvec_l2_ops);
CREATE INDEX
获取最近的邻
unvdb=# SELECT * FROM items ORDER BY embedding::halfvec(3) <-> '[1,2,3]' LIMIT 2;
id | embedding
----+-----------
1 | [3,1,2]
2 | [1,5,7]
(2 rows)
二进制向量(Binary Vectors)
使用bit类型存储二进制向量
unvdb=# CREATE TABLE items (id bigserial PRIMARY KEY, embedding bit(3));
CREATE TABLE
unvdb=# INSERT INTO items (embedding) VALUES ('000'), ('111');
INSERT 0 2
通过汉明距离获取最近邻
unvdb=# SELECT * FROM items ORDER BY embedding <~> '101' LIMIT 5;
id | embedding
----+-----------
2 | 111
1 | 000
(2 rows)
还支持 杰卡德(Jaccard) 距离 (<%>)
bit类型
每个位向量占用 dimensions / 8 + 8 bytes 的存储空间。
位运算符
|算子| 描述 | |— | — | |<~>| 汉明距离 | |<%>| jaccard距离 |
位函数
| 函数 | 描述 |
|---|---|
| hamming_distance(bit, bit) → double precision | 汉明距离 |
| jaccard_distance(bit, bit) → double precision | jaccard距离 |
二进制量化(Binary Quantization)
使用表达式索引进行二进制量化
unvdb=# CREATE INDEX ON items USING hnsw ((binary_quantize(embedding)::bit(3)) bit_hamming_ops);
CREATE INDEX
按汉明距离获取最近邻
unvdb=# SELECT * FROM items ORDER BY binary_quantize(embedding)::bit(3) <~> binary_quantize('[1,-2,3]'::vector) LIMIT 5;
id | embedding
----+-----------
1 | [1,2,3]
2 | [4,5,6]
(2 rows)
按原始向量重新排序,以便更好地调用
unvdb=# SELECT * FROM (^J SELECT * FROM items ORDER BY binary_quantize(embedding)::bit(3) <~> binary_quantize(('[1,-2,3]')::vector) L>
id | embedding
----+-----------
1 | [1,2,3]
2 | [4,5,6]
(2 rows)
稀疏向量(Sparse Vectors)
使用 sparsevec 类型存储稀疏向量
unvdb=# CREATE TABLE items_s (id bigserial PRIMARY KEY, embedding sparsevec(5));
CREATE TABLE
插入向量
unvdb=# INSERT INTO items_s (embedding) VALUES ('{1:1,3:2,5:3}/5'), ('{1:4,3:5,5:6}/5');
INSERT 0 2
格式为{index1:value1,index2:value2}/dimensions,索引从1开始
按 L2 距离获取最近邻
unvdb=# SELECT * FROM items_s ORDER BY embedding <-> '{1:3,3:1,5:2}/5' LIMIT 5;
id | embedding
----+-----------------
1 | {1:1,3:2,5:3}/5
2 | {1:4,3:5,5:6}/5
(2 rows)
Sparsevec 类型
每个稀疏向量占用 8 * non-zero elements + 16 bytes 的存储空间。每个元素都是一个单精度浮点数,并且所有元素都必须是有限的(非NaN/Infinity/-Infinity )。稀疏向量最多可以有 16,000 个非零元素。
Sparsevec 运算符
|算子| 描述 | |— | — | |<->| 欧式距离 | |<%>| 负内积 | |<=>| 余弦距离 | |<+>| 曼哈顿距离 |
Sparsevec 函数
|函数 | 描述 | |— | — | |cosine_distance(sparsevec, sparsevec) → double precision | 余弦距离 | |inner_product(sparsevec, sparsevec) → double precision | 内积 | |l1_distance(sparsevec, sparsevec) → double precision | 曼哈顿距离 | |l2_distance(sparsevec, sparsevec) → double precision | 欧式距离 | |l2_norm(sparsevec) → double precision | 欧几里得范数 | |l2_normalize(sparsevec) → sparsevec | 使用欧几里得范数进行归一化 |
混合搜索
与 udbtv 全文搜索一起使用以进行混合搜索。
SELECT id, content FROM items, plainto_tsquery('hello search') query
WHERE textsearch @@ query ORDER BY ts_rank_cd(textsearch, query) DESC LIMIT 5;
索引子向量(Indexing Subvectors)
使用表达式索引为子向量建立索引
unvdb=# CREATE INDEX ON items USING hnsw ((subvector(embedding, 1, 3)::vector(3)) vector_cosine_ops);
CREATE INDEX
按余弦距离获取最近邻
SELECT * FROM items ORDER BY subvector(embedding, 1, 3)::vector(3) <=> subvector('[1,2,3,4,5]'::vector, 1, 3) LIMIT 5;
id | embedding
----+-----------------------
1 | [1,2,3,4,5]
2 | [0.1,0.2,0.3,0.4,0.5]
(2 rows)
按完整向量重新排序,以便更好地调用
unvdb=# SELECT * FROM (
subvector(embedding, 1, 3)::vector(3) <=> subvector('[1,2,3,4,5]'::vector, 1, 3) LIMIT 20
) ORDER BY embedding <=> '[1,2,3,4,5]' LIMIT 5;
id | embedding
----+-----------------------
1 | [1,2,3,4,5]
2 | [0.1,0.2,0.3,0.4,0.5]
(2 rows)
常见问题解答
单个表中可以存储多少个 vector? 默认情况下,非分区表在 unvdb 中的限制为 32 TB。一个分区表可以有数千个该大小的分区。
是否支持复制? 是的,vector 使用预写日志 (WAL),它允许复制和时间点恢复。
如果要为超过 2,000 个维度的向量编制索引,该怎么办? 您可以使用半精度索引,多达 4000 个维度创建索引;或使用二进制量化,多达 64000 个维度创建索引。另一种选择是降维。
我可以在同一列中存储不同维度的向量吗? 您可以使用vector而不是vector(3)
unvdb=# CREATE TABLE embeddings (model_id bigint, item_id bigint, embedding vector, PRIMARY KEY (model_id, item_id));
CREATE TABLE
但是,您只能在具有相同维度数的行上创建索引.
unvdb=# CREATE INDEX ON embeddings USING hnsw ((embedding::vector(3)) vector_l2_ops) WHERE (model_id = 123);
CREATE INDEX
并使用以下命令进行查询:
unvdb=# SELECT * FROM embeddings WHERE model_id = 123 ORDER BY embedding::vector(3) <-> '[3,1,2]' LIMIT 5;
我能否更精确地存储向量 ? 您可以使用double precision[] 或 numeric[]更精确地存储向量。
CREATE TABLE items (id bigserial PRIMARY KEY, embedding double precision[]);
-- use {} instead of [] for udbtv arrays
INSERT INTO items (embedding) VALUES ('{1,2,3}'), ('{4,5,6}');
(可选)添加 check 约束以确保数据可以转换为vector类型并具有预期的维度。
ALTER TABLE items ADD CHECK (vector_dims(embedding::vector) = 3);
使用表达式索引进行索引(精度较低):
CREATE INDEX ON items USING hnsw ((embedding::vector(3)) vector_l2_ops);
并使用以下命令进行查询:
SELECT * FROM items ORDER BY embedding::vector(3) <-> '[3,1,2]' LIMIT 5;
索引需要适合的内存吗? 不需要,但与其他索引类型一样,如果它们这样做,您可能会看到更好的性能。您可以通过以下方式获取索引的大小:
SELECT pg_size_pretty(pg_relation_size('index_name'));
故障排除
为什么查询不使用索引? 查询需要具有ORDER BY and LIMIT,并且 ORDER BY 必须是按升序排列的距离运算符(不是表达式)的结果。
-- index
ORDER BY embedding <=> '[3,1,2]' LIMIT 5;
-- no index
ORDER BY 1 - (embedding <=> '[3,1,2]') DESC LIMIT 5;
您可以鼓励 Planner 使用索引来查询:
BEGIN;
SET LOCAL enable_seqscan = off;
SELECT ...
COMMIT;
此外,如果表较小,则表扫描可能会更快。
为什么不使用并行表的查询进行扫描? 规划器在成本估算中不考虑离线存储,这可能会使串行扫描看起来更便宜。您可以通过以下方式降低查询的并行扫描成本:
BEGIN;
SET LOCAL min_parallel_table_scan_size = 1;
SET LOCAL parallel_setup_cost = 1;
SELECT ...
COMMIT;
或选择内联存储向量:
ALTER TABLE items ALTER COLUMN embedding SET STORAGE PLAIN;
为什么在添加 HNSW 索引后,查询的结果较少? 结果受动态候选列表大小的限制。由于查询中的死元组或筛选条件,结果可能会更少。我们建议设置为至少是查询的两倍。如果您需要的结果超过 500 个,请改用 IVFFlat 索引。
另外,请注意,NULL向量没有索引(余弦距离中的零向量)。
为什么在添加 IVFFlat 索引后,查询的结果较少? 该索引可能是使用对于列表数量来说太少的数据创建的。删除索引,直到表有更多数据。
DROP INDEX index_name;
结果也可能受到探针数量的限制(ivfflat.probes)。 另外,请注意,零向量没有索引(余弦距离中的零向量)。
vector使用示例
问题提出
构建一个测试用例,在udbtv中测试对向量数据的检索。向量数据集采用公开的国内省市位置数据,将经纬度作为向量维度存储。通过欧几里德距离计算向量数据间距离(即城市间距离),查询距离北京最近的城市。
建表
unvdb=# create table cities(id bigserial primary key,province text,city text,pos vector(2));
CREATE TABLE
插入数据
unvdb=# insert into cities values(1,'北京','北京市','[39.90469,116.40717]');
INSERT 0 1
unvdb=# insert into cities values(2,'天津','天津市','[39.0851,117.19937]');
INSERT 0 1
unvdb=# insert into cities values(3,'上海','上海市','[31.23037,121.4737]');
INSERT 0 1
unvdb=# insert into cities values(4,'重庆','重庆市','[29.56471,106.55073]');
INSERT 0 1
unvdb=# insert into cities values(5,'香港特别行政区','九龙','[22.327114,114.17495]');
INSERT 0 1
创建向量索引
unvdb=# create index on cities using ivfflat (pos vector_l2_ops) with (lists = 100);
NOTICE: ivfflat index created with little data
DETAIL: This will cause low recall.
HINT: Drop the index until the table has more data.
CREATE INDEX
查看数据
unvdb=# select * from cities;
id | province | city | pos
----+----------------+--------+-----------------------
1 | 北京 | 北京市 | [39.90469,116.40717]
2 | 天津 | 天津市 | [39.0851,117.19937]
3 | 上海 | 上海市 | [31.23037,121.4737]
4 | 重庆 | 重庆市 | [29.56471,106.55073]
5 | 香港特别行政区 | 九龙 | [22.327114,114.17495]
(5 rows)
计算近似向量,查询距离北京最近的城市
unvdb=# select province,city,pos,pos<->(select pos from cities where province='北京' and city='北京市') as distance from cities order by pos<->(select pos from cities where province='北京' and city='北京市') limit 5;
province | city | pos | distance
----------------+--------+-----------------------+--------------------
北京 | 北京市 | [39.90469,116.40717] | 0
天津 | 天津市 | [39.0851,117.19937] | 1.1398720542316627
上海 | 上海市 | [31.23037,121.4737] | 10.045572958859905
重庆 | 重庆市 | [29.56471,106.55073] | 14.285121000776854
香港特别行政区 | 九龙 | [22.327114,114.17495] | 17.71874655533476
(5 rows)
向量嵌入
用户需要在数据库中直接将文本转化为向量时,可以使用第三方框架提供的模型配置和模型调用能力,使文本到向量的转换变得简单快捷,从而满足特定的数据处理需求。
简介
嵌入(Embedding)是指将高维数据映射为低维表示的过程。在机器学习和自然语言处理中,嵌入通常用于将离散的符号或对象表示为连续的向量空间中的点。 在生成嵌入时,向量数据的值取决于所参照的模型数据,用户可以调用LangChain接口将数据库中的文本内容,基于引入的外部模型(比如OpenAI),生成对应的向量数据,然后将向量化的数据存入udbtv,使用vector插件,实现更多业务场景。
向量嵌入(Vector Embedding)是由AI模型(例如大型语言模型 LLM)生成的,它会根据不同的算法生成高维度的向量数据,代表着数据的不同特征,这些特征代表了数据的不同维度。例如,对于文本,这些特征可能包括词汇、语法、语义、情感、情绪、主题、上下文等。对于音频,这些特征可能包括音调、节奏、音高、音色、音量、语音、音乐等。 例如对于目前来说,文本向量可以通过OpenAI的text-embedding-ada-002模型生成,图像向量可以通过clip-vit-base-patch32模型生成,而音频向量可以通过wav2vec2-base-960h模型生成。这些向量都是通过AI模型生成的,所以它们都是具有语义信息的。 例如我们将这句话 “Your text string goes here” 用text-embedding-ada-002模型进行文本Embedding,它会生成一个1536维的向量,得到的结果是这样:“-0.006929283495992422, -0.005336422007530928, … -4547132266452536e-05,-0.024047505110502243”,它是一个长度为1536的数组。这个向量就包含了这句话的所有特征,这些特征包括词汇、语法,我们可以将它存入向量数据库中,以便我们后续进行语义搜索。
LangChain用法
LangChain是一个基于语言模型开发应用程序的框架。它可以实现以下应用程序: -数据感知:将语言模型连接到其他数据源。 -自主性:允许语言模型与其环境进行交互。
LangChain的主要价值在于: -组件化:为使用语言模型提供抽象层,以及每个抽象层的一组实现。组件是模块化且易于使用的,无论您是否使用LangChain框架的其余部分。 -现成的链:结构化的组件集合,用于完成特定的高级任务。
下面主要介绍如何使用LangChain对文本进行向量化并将向量化数据存入udbtv。其中向量化中使用的大模型为OpenAI,因此使用之前需要有使用到的OpenAI大模型账号和API密钥(api_key)。
前置条件
python3.8及以上。
安装如下python包: pip install numpy pip install langchain langchain-community langchain-openai pip install openai
具备OpenAI的api_key(类似”sk-xxxxxx”)并且网络环境可以使用OpenAI。
实操步骤
导入需要的库
from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings.openai import OpenAIEmbeddings
import numpy as np
import time
import openai
import os
将自定义的文本进行切分
embedding前首先需要将自己准备的文本进行拆分,其中chunk_size和chunk_overlap可以按照文本大小进行设置
#设定自定义文本地址
loader = TextLoader("文字的起源和发展.txt", encoding="utf-8")
documents = loader.load()
#进行切分设置
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
#查看切分情况
print("len(docs):", len(docs))
# for doc in docs:
# print("="*50)
# print(doc.page_content)
输出:
Created a chunk of size 327, which is longer than the specified 300
Created a chunk of size 382, which is longer than the specified 300
Created a chunk of size 350, which is longer than the specified 300
len(docs): 9
==================================================
文字是人类群体发展到一定规模;政治,经济,文化等等发展到一定阶段,所人为主观创造的产物。
当今世界人类所公认的四大古文字有:位于幼发拉底河,底格里斯河的古巴比伦的苏美尔楔形文字;位于尼罗河的埃及圣书字;位于克里特岛河流的希腊的克里特岛线形文字A和克里特岛的线形文字B;位于长江和黄河流域的中国的汉字。
==================================================
从四大古文字的分布规律我们可以看出,文字的起源和发展一定是位于大河流域。为什么是位于大河流域?因为水是生命之源,人类的生存需要水。水中有丰富的渔业资源,农业的发展灌溉也离不开水,畜牧业的养殖也离不开水……只有位于大河流域才有利于人类的生存和繁衍,只有满足了人民的基本需求,人民才有足够的精力和时间去创造文字。
作为一个中国人,汉字是我们生活中必不可少的一部分,但是对于自己文字的起源,我们真正的了解过吗?
......
对切分后的文本进行embedding
将文本切分后,就可以进行embedding,embedding模型可以根据需要进行更改。
#设置模型和参数
openai.api_key='sk-xxxxxx'
EMBEDDING_MODEL="text-embedding-ada-002"
#进行embedding
doc_embeddings=np.empty([len(docs),1536])
for i in range (0,len(docs)-1):
query_embedding_response = openai.Embedding.create(
model=EMBEDDING_MODEL,
input=docs[i].page_content,
)
doc_embeddings[i]=query_embedding_response['data'][0]['embedding']
print(doc_embeddings[i])
# 将embedding数组保存到文件中,此处仅为演示,可以不用保存文件而是直接写入udbtv
np.save('doc_embeddings.npy', doc_embeddings)
embedding示例:
[ 0.00616405 -0.0143894 0.01254613 ... -0.0173492 -0.00500788
-0.02054684]
[ 0.01662868 -0.01428607 -0.00618295 ... -0.00472042 -0.01408125
-0.00261943]
[ 0.00142751 -0.00074608 0.00865691 ... -0.00086901 -0.00140454
-0.0358799 ]
[-0.00243392 -0.016965 -0.00367867 ... 0.02270534 0.00080092
-0.02744854]
...
以上就将一个文本向量化为vector,我们可以将得到的向量存入我们的向量数据库中,当有查询的时候,我们使用同样的方法对查询串进行向量化,然后在向量数据库中根据向量相似度查找得到相似的文本。
相关参考
langchain的详细说明和使用,请参见langchain官方文档。
ud_ai
简介
ud_ai是udbtv数据库的扩展插件, 可以增强udbtv数据库的AI能力。它可以支持:
自动为表中的数据创建向量embedding
无缝的向量相似度检索
直接通过SQL实现RAG的能力
通过SQL调用大模型的能力,比如调用部署在Ollama上的大模型
前提要求
已经安装python3.9以上的版本
已经安装vector
已安装libffi
yum install libffi-devel
验证安装
unvdb=# select * from pg_extension;
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+------------+----------+--------------+----------------+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------
12777 | plpgsql | 10 | 11 | f | 1.0 |
|
35929 | ud_ai | 10 | 25994 | f | 0.8.0 | {35947,35946,35968}
| {"","","where (\"name\", \"role\") not in (('*', 'pg_database_owner'), ('*', 'unvdb'))"}
26157 | vector | 10 | 2200 | t | 0.6.2 |
|
26372 | plpython3u | 10 | 11 | f | 1.0 |
|
(4 rows)
ud_ai使用示例
通过ollama调用deepseek的能力
要通过ud_ai调用Ollama中部署的大模型能力,必须保证udbtv能通过网络访问到Ollama。
设置ollama的访问地址
ud_ai使用host参数来指定 Ollama的网络地址。可以使用ai.ollama_host配置。如果没有传递host参数,并且缺少ai.ollama_host配置,则默认为’http://localhost:11434’,并且会向日志文件附加警告。
可以通过下面的几种方式设置Ollama的配置:
显式通过
host参数设置select ai.ollama_generate ( 'deepseek-r1:32b' , '深圳六月一般是什么天气' , host=>'http://host.for.ollama:port' )
使用
ai.ollama_host参数session级别
select set_config('ai.ollama_host', 'http://host.for.ollama:port', false)
系统级别
把
ai.ollama_host=’http://host.for.ollama:port’加入到unvdbsvr.conf, 重启数据库服务
list_models
列出Ollama中支持的模型:
SELECT * FROM ai.ollama_list_models() ORDER BY size DESC;
返回结果:
name | model | size | digest
| family | format | families | parent_model | parameter_size | quantization_level | modified_at
------+-----------------------+-------------+------------------------------------------------------------------+-----------+--------+---------------+--------------+----------------+--------------------+-------------------------------
| deepseek-r1:32b | 19851337640 | 38056bbcbb2d068501ecb2d5ea9cea9dd4847465f1ab88c4d4a412a9f7792717 | qwen2 | gguf | ["qwen2"] | | 32.8B | Q4_K_M | 2025-03-04 04:34:00.28152-05
| deepseek-coder-v2:16b | 8905126121 | 63fb193b3a9b4322a18e8c6b250ca2e70a5ff531e962dbf95ba089b2566f2fa5 | deepseek2 | gguf | ["deepseek2"] | | 15.7B | Q4_0 | 2025-03-04 04:32:20.163413-05
| deepseek-r1:7b | 4683075271 | 0a8c266910232fd3291e71e5ba1e058cc5af9d411192cf88b6d30e92b6e73163 | qwen2 | gguf | ["qwen2"] | | 7.6B | Q4_K_M | 2025-02-05 02:40:33.825424-05
| deepseek-r1:1.5b | 1117322599 | a42b25d8c10a841bd24724309898ae851466696a7d7f3a0a408b895538ccbc96 | qwen2 | gguf | ["qwen2"] | | 1.8B | Q4_K_M | 2025-02-05 02:07:42.798237-05
| qwen2.5-coder:1.5b | 986062047 | 6d3abb8d2d5312625fcd99a442977923aca9afa8a9e0a73c01000f48082d9d94 | qwen2 | gguf | ["qwen2"] | | 1.5B | Q4_K_M | 2025-03-12 23:28:21.451303-04
(5 rows)
embed
使用指定的模型生成embedding
select ai.ollama_embed( 'deepseek-r1:32b', '编写一首七言绝句');
返回结果:
ollama_embed
--------------------------------------------------------
[-1.4682009,-0.88108337,... 0.79431236,2.380386]
(1 row)
chat_complete
生成文本完成聊天。可以使用可选参数为 LLM 指定自定义参数:_options
\pset tuples_only on
\pset format unaligned
select jsonb_pretty(
ai.ollama_chat_complete
( 'deepseek-r1:32b'
, jsonb_build_array
(
jsonb_build_object('role', 'user', 'content', '一篇好的诗词有什么特点')
)
, chat_options=> jsonb_build_object
( 'seed', 42
, 'temperature', 0.6
)
)
);
返回结果:
{
"done": true,
"model": "deepseek-r1:32b",
"message": {
"role": "assistant",
"images": null,
"content": "<think>\n嗯,用户问一篇好的诗词有什么特点。首先,我得理解用户的需求是什么。可能他正在学习写诗或者想更好地欣赏诗词,所以需要知道评判的标准。
......
总之,一篇好的诗词是意境、语言、情感、构思、结构等多方面共同作用的结果,它既能够打动人心,又具有艺术价值和思想深度。",
"tool_calls": null
},
"created_at": "2025-03-28T09:16:57.852871053Z",
"eval_count": 666,
"done_reason": "stop",
"eval_duration": 233989000000,
"load_duration": 49963427,
"total_duration": 235959942737,
"prompt_eval_count": 13,
"prompt_eval_duration": 873000000
}
可以使用jsonb 运算符和函数来操作返回的jsonb对象, 比如只读取返回的json中的message中的content字段
\pset tuples_only on
\pset format unaligned
select ai.ollama_chat_complete
( 'deepseek-r1:32b'
, jsonb_build_array
( jsonb_build_object('role', 'system', 'content', 'you are a helpful assistant')
, jsonb_build_object('role', 'user', 'content', '一篇好的诗词有什么特点')
)
, chat_options=> jsonb_build_object
( 'seed', 42
, 'temperature', 0.6
)
)->'message'->>'content';
返回结果:
<think>
嗯,用户问一篇好的诗词有什么特点。首先,我得理解用户的需求是什么。可能他正在学习写诗或者想更好地欣赏诗词,所以需要知道评判的标准。
......
最后,主题要鲜明,结构合理,整体上要有和谐统一的感觉。综合这些因素,我就能给出一个全面的回答,帮助用户更好地理解和欣赏诗词。
</think>
一首好的诗词通常具备以下几个特点:
1. **情感真挚**:优秀的诗词往往能够打动人心,因为它表达了作者真实的情感和思想,能够引起读者的共鸣。
......
总之,一篇优秀的诗词是情感、语言、意境与思想的完美结合,能够让人在欣赏艺术美的同时,感受到作者内心深处的情感与思考。
结构化输出
强制LLM使用特定的json格式进行响应
select ai.ollama_chat_complete
( 'deepseek-r1:32b'
, $json$[{"role": "user", "content": "小明今年15岁,身高170cm,体重60千克。返回他的年龄,身高,体重。"}]$json$::jsonb
, response_format=> $json$
{
"type": "object",
"properties": {
"age": {
"type": "integer"
},
"height": {
"type": "integer"
},
"weight": {
"type": "integer"
}
},
"required": [
"age",
"height",
"weight"
]
}
$json$::jsonb
)->'message'->'content'
;
返回结果:
"{ \"age\": 15, \"height\": 170, \"weight\": 60 }\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t"
generate
select ai.ollama_generate
( 'deepseek-r1:32b'
, '写一个python函数求两个数的和'
, embedding_options=> jsonb_build_object
( 'seed', 42
, 'temperature', 0.9
)
)->>'response'
;
返回结果:
<think>
好的,我现在要解决的问题是编写一个Python函数来计算两个数的和。这个问题看起来不难,但我得仔细想想,确保我理解
正确并且能够写出正确的代码。
...
</think>
好的,下面是一个简单的Python函数,用于计算并返回两个数的和:
python
def sum_two_numbers(a, b):
return a + b
# 测试示例
print(sum_two_numbers(3, 5)) # 输出:8
...
ps
查看加载到Ollama内存中的大模型
select * from ai.ollama_ps();
返回结果:
deepseek-r1:32b|deepseek-r1:32b|21931720704|38056bbcbb2d068501ecb2d5ea9cea9dd4847465f1ab88c4d4a412a9f7792717||gguf|qwen2|["qwen2"]|32.8B|Q4_K_M|2025-03-28 15:34:15.227332+08|15522709504
vectorizer
vectorizer可以自动处理表中的数据生成emebedding, 以下是一个具体例子:
建表
CREATE TABLE my_table (
id SERIAL PRIMARY KEY,
title TEXT,
authors TEXT,
contents TEXT,
metadata JSONB
);
插入数据
insert into my_table(title, authors, contents, metadata)
values
('健全社会信用体系,两办作出重要部署', '魏玉坤、魏弘毅', '中共中央办公厅、国务院办公厅近日印发的《关于健全社会信用体系的意见》', '{"tags": ["database", "postgresql", "beginner"], "read_time": 6, "published_date": "2024-05-15"}'),
('华溪村,如今事事有保障!', '贾月洋', '6年过去了,华溪村现在情况怎么样?又是一年春草绿,伴着春风,沐着春雨,记者朝华溪村赶去。', '{"tags": ["blogging", "writing", "tips"], "read_time": 7, "published_date": "2025-03-20"}'),
('建筑物坍塌救援难 缅甸受灾民众:感谢中国救援队帮助', '林曦', '缅甸3月28日发生强震。当地时间3月30日晚上11点20分左右,中国国际救援队乘机抵达缅甸首都内比都机场。', '{"tags": ["AI", "technology", "future"], "read_time": 15, "published_date": "2025-04-01"}'),
('三个关键词 带你看懂“好房子”新标准', '杨潇 陶嘉树', '今天,国家标准《住宅项目规范》正式公布,不仅有层高不低于3米的要求,还有其他许多亮点。', '{"tags": ["health", "nutrition", "lifestyle"], "read_time": 8, "published_date": "2024-10-05"}'),
('从一场座谈到一场会见,总书记两次讲话传递鲜明信息','龚雪辉 刘瑞琳', '2月17日,出席民营企业座谈会。3月28日,会见国际工商界代表。', '{"tags": ["cloud", "technology", "business"], "read_time": 10, "published_date": "2025-03-10"}')
;
创建vectorizer
SELECT ai.create_vectorizer(
'my_table'::regclass,
destination => 'my_table_contents_embeddings',
embedding => ai.embedding_ollama('deepseek-r1:32b', 5120, base_url=>'192.168.4.12:11434'),
chunking => ai.chunking_recursive_character_text_splitter('contents')
);
返回结果:
create_vectorizer
-------------------
5
(1 row)
启动vectorizer worker
生成embedding还需要在外部拉起一个worker来消费表中的数据以生成embedding
python3 lib/python/ud_ai/projects/udai/udai/__main__.py vectorizer worker -d postgresql://unvdb@localhost:5679
可以看到vectorizer worker处理表中的数据
2025-04-01 10:12:49 [info ] running vectorizer vectorizer_id=7
2025-04-01 10:13:06 [info ] finished processing vectorizer items=10 vectorizer_id=7
查看生成的emebedding
SELECT
chunk,
embedding <=> ai.ollama_embed('deepseek-r1:32b', '华溪村', host => 'http://ollama:11434') as distance
FROM my_table_contents_embeddings
ORDER BY distance
LIMIT 5;
返回结果:
| chunk | distance |
|---|---|
| 6年过去了,华溪村现在情况怎么样?又是一年春草绿,伴着春风,沐着春雨,记者朝华溪村赶去。 | 0.20944926109176332 |
| 2月17日,出席民营企业座谈会。3月28日,会见国际工商界代表。 | 0.21668891030818682 |
| 缅甸3月28日发生强震。当地时间3月30日晚上11点20分左右,中国国际救援队乘机抵达缅甸首都内比都机场。 | 0.2537008987073305 |
| 今天,国家标准《住宅项目规范》正式公布,不仅有层高不低于3米的要求,还有其他许多亮点。 | 0.26013424530424534 |
| 中共中央办公厅、国务院办公厅近日印发的《关于健全社会信用体系的意见》 | 0.292180643964869 |
相关参考
create vectorizer配置
SELECT ai.create_vectorizer(
'blog'::regclass,
embedding => ai.embedding_ollama('nomic-embed-text', 768),
chunking => ai.chunking_character_text_splitter('body', 128, 10),
formatting => ai.formatting_python_template('title: $title published: $published $chunk'),
grant_to => ai.grant_to('bob', 'alice')
);
这个函数调用实现了:
为
blog表创建了一个vectorizer使用Ollama中部署的
nomic-embed-text模型来创建768维的embeddings把
body列切分成多个128个字符大小的chunk。chunk间有10个字符的重复每个chunk的格式中加上标题和出版时间
授予
bob和alice权限
参数
| 名字 | 类型 | 默认值 | 是否必须 | 描述 |
|---|---|---|---|---|
| source | regclass | - | ✔ | The source table that embeddings are generated for. |
| destination | name | - | ✖ | Set the name of the table embeddings are stored in, and the view with both the original data and the embeddings. The view is named <destination>, the embedding table is named <destination>_store.You set destination to avoid naming conflicts when you configure additional vectorizers for a source table. |
| embedding | Embedding配置 | - | ✔ | Set how to embed the data. |
| chunking | Chunking配置 | - | ✔ | Set the way to split text data, using functions like ai.chunking_character_text_splitter(). |
| indexing | Indexing配置 | ai.indexing_default() |
✖ | Specify how to index the embeddings. For example, ai.indexing_hnsw(). |
| formatting | Formatting配置 | ai.formatting_python_template() |
✖ | Define the data format before embedding, using ai.formatting_python_template(). |
| scheduling | Scheduling配置 | ai.scheduling_default() |
✖ | Set how often to run the vectorizer. For example, ai.scheduling_timeudb(). |
| target_schema | name | - | ✖ | Specify the schema where the embeddings will be stored. This argument takes precedence over destination. |
| target_table | name | - | ✖ | Specify name of the table where the embeddings will be stored. |
| view_schema | name | - | ✖ | Specify the schema where the view is created. |
| view_name | name | - | ✖ | Specify the name of the view to be created. This argument takes precedence over destination. |
| queue_schema | name | - | ✖ | Specify the schema where the work queue table is created. |
| queue_table | name | - | ✖ | Specify the name of the work queue table. |
| grant_to | GrantTo配置 | ai.grant_to_default() |
✖ | Specify which users should be able to use objects created by the vectorizer. |
| enqueue_existing | bool | true |
✖ | Set to true if existing rows should be immediately queued for embedding. |
Chunking配置
chunking配置函数用于定义文本数据如何被分割成更小的、在生成embedding之前可管理的部分。这一点至关重要,因为许多模型具有输入大小 限制。同时chunking允许在保持上下文的同时处理较大的文本文档。
ai.chunking_character_text_splitter
使用指定的分隔符把文本切分成不同的chunk,可以控制chunk的大小和chunk之间的重复字符数
把my_table的body列使用\n作为分隔符切分成单个chunk128个字符,chunk间有10个字符重复
SELECT ai.create_vectorizer(
'my_table'::regclass,
chunking => ai.chunking_character_text_splitter('body', 128, 10, E'\n'),
-- other parameters...
);
参数
|参数| 类型 | 默认值 | 是否必须 | 描述 |
|-|——|———|-|——————————————————–|
|chunk_column| name | - |✔| The name of the column containing the text to be chunked |
|chunk_size| int | 800 |✖| The maximum number of characters in a chunk |
|chunk_overlap| int | 400 |✖| The number of characters to overlap between chunks |
|separator| text | E’\n\n’ |✖| The string or character used to split the text |
|is_separator_regex| bool | false |✖| Set to true if separator is a regular expression. |
ai.chunking_recursive_character_text_splitter
ai.chunking_recursive_character_text_splitter可以提供更小粒度的控制,可以把文本递归地使用多个分割符来把文本切分成chunk
递归地把
content切分成256个字符大小的chunk,chunk间有20个字符的重复。首先尝试根据’\n’来切分,然后根据空格
SELECT ai.create_vectorizer(
'my_table'::regclass,
chunking => ai.chunking_recursive_character_text_splitter(
'content',
256,
20,
separators => array[E'\n;', ' ']
),
-- other parameters...
);
参数
| 名字 | 类型 | 默认值 | 是否必须 | 描述 |
|——————–|——|———|-|———————————————————-|
| chunk_column | name | - |✔| The name of the column containing the text to be chunked |
| chunk_size | int | 800 |✖| The maximum number of characters per chunk |
| chunk_overlap | int | 400 |✖| The number of characters to overlap between chunks |
| separators | text[] | array[E’\n\n’, E’\n’, ‘.’, ‘?’, ‘!’, ‘ ‘, ‘’] |✖| The string or character used to split the text |
| is_separator_regex | bool | false |✖| Set to true if separator is a regular expression. |
Embedding配置
ai.embedding_ollama使用Ollama中部署的模型来生成embedding
SELECT ai.create_vectorizer(
'my_table'::regclass,
embedding => ai.embedding_ollama(
'nomic-embed-text',
768,
base_url => "http://my.ollama.server:443"
options => '{ "num_ctx": 1024 }',
keep_alive => "10m"
),
-- other parameters...
);
| 名字 | 类型 | 默认值 | 是否必须 | 描述 |
|—————|——-|———|———-|———————————————————————————————————————————————————-|
| model | text | - | ✔ | Specify the name of the embedding model to use. Refer to the [LiteLLM embedding documentation] for an overview of the available providers and models. |
| dimensions | int | - | ✔ | Define the number of dimensions for the embedding vectors. This should match the output dimensions of the chosen model. |
| base_url | text | - | ✖ | Set the base_url of the Ollama API. Note: no default configured here to allow configuration of the vectorizer worker through OLLAMA_HOST env var. |
| options | jsonb | - | ✖ | Configures additional model parameters listed in the documentation for the Modelfile, such as temperature, or num_ctx. |
| keep_alive | text | - | ✖ | Controls how long the model will stay loaded in memory following the request. Note: no default configured here to allow configuration at Ollama-level. | |
Formatting配置
配置生成embedding的时候源表数据的格式
ai.formatting_python_template提供了灵活的构造embedding模型输入的方式。通过合并元数据和加入额外的文本可以大大地增强生成的embedding的质量
默认
SELECT ai.create_vectorizer(
'blog_posts'::regclass,
formatting => ai.formatting_python_template('$chunk'),
-- other parameters...
);
把其他列的信息作为上下文:
把标题和出版日期加到每个chunk的前面,为embedding提供更多的上下文
SELECT ai.create_vectorizer(
'blog_posts'::regclass,
formatting => ai.formatting_python_template('Title: $title\nDate: $published\nContent: $chunk'),
-- other parameters...
);
把多个字段合并:
把作者和类别的信息加入chunk中
SELECT ai.create_vectorizer(
'blog_posts'::regclass,
formatting => ai.formatting_python_template('Author: $author\nCategory: $category\n$chunk'),
-- other parameters...
);
加入一致的结构:
把开始和结束的标记加入到chunk中。对于某些特定的检索任务会非常有用
SELECT ai.create_vectorizer(
'blog_posts'::regclass,
formatting => ai.formatting_python_template('BEGIN DOCUMENT\n$chunk\nEND DOCUMENT'),
-- other parameters...
);
| 名字 | 类型 | 默认值 | 是否必须 | 是否必须 |
|---|---|---|---|---|
| template | string | $chunk |
✔ | A string using Python template strings with $-prefixed variables that defines how the data should be formatted. |
indexing配置
ai.indexing_default()
不自动创建索引
ai.indexing_hnsw
| 名字 | 类型 | 默认值 | 是否必须 | 描述 |
|——|——|———————|-|—————————————————————————————————————-|
|min_rows| int | 100000 |✖| The minimum number of rows before creating the index |
|opclass| text | vector_cosine_ops |✖| The operator class for the index. Possible values are:vector_cosine_ops, vector_l1_ops, or vector_ip_ops |
|m| int | - |✖| Advanced HNSW parameters |
|ef_construction| int | - |✖| Advanced HNSW parameters |
| create_when_queue_empty| boolean | true |✖| Create the index only after all of the embeddings have been generated. |
scheduling配置
ai.scheduling_default()
默认为不调度
ai.scheduling_timeudb
借助timeudb插件的调度能力来实现自动索引构建, 需要先安装timeudb插件
基本用法
SELECT ai.create_vectorizer(
'my_table'::regclass,
scheduling => ai.scheduling_timeudb(),
-- other parameters...
);
自定义调度间隔
SELECT ai.create_vectorizer(
'my_table'::regclass,
scheduling => ai.scheduling_timeudb(interval '1 hour'),
-- other parameters...
);
|名字|类型| 默认值 | 是否必须 | 描述 | |-|-|———|-|——————————————————————————————————————–| |schedule_interval|interval| ‘10m’ |✔| Set how frequently the vectorizer checks for new or updated data to process. |
GrantTo配置
指定哪些用户可以使用由vectorizer创建的对象
例子
SELECT ai.create_vectorizer(
'my_table'::regclass,
grant_to => ai.grant_to('bob', 'alice'),
-- other parameters...
);
Drop Vectorizer
删除vectorizer
删除id为1的vectorizer
SELECT ai.drop_vectorizer(1)
删除id为1的vectorizer同时删除目标表和视图
SELECT ai.drop_vectorizer(1, drop_all=>true);
参数 |名字| 类型 | 默认值 | 是否必须 | 描述 | |-|——|-|-|-| |vectorizer_id| int | -|✔|The identifier of the vectorizer you want to drop| |drop_all| bool | false |✖|true to drop the target table and view as well|
ai.vectorizer_status
vectorizer_status是一个系统表,可以查看vectorizer的状态
SELECT * FROM ai.vectorizer_status;
返回 | id | source_table | target_table | view | pending_items | |—-|————–|————–|——|—————| | 1 | public.blog | public.blog_contents_embedding_store | public.blog_contents_embeddings | 1 |
表定义 | 列名 | 描述 | |—————|———————————————————————–| | id | The unique identifier of this vectorizer | |source_table | The fully qualified name of the source table | |target_table | The fully qualified name of the table storing the embeddings | |view | The fully qualified name of the view joining source and target tables | | pending_items | The number of items waiting to be processed by the vectorizer |
ai.vectorizer_queue_pending
查询在指定vectorizer queue中的元素。当需要定位某个特定vectorizer的时候可以使用此函数
SELECT ai.vectorizer_queue_pending(1)
参数 | 名字 | 类型 | 默认值 | 是否必须 | 描述 | |—————|——|———|———-|———————————————————| | vectorizer_id | int | - | ✔ | The identifier of the vectorizer you want to check | | exact_count | bool | false | ✖ | If true, return exact count. If false, capped at 10,000 |
vectorizer worker
指定worker的睡眠时间,默认为5分钟
python3 lib/python/ud_ai/projects/udai/udai/__main__.py vectorizer worker -d postgresql://unvdb@localhost:5679 --poll-interval=10m
多线程处理一个vectorizer queue
python3 lib/python/ud_ai/projects/udai/udai/__main__.py vectorizer worker -d postgresql://unvdb@localhost:5679 -c=3
AGE
GraphRAG
传统 RAG(检索增强生成)通常使用向量数据库检索相关文档来提高大模型的问题回答准确性,但是基于向量的 RAG 不能够很好的表达事物之间的联系。而GraphRAG基于知识图谱的检索增强生成,能够提供结构化检索能力,将图作为传统的RAG多路召回的一环,使知识表达更易解释、对复杂关系更易支持。
AGE
AGE插件可以:
在unvdb-tv上增加图数据库的能力
在unvdb-tv上执行openCypher的查询
验证安装
oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+------------+----------+--------------+----------------+------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------------------------------------------------------------------------------------------
12777 | plpgsql | 10 | 11 | f | 1.0 |
|
38373 | age | 10 | 38372 | f | 1.5.0 | {38374,38386}
| {"",""}
(2 rows)
基本操作
创建一个图
SELECT create_graph('graph_name');
创建一个带标签和属性的顶点
SELECT *
FROM cypher('graph_name', $$
CREATE (:label {property:"Node A"})
$$) as (v agtype);
SELECT *
FROM cypher('graph_name', $$
CREATE (:label {property:"Node B"})
$$) as (v agtype);
在两个结点之间创建一条边,同时设置属性
SELECT *
FROM cypher('graph_name', $$
MATCH (a:label), (b:label)
WHERE a.property = 'Node A' AND b.property = 'Node B'
CREATE (a)-[e:RELTYPE {property:a.property + '<->' + b.property}]->(b)
RETURN e
$$) as (e agtype);
查询连接的结点
SELECT * from cypher('graph_name', $$
MATCH (V)-[R]-(V2)
RETURN V,R,V2
$$) as (V agtype, R agtype, V2 agtype);
age使用示例
使用千问大模型和age的能力实现一个简单的GraphRAG, 快速构建知识图谱和检索。
前置要求
安装下列python依赖
pip install -U langchain_community langchain langgraph langchain-ollama langchain-experimental langchain-openai
初始化大模型
from langchain_community.llms import Tongyi
import os
os.environ["DASHSCOPE_API_KEY"] = "sk-**"
graph_llm =Tongyi(model="qwen-plus", temperature=0, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
通过大模型提取文本数据中的实体和关系
from langchain_core.documents import Document
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_transformer = LLMGraphTransformer(
llm=graph_llm,
allowed_nodes=["Person", "Company", "Technology", "Product", "Industry"],
allowed_relationships=["FOUNDED", "DEVELOPED", "USES", "INDUSTRY_IN", "INVESTED_IN"]
)
text = """
Elon Musk, born in 1971 in Pretoria, co-founded Tesla in 2003 with Martin Eberhard.
As CEO of Tesla, he led the development of the Model S electric car which uses autonomous driving technology.
His other venture SpaceX, founded in 2002, created the Starship rocket utilizing methane-liquid oxygen propulsion technology.
Both companies operate in the automotive and aerospace industries respectively."""
documents = [Document(page_content=text)]
graph_documents = llm_transformer.convert_to_graph_documents(documents)
print(f"Nodes from graph doc:{graph_documents[0].nodes}")
print(f"Relationships from graph doc:{graph_documents[0].relationships}")
输出:
Nodes from graph doc:[Node(id='Elon Musk', type='Person', properties={}), Node(id='Starship rocket', type='Product', properties={}), Node(id='aerospace', type='Industry', properties={}), Node(id='Model S electric car', type='Product', properties={}), Node(id='Tesla', type='Company', properties={}), Node(id='SpaceX', type='Company', properties={}), Node(id='autonomous driving technology', type='Technology', properties={}), Node(id='automotive', type='Industry', properties={}), Node(id='methane-liquid oxygen propulsion technology', type='Technology', properties={})]
Relationships from graph doc:[Relationship(source=Node(id='Elon Musk', type='Person', properties={}), target=Node(id='Tesla', type='Company', properties={}), type='FOUNDED', properties={}), Relationship(source=Node(id='Elon Musk', type='Person', properties={}), target=Node(id='SpaceX', type='Company', properties={}), type='FOUNDED', properties={}), Relationship(source=Node(id='Tesla', type='Company', properties={}), target=Node(id='Model S electric car', type='Product', properties={}), type='DEVELOPED', properties={}), Relationship(source=Node(id='Model S electric car', type='Product', properties={}), target=Node(id='autonomous driving technology', type='Technology', properties={}), type='USES', properties={}), Relationship(source=Node(id='SpaceX', type='Company', properties={}), target=Node(id='Starship rocket', type='Product', properties={}), type='DEVELOPED', properties={}), Relationship(source=Node(id='Starship rocket', type='Product', properties={}), target=Node(id='methane-liquid oxygen propulsion technology', type='Technology', properties={}), type='USES', properties={}), Relationship(source=Node(id='Tesla', type='Company', properties={}), target=Node(id='automotive', type='Industry', properties={}), type='INDUSTRY_IN', properties={}), Relationship(source=Node(id='SpaceX', type='Company', properties={}), target=Node(id='aerospace', type='Industry', properties={}), type='INDUSTRY_IN', properties={})]
持久化图数据
from langchain_community.graphs.age_graph import AGEGraph
conf = {
"database": "unvdb",
"user": "unvdb",
"password": "",
"host": "localhost",
"port": 5678,
"sslmode": "disable"
}
graph=AGEGraph(graph_name='graph',conf=conf,create=True)
graph.add_graph_documents(graph_documents)
graph.refresh_schema()
提取问题关键词并生成图检索语句
增加提示词,提高大模型生成的图查询语句的准确性
from langchain_core.prompts import PromptTemplate
from langchain.chains import GraphCypherQAChain
cypher_prompt = PromptTemplate(
template="""你是 AGE Cypher 查询生成的专家。 使用以下架构生成一个 Cypher 查询,以回答给定问题。 不要出现name和properties和cypher
架构: {schema}
问题: {question}
Cypher 查询: """,
input_variables=["schema", "question"],
)
chain = GraphCypherQAChain.from_llm(
graph_llm, graph=graph, verbose=True, allow_dangerous_requests=True, cypher_validation=True, return_intermediate_steps=True,cypher_prompt=cypher_prompt)
#question = "Who get Nobel Prize ?"
question = "Who founded tesla and SpaceX?"
result = chain.invoke({"query": question})
输出:
> Entering new GraphCypherQAChain chain...
Generated Cypher:
MATCH (p:Person)-[:FOUNDED]->(c:Company)
Add document for mcp
WHERE c.id = "Tesla" OR c.id = "SpaceX"
RETURN DISTINCT p.id
Full Context:
[{'p_id': 'Elon Musk'}]
大模型根据检索出来的图数据生成回答
prompt = PromptTemplate(
template="""You are an assistant for question-answering tasks. Use the following pieces of retrieved context from a graph database to answer the question. If you don't know the answer, just say that you don't know. Use two sentences maximum and keep the answer concise: Question: {question} Graph Context: {graph_context} Answer: """,
input_variables=["question", "graph_context"],
)
from langchain_core.output_parsers import StrOutputParser
composite_chain = prompt | graph_llm |StrOutputParser()
answer = composite_chain.invoke( {"question": question, "graph_context": result})
print(answer)
输出:
> Finished chain.
Elon Musk founded Tesla and SpaceX.
MCP
MCP简介
MCP 是一个开放协议,它为应用程序向 LLM 提供上下文的方式进行了标准化。可以将 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 为设备连接各种外设和配件提供了标准化的方式一样,MCP 为 AI 模型连接各种数据源和工具提供了标准化的接口。 UNVDB-TV可作为数据源通过MCP协议进行访问。
MCP概念
MCP Hosts: 如 Claude Desktop、IDE 或 AI 工具,希望通过 MCP 访问数据的程序
MCP Clients: 维护与服务器一对一连接的协议客户端
MCP Servers: 轻量级程序,通过标准的 Model Context Protocol 提供特定能力
使用示例
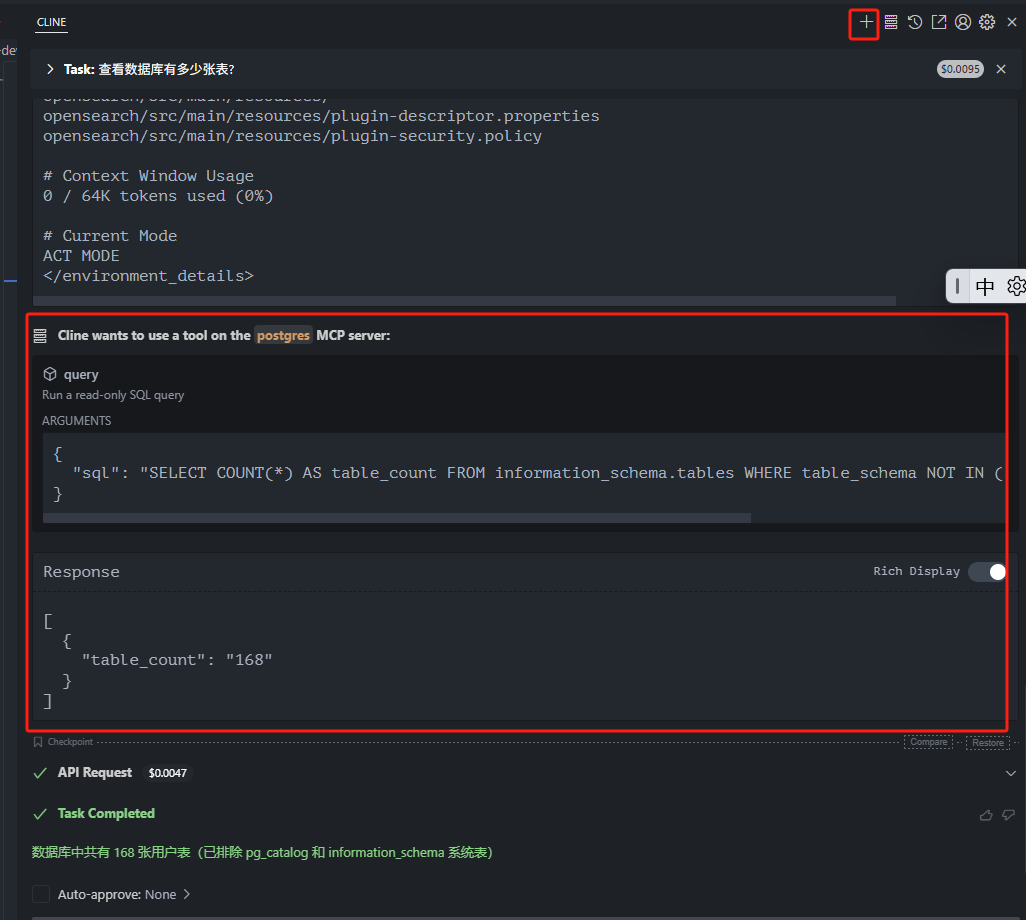
使用VSCode的Cline插件操作unvdb并列出数据库中表的数量
操作流程
cline配置api key
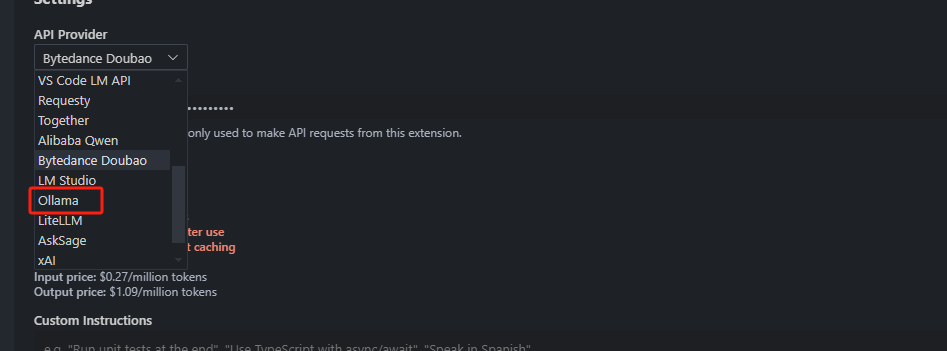
cline配置MCP server
MCP Server的通信方式有:
stdio
sse
stdio
需先安装Docker
{
"mcpServers": {
"postgres": {
"command": "docker",
"args": [
"run",
"-i",
"--rm",
"mcp/postgres",
"postgresql://unvdb:5678/unvdb"]
}
}
}
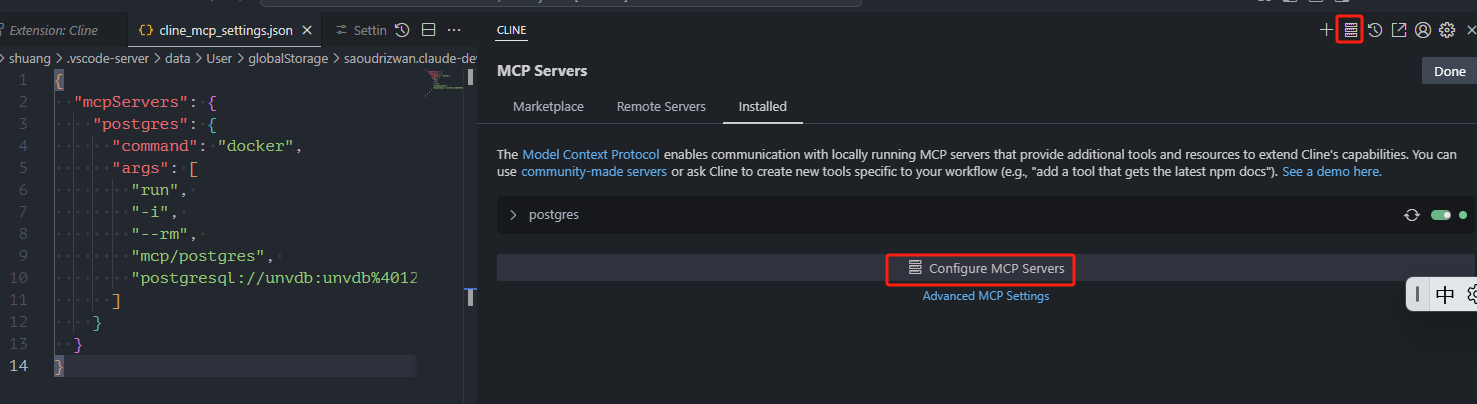
sse
参考pg-mcp-server启动mcp-server
client配置MCP server
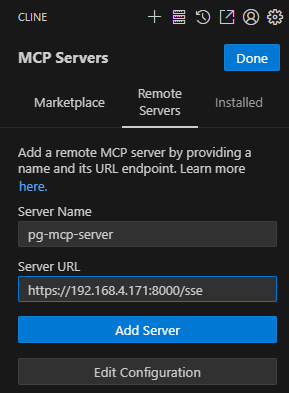
task提问