产品介绍
UDB-DS 是一款低成本、高性能的时序数据库。它可以解决企业组建物联网大数据平台管理时序数据时所遇到的应用场景复杂、数据体量大、采样频率高、数据乱序多、数据处理耗时长、分析需求多样、存储与运维成本高等多种问题。
1. 产品体系
UDB-DS 体系由若干个组件构成,帮助用户高效地管理和分析物联网产生的海量时序数据。
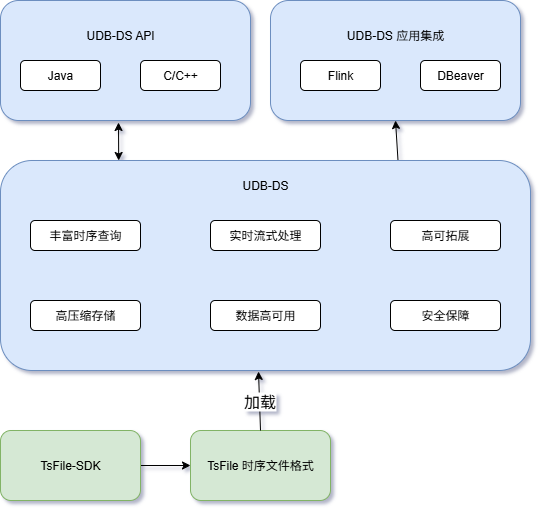
其中:
时序数据库(UDB-DS ):时序数据存储的核心组件,其能够为用户提供高压缩存储能力、丰富时序查询能力、实时流处理能力,同时具备数据的高可用和集群的高扩展性,并在安全层面提供全方位保障。
时序数据标准文件格式(Apache TsFile):该文件格式是一种专为时序数据设计的存储格式,可以高效地存储和查询海量时序数据。目前 UDB-DS 等模块的底层存储文件均由 Apache TsFile 进行支撑。通过 TsFile,用户可以在采集、管理、应用&分析阶段统一使用相同的文件格式进行数据管理,极大简化了数据采集到分析的整个流程,提高时序数据管理的效率和便捷度。
2. UDB-DS 整体架构
下图展示了一个常见的 UDB-DS 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式: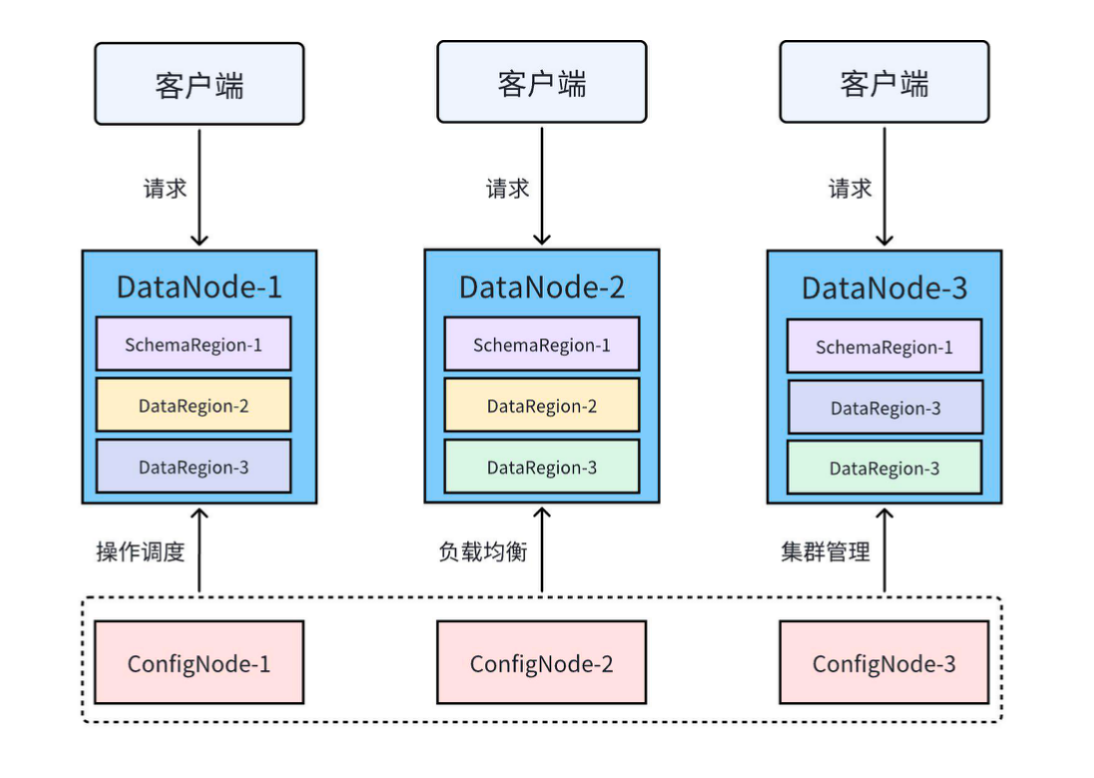
3. 产品特性
UDB-DS 具备以下优势和特性:
低硬件成本的存储解决方案:支持高压缩比的磁盘存储,无需区分历史库与实时库,数据统一管理
层级化的测点组织管理方式:支持在系统中根据设备实际层级关系进行建模,以实现与工业测点管理结构的对齐,同时支持针对层级结构的目录查看、检索等能力
高通量的数据读写:支持百万级设备接入、数据高速读写、乱序/多频采集等复杂工业读写场景
丰富的时间序列查询语义:支持时序数据原生计算引擎,支持查询时时间戳对齐,提供近百种内置聚合与时序计算函数,支持面向时序特征分析和AI能力
高可用的分布式系统:支持HA分布式架构,系统提供7*24小时不间断的实时数据库服务,一个物理节点宕机或网络故障,不会影响系统的正常运行;支持物理节点的增加、删除或过热,系统会自动进行计算/存储资源的负载均衡处理;支持异构环境,不同类型、不同性能的服务器可以组建集群,系统根据物理机的配置,自动负载均衡
极低的使用&运维门槛:支持类 SQL 语言、提供多语言原生二次开发接口、具备控制台等完善的工具体系
丰富的生态环境对接:支持Hadoop、Spark等大数据生态系统组件对接,支持Grafana、Thingsboard、DataEase等设备管理和可视化工具