九有数据库UDB-TX分布式版本(分析型)管理手册
深圳九有数据库有限公司 2024年7月
简介
九有数据库UDB-TX分布式版本(分析型)产品是九有数据库自主研发的分析型分布式关系数据库,本产品具有以下主要技术特性:
分布式架构:
支持将数据分布在多个节点上,通过并行查询和负载均衡来提升性能。
数据仓库功能:
设计用于分析和大数据处理,支持复杂的查询和数据分析任务。
SQL 支持:
兼容 PostgreSQL 的 SQL 标准,提供丰富的 SQL 查询功能。
列存储功能:
支持列存储格式,用于优化分析查询的性能。
MPP(大规模并行处理):
支持大规模并行处理,多节点同时处理数据,提高查询性能。
数据分区:
能够对数据进行分区,以优化性能和管理大数据集。
高可用性:
提供高可用性解决方案,支持数据冗余与故障恢复。
安全性:
支持多种身份验证机制、访问控制及数据加密功能,保障数据安全。
外部表和数据导入:
支持外部表功能,可以直接查询外部数据源,简化数据集成。
丰富的扩展性:
支持用户自定义函数(UDF)、存储过程以及插件架构,提升系统功能的扩展性。
易于管理:
提供管理工具和监控功能,便于数据库的维护和性能优化。
连接和兼容性:
提供与多种 BI 工具和数据处理框架的连接,增强数据的可访问性和分析能力。
这些特性使得九有数据库UDB-TX分布式版本在数据分析、数据仓库和大数据处理领域具有很强的竞争力,适合处理海量数据和支持复杂分析需求的应用场景。
安装
配置主机名
配置所有主机名及IP,重启机器或执行hostname命令使主机名立即生效
echo "cn1" > /etc/hostname
echo "10.0.0.3 cn1
10.0.0.4 dn1
10.0.0.5 dn2
" >> /etc/hosts
#
hostname cn1
...
创建用户
所有主机创建相同用户, 并添加到sudoers(安装期间必须NOPASSWD),切换到新建的用户配置协调节点主机到所有主机ssh免密
useradd -m -d /path/to/userhome udbda
echo "udbda ALL=(ALL) NOPASSWD: ALL >> /etc/sudoers"
su - udbda
ssh-keygen
ssh-copy-id cn1
ssh-copy-id dn1
ssh-copy-id dn2
安装准备
上传安装包到协调节点主机并解压,执行Rhel-Rocky.bash优化各主机操作系统配置参数
#1.上传安装包到协调节点主机并解压
tar -xzvf udb-da-22.4-linux-x64.tar.gz -C /data
#2.设置环境变量
source /data/unvdb_path.sh
#拷贝脚本Rhel-Rocky.bash到所有节点
echo "cn1
dn1
dn2
" > allhosts
udsync -f allhosts /data/Rhel-Rocky.bash =: /data/Rhel-Rocky.bash
#所有主机执行Rhel-Rocky.bash脚本
udssh -f allhosts 'bash /data/Rhel-Rocky.bash'
执行安装
执行udb_tool.py安装脚本, 按提示步骤选择安装路径、输入主机列表等信息
python3 /data/udb_tool.py

选择是否安装协调节点Standby节点,是否安装数据节点镜像节点,每台主机安装数据节点实例个数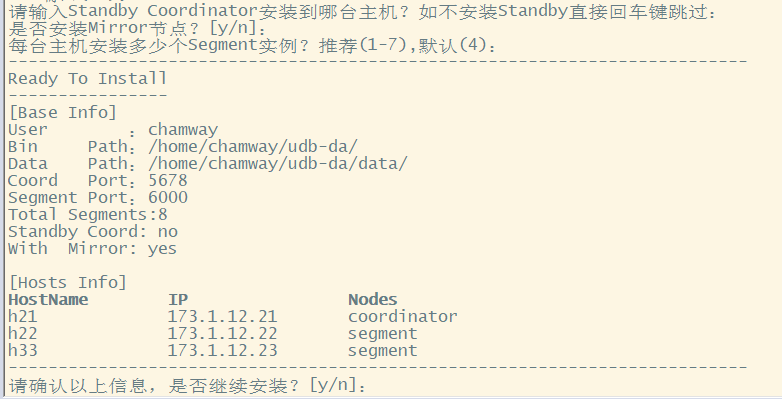
完成安装后,你将看到如下安装成功提示,建议将环境变量udb_env.sh添加到~/.bashrc中
管理员指南
产品架构
九有数据库UDB-TX分布式是一种大规模并行处理(MPP)数据库服务器,其架构特别针对管理大规模分析型数据仓库以及商业智能工作负载而设计。
MPP(也被称为shared nothing架构)指有两个或者更多个处理器协同执行一个操作的系统,每一个处理器都有其自己的内存、操作系统和磁盘。UDB-TX使用这种高性能系统架构来分布数T字节数据仓库的负载并且能够使用系统的所有资源并行处理一个查询。
UDB-TX分布式版本数据库是基于九有数据库UDB-TX集中式版本的。它本质上是多个UDB-TX集中式版本面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS)。它基于UDB-TX集中式版本开发,其SQL支持、特性、配置选项和最终用户功能在大部分情况下和UDB-TX集中式版非常相似。
UDB-TX分布式数据库可以使用追加优化(append-optimized,AO)的存储个事来批量装载和读取数据,并且能提供HEAP表上的性能优势。追加优化的存储为数据保护、压缩和行/列方向提供了校验和。行式或者列式追加优化的表都可以被压缩。
UDB-TX分布式数据库和UDB-TX单机版本数据库的主要区别在于: 在基于UDB-TX单机版本查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划。 UDB-TX分布式数据库可以使用追加优化的存储。 UDB-TX分布式数据库可以选用列式存储,数据在逻辑上还是组织成一个表,但其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。列式存储只能和追加优化表一起使用。列式存储是可压缩的。当用户只需要返回感兴趣的列时,列式存储可以提供更好的性能。所有的压缩算法都可以用在行式或者列式存储的表上,但是行程编码(RLE)压缩只能用于列式存储的表。UDB-TX分布式数据库在所有使用列式存储的追加优化表上都提供了压缩。 为了支持UDB-TX分布式数据库的并行结构,UDB-TX集中式版本的内部已经被修改或者增补。例如,系统目录、优化器、查询执行器以及事务管理器组件都已经被修改或者增强,以便能够在所有的并行PostgreSQL数据库实例之上同时执行查询。UDB-TX分布式的Interconnect(网络层)允许在不同的UDB-TX集中式的实例之间通讯,让系统表现为一个逻辑数据库。
UDB-TX分布式数据库也可以使用声明式分区和子分区来隐式地生成分区约束。
UDB-TX分布式数据库也包括为针对商业智能(BI)负载优化UDB-TX集中式数据库而设计的特性。例如,UDB-TX分布式增加了并行数据装载(外部表)、资源管理、查询优化以及存储增强,这些在UDB-TX集中式中都是有所差异的。
UDB-TX分布式数据库的查询使用一种火山式查询引擎模型,其中的执行引擎拿到一个执行计划并且用它产生一棵物理操作符树,然后通过物理操作符计算表,最后返回结果作为查询响应。
UDB-TX分布式数据库通过将数据和处理负载分布在多个服务器或者主机上来存储和处理大量的数据。UDB-TX分布式数据库是一个由基于UDB-TX集中式的数据库组成的阵列,阵列中的数据库工作在一起呈现了一个单一数据库的景象。协调节点是UDB-TX分布式数据库系统的入口。客户端会连接到这个数据库实例并且提交SQL语句。协调节点会协调与系统中其他称为数据节点的数据库实例一起工作,数据节点负责存储和处理数据。
图 1. 简化的UDB-TX分布式数据库架构
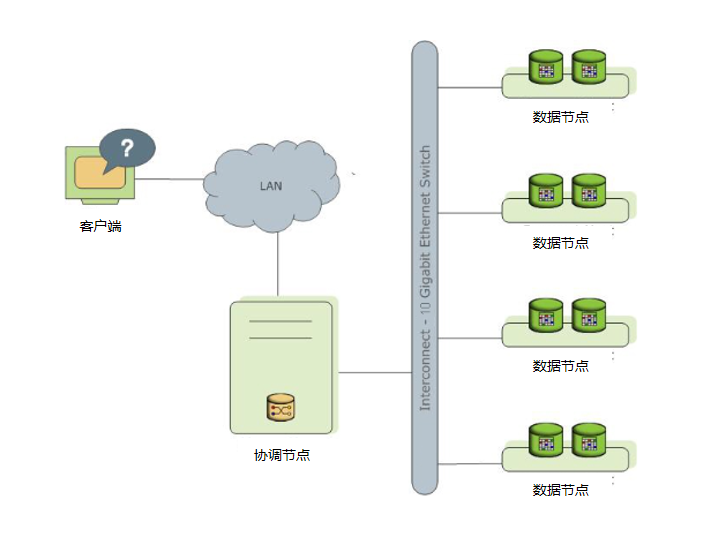
关于UDB-TX分布式的协调节点(CoordinateNode)
UDB-TX分布式数据库的协调节点是整个UDB-TX分布式数据库系统的入口,它接受连接和SQL查询并且把工作分布到数据节点实例上。
UDB-TX分布式数据库的最终用户与UDB-TX分布式数据库(通过协调节点)交互时,会觉得他们是在与一个典型的PostgreSQL数据库交互。他们使用诸如ud_sql之类的客户端或者JDBC、ODBC、libpq等应用编程接口(API)连接到数据库。
协调节点是全局系统目录的所在地。全局系统目录是一组包含了有关UDB-TX分布式数据库系统本身的元数据的系统表。协调节点上不包含任何用户数据,数据只存在于数据节点之上。协调节点会认证客户端连接、处理到来的SQL命令、在数据节点之间分布工作负载、协调每一个数据节点返回的结果以及把最终结果呈现给客户端程序。
UDB-TX分布式数据库使用预写式日志(WAL)来实现主/备镜像。在基于WAL的日志中,所有的修改都会在应用之前被写入日志,以确保对于任何正在处理的操作的数据完整性。
关于UDB-TX分布式的数据节点(DataNode)
UDB-TX分布式数据库的数据节点实例是独立的UDB-TX集中式数据库,每一个都存储了数据的一部分并且执行查询处理的主要部分。
当一个用户通过UDB-TX分布式的协调节点连接到数据库并且发出一个查询时,在每一个数据节点数据库上都会创建一些进程来处理该查询的工作。更多有关查询处理的内容,请见关于UDB-TX分布式的查询处理。
用户定义的表及其索引会分布在UDB-TX分布式数据库系统中可用的数据节点上,每一个数据节点都包含数据的不同部分。服务于数据节点数据的数据库服务器进程运行在相应的数据节点实例之下。用户通过协调节点与一个UDB-TX分布式数据库系统中的数据节点交互。
数据节点运行在被称作数据节点主机的服务器上。一台数据节点主机通常运行2至8个UDB-TX分布式的数据节点,这取决于CPU核数、RAM、存储、网络接口和工作负载。数据节点主机预期都以相同的方式配置。从UDB-TX分布式数据库获得最佳性能的关键在于在大量能力相同的数据节点之间平均地分布数据和工作负载,这样所有的数据节点可以同时开始为一个任务工作并且同时完成它们的工作。
关于UDB-TX分布式的Interconnect
Interconect是UDB-TX分布式数据库架构中的网络层。
Interconnect指的是数据节点之间的进程间通信以及这种通信所依赖的网络基础设施。UDB-TX分布式的Interconnect采用了一种标准的以太交换网络。出于性能原因,推荐使用万兆网或者更快的系统。
默认情况下,Interconnect使用带流控制的用户数据包协议(UDPIFC)在网络上发送消息。UDB-TX分布式软件在UDP之上执行包验证。这意味着其可靠性等效于传输控制协议(TCP)且性能和可扩展性要超过TCP。如果Interconnect被改为TCP,UDB-TX分布式数据库会有1000个数据节点实例的可扩展性限制。对于Interconnect的默认协议UDPIFC则不存在这种限制。
管理UDB-TX分布式系统
启动和停止UDB-TX分布式数据库
在一个UDB-TX分布式数据库DBMS中,数据库服务器实例(协调节点和所有的数据节点)在系统中所有的主机上一起被启动或者停止,它们以这样一种方式作为一个统一的DBMS工作。
由于一个UDB-TX分布式数据库系统分布在很多机器上,启动和停止一个UDB-TX分布式数据库系统的过程与UDB-TX集中式DBMS不同。
分别使用gpstart和gpstop工具来启动和停止UDB-TX分布式数据库。这些工具位于UDB-TX分布式数据库的协调节点主机的$GPHOME/bin目录中。
重要: 不要发出kill命令来结束任何Postgres进程。而是使用数据库命令pg_cancel_backend()。 发出kill -9或者kill -11可能会导致数据库损坏并且妨碍对根本原因的分析。
有关gpstart和gpstop的信息请见UDB-TX分布式数据库工具指南。
启动UDB-TX分布式数据库
通过在协调节点实例上运行gpstart可以启动一个初始化好的UDB-TX分布式数据库系统。
可以使用gpstart工具来启动一个已经由gpinitsystem工具初始化好但已经被gpstop工具停止的UDB-TX分布式数据库系统。gpstart通过启动UDB-TX分布式数据库集群上所有的Postgres数据库实例来启动UDB-TX分布式数据库。gpstart会精心安排这一过程并且以并行的方式执行它。 在协调节点主机上运行gpstart启动UDB-TX分布式数据库: $ gpstart
重启UDB-TX分布式数据库
停止UDB-TX分布式数据库系统然后重新启动它。
带-r选项的gpstop工具可以停止UDB-TX分布式数据库,并且在关闭完成后重新启动UDB-TX分布式数据库。 要重启UDB-TX分布式数据库,在协调节点主机上输入下面的命令: $ gpstop -r
仅重新载入配置文件更改
重新载入对UDB-TX分布式数据库配置文件的更改而不中断系统。
gpstop工具可以在不中断服务的前提下重新载入对pg_hba.conf配置文件和协调节点上postgresql.conf、pg_hba.conf文件中运行时参数的更改。活动会话将会在它们重新连接到数据库时使用这些更新。很多服务器配置参数需要完全重启系统(gpstop -r)才能激活。有关服务器配置参数的信息请见UDB-TX分布式数据库参考指南。 使用gpstop工具重新载入配置文件更改而不关闭系统: $ gpstop -u
以维护模式启动协调节点
只启动协调节点来执行维护或者管理任务而不影响数据节点上的数据。
例如,可以用维护模式连接到一个只在协调节点实例上的数据库并且编辑系统目录设置。更多有关系统目录表的信息请见UDB-TX分布式数据库参考指南。 使用-m模式运行gpstart: $ gpstart -m
以维护模式连接到协调节点进行目录维护。例如:
$ PGOPTIONS=’-c gp_session_role=utility’ ud_sql postgres
在完成管理任务后,停止处于维护模式的额协调节点。然后以生产模式重启它。 $ gpstop -mr 警告: 对维护模式连接的不当使用可能会导致不一致的系统状态。只有技术支持才应该执行这一操作。
停止UDB-TX分布式数据库
gpstop工具可以停止或者重启UDB-TX分布式数据库系统,它总是运行在协调节点主机上。当被激活时,gpstop会停止系统中所有的进程,包括协调节点和所有的数据节点实例。gpstop工具使用一种默认的最多64个并行工作者线程的方式来关闭构成整个UDB-TX分布式数据库集群的UDB-TX实例。系统在关闭之前会等待所有的活动事务完成。要立即停止UDB-TX分布式数据库,可以使用快速模式。 要停止UDB-TX分布式数据库: $ gpstop
要以快速模式停止UDB-TX分布式数据库: $ gpstop -M fast 默认情况下,如果有任何客户端连接存在,就不允许关闭UDB-TX分布式数据库。使用-M fast选项可以在关闭前回滚所有正在进行中的事务并且中断所有连接。
访问数据库
建立一个数据库会话
用户可以通过使用一种UDB-TX集中式版本兼容的客户端程序连接到UDB-TX分布式数据库,例如ud_sql。用户和管理员总是通过协调节点连接到UDB-TX分布式数据库。数据节点不能接受客户端连接。
为了建立一个到UDB-TX分布式数据库协调节点的连接,用户将需要知道下列连接信息并且相应地配置用户的客户端程序。
表 1. 连接参数
| 连接参数 | 描述 | 环境变量 |
|---|---|---|
| 应用名称 | 连接到数据库的应用名称,保存在application_name连接参数中。默认值是ud_sql。 | $PGAPPNAME |
| 数据库名 | 用户想要连接的数据库名称。对于一个刚初始化的系统,第一次可使用postgres数据库来连接。 | $PGDATABASE |
| 主机名 | UDB-TX分布式数据库的协调节点的主机名。默认主机是本地主机。 | $PGHOST |
| 端口 | UDB-TX分布式数据库的协调节点实例所运行的端口号。默认为5432。 | $PGPORT |
| 用户名 | 要以其身份连接的数据库用户(角色)名。这不需要和用户的操作系统用户名一样。如果用户不确定用户的数据库用户名是什么,请咨询用户的UDB-TX分布式管理员。注意每一个UDB-TX分布式数据库系统都有一个在初始化时自动创建的超级用户账号。这个账号的名称和初始化UDB-TX分布式系统的用户(最有代表性的是gpadmin)的操作系统用户名相同。 | $PGUSER |
用ud_sql连接提供了连接到UDB-TX分布式数据库的示例命令。
支持的客户端应用
用户可以使用多种客户端应用连接到UDB-TX分布式数据库:
用户的UDB-TX分布式安装中已经提供了一些UDB-TX分布式数据库客户端应用。 ud_sql客户端应用提供了一种对UDB-TX分布式数据库的交互式命令行接口。 使用标准的数据库应用程序接口(如ODBC和JDBC),用户可以创建他们自己的客户端应用来接入到UDB-TX分布式数据库。 大部分使用ODBC和JDBC等标准数据库接口的客户端工具都可以被配置来连接到 UDB-TX分布式数据库。
UDB-TX分布式数据库客户端应用
UDB-TX分布式数据库安装后就会带有一些客户端工具应用,它们位于用户的UDB-TX分布式数据库协调节点主机安装的$GPHOME/bin 目录中。下列是最常用的客户端工具应用:
表 1. 最常用的客户端应用 | 名称 | 用法 | | :——— | :—————————– | | createdb | 创建一个新数据库 | | createlang | 定义一种新的过程语言 | | createuser | 定义一个新的数据库角色 | | dropdb | 移除一个数据库 | | droplang | 移除一种过程语言 | | dropuser | 移除一个角色 | | ud_sql | PostgreSQL交互式终端 | | reindexdb | 对一个数据库重建索引 | | vacuumdb | 对一个数据库进行垃圾收集和分析 |
在使用这些客户端应用时,用户必须通过UDB-TX分布式的协调节点实例连接到一个数据库。用户将需要知道目标数据库的名称、协调节点的主机名和端口号,还有用于连接的数据库用户名。这些信息可以在命令行上分别用选项 -d、-h、-p和-U来提供。如果找到不属于任何一个选项的参数,它将被首先解释为数据库名。
所有这些选项都有默认值,如果该选项没有被指定就会使用其默认值。默认主机是本地主机。默认端口号是5432。默认用户名是用户的操作系统用户名,同时也是默认的数据库名。注意操作系统用户名和UDB-TX分布式数据库用户名并不需要一样。
如果默认值和实际情况不同,用户可以设置环境变量 PGDATABASE、PGHOST、PGPORT和 PGUSER为合适的值,或者使用一个ud_sql ~/.pgpass文件来包含常用的口令。
用ud_sql连接
依靠用户使用的默认值或者已经设置的环境变量,下面的例子展示了如何通过ud_sql来访问数据库:
$ ud_sql -d gpdatabase -h 协调节点_host -p 5432 -U gpadmin
$ ud_sql gpdatabase $ ud_sql 如果还没有创建一个用户定义的数据库,用户可以通过连接到postgres数据库来访问系统。例如: $ ud_sql postgres 在连接到一个数据库后,ud_sql提供了一个提示符,提示符由ud_sql当前连接的数据库名后面加上=>(如果用户是数据库超级用户则会是=#)构成。例如:
gpdatabase=> 在提示符处,用户可以输入SQL命令。为了能把一个SQL命令发送到服务器并且执行,SQL命令必须以一个;(分号)结束。例如:
=> SELECT * FROM mytable;
数据库应用接口
用户可能想要开发用户自己的客户端应用接入到UDB-TX分布式数据库。由于UDB-TX采用兼容PostgreSQL的接口。 而PostgreSQL为最常用的数据库应用编程接口(API)提供了数种数据库驱动,这些同样也能在UDB-TX分布式数据库中使用。这些驱动作为一个独立的下载提供。每一种驱动(除了随UDB-TX提供的libpq)都是一个独立的UDB-TX开发项目并且必须被下载、安装并且配置以连接到UDB-TX分布式数据库。可用的驱动如下:
表 1. UDB-TX分布式数据库接口 | API | PostgreSQL兼容的驱动 | 下载链接 | | :————– | :————- | :—————————————————- | | ODBC | psqlODBC | https://odbc.postgresql.org/. | | JDBC | pgjdbc | https://jdbc.postgresql.org/ | | Perl DBI | pgperl | http://search.cpan.org/dist/DBD-Pg/ | | Python DBI | pygresql | http://www.pygresql.org/ | | libpq C Library | libpq | https://www.postgresql.org/docs/8.3/static/libpq.html |
用API访问UDB-TX分布式数据库的一般步骤是:
从合适的来源下载用户的编程语言平台以及相应的API。例如,用户可以从Oracle得到Java开发工具包(JDK)和JDBC API。 根据API规范编写用户的客户端应用。在编程时,注意UDB-TX分布式数据库中的SQL支持这样用户才不会使用不被支持的SQL语法。
连接问题的发现及解决
很多事情都可能阻止客户端应用成功地连接到UDB-TX分布式数据库。这个主题解释了一些常见的连接问题的原因以及如何改正它们。
表 1. 常见连接问题
| 问题 | 解决方案 |
| :—————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————— | :———————————————————————————————————————————————————————————————————————————————————————————————- |
| 没有用于主机或者用户的pg_hba.conf条目 | 要允许UDB-TX分布式数据库接受远程客户端连接,用户必须配置用户的UDB-TX分布式数据库的协调节点实例,这样来自于客户端主机和数据库用户的连接才会被允许连接到UDB-TX分布式数据库。这可以通过在pg_hba.conf配置文件(位于协调节点实例的数据目录中)中增加合适的条目就能做到。更多详细的信息请见允许到UDB-TX分布式的连接。 |
| UDB-TX分布式数据库没有运行 | UDB-TX分布式数据库的协调节点实例没有运行,用户将无法连接。用户可以通过在UDB-TX分布式的协调节点主机上运行gpstate工具来验证UDB-TX分布式数据库系统是否正常运行。 |
| 网络问题 Interconnect 超时 | 如果用户从一个远程客户端连接到UDB-TX分布式的协调节点主机,网络问题可能阻止连接(例如,DNS主机名解析问题、主机系统没有运行等等)。为了确认网络问题不是原因,可尝试从远程客户端主机连接到UDB-TX分布式的协调节点主机。例如: ping hostname . 如果系统不能解析主机名和UDB-TX分布式数据库所涉及的主机的IP地址,查询和连接将会失败。对于某些操作,到UDB-TX分布式数据库协调节点的连接会使用localhost而其他连接使用真实的主机名,因此用户必须能解析两者。如果用户遇到这种错误,首先确认用户能够从协调节点主机通过网络连接到UDB-TX分布式数据库阵列中的每一台主机。在协调节点和所有数据节点的/etc/hosts文件中,确认有UDB-TX分布式数据库阵列所涉及所有主机的正确的主机名和IP地址。IP 127.0.0.1必须解析为localhost。 |
| 已有太多客户端 | 默认情况下,UDB-TX分布式数据库被配置为在协调节点和每个数据节点上分别允许最多250和750个并发用户连接。导致该限制会被超过的连接尝试将被拒绝。这个限制由UDB-TX分布式数据库协调节点的postgresql.conf配置文件中的max_connections参数控制。如果用户为协调节点更改了这个设置,用户还必须在数据节点上做出适当的更改。 |
配置UDB-TX分布式数据库系统
影响UDB-TX分布式数据库行为的服务器配置参数。 它们是PostgreSQL的“大统一配置”系统的一部分,因此它们有时也被称为“GUC”。大部分的UDB-TX分布式数据库服务器配置参数和UDB-TX集中式版本的配置参数相同,但是也有一些是UDB-TX分布式所特有的。
关于UDB-TX分布式数据库的协调节点参数和本地参数 服务器配置文件包含着配置服务器行为的参数。UDB-TX分布式数据的配置文件postgresql.conf位于数据库实例的数据目录之下。
协调节点和每一个数据节点实例都有自己的postgresql.conf文件。一些参数是本地的:每个数据节点实例检查它的 postgresql.conf文件来得到这类参数的值。在协调节点和每一个数据节点实例上都要设置本地参数。
其他参数是用户要在协调节点实例上设置的协调节点参数。其值会在查询运行时被向下传递到数据节点实例(或者在某些情况中会被忽略)。
有关本地以及协调节点服务器配置参数的信息请见UDB-TX分布式数据库参考指南。
设置配置参数
很多配置参数限制了谁能改变它们以及何时何处它们可以被设置。例如,要改变特定的参数,用户必须是一个UDB-TX分布式数据库超级用户。其他参数只能从postgresql.conf文件中在系统级别上被设置,或者还要求系统重启让设置生效。
很多配置参数是会话参数。用户可以在系统级别、数据库级别、角色级别或者会话级别设置会话参数。数据库用户可以在他们的会话中改变大部分会话参数,但是某些要求超级用户权限。
关于设置服务器配置参数的信息请见UDB-TX分布式数据库参考指南。
设置本地配置参数
要在多个数据节点中改变一个本地配置参数,在每一个目标数据节点的postgresql.conf文件中更新该参数,包括主要的和镜像的数据节点。使用gpconfig工具可以在所有的UDB-TX分布式 postgresql.conf文件中设置一个参数。例如:
$ gpconfig -c gp_vmem_protect_limit -v 4096 重启UDB-TX分布式数据库让配置改变生效:
$ gpstop -r
设置协调节点配置参数
要设置协调节点配置参数,请在UDB-TX分布式数据库的协调节点实例上设置它。如果它也是一个会话参数,用户可以为一个特定数据库、角色或者会话设置该桉树。如果一个参数在多个级别上都被设置,最细粒度级别上的设置会优先。例如,会话覆盖角色,角色覆盖数据库,而数据库覆盖系统。
在系统级别设置参数
协调节点的postgresql.conf 文件中的协调节点参数设置是系统范围默认的。要设置一个协调节点参数:
编辑$协调节点_DATA_DIRECTORY/postgresql.conf文件
找到要设置的参数,取消它的注释(移除前面的#字符),并且输入想要的值。
保存并且关闭该文件。
对于不需要重新启动服务器的会话参数,按如下上传postgresql.conf的改变: $ gpstop -u
对于要求服务器重启的参数更改,按如下重启UDB-TX分布式数据库: $ gpstop -r 关于服务器配置参数的细节,请见 UDB-TX分布式数据库参考指南。
在数据库级别设置参数
使用ALTER DATABASE在数据库级别设置参数。例如:
=# ALTER DATABASE mydatabase SET search_path TO myschema; 当用户在数据库级别设置一个会话参数时,每一个连接到该数据库的会话都使用该参数设置。数据库级别的设置覆盖系统级别的设置。
在角色级别设置参数
使用ALTER ROLE在角色级别设置参数。例如:
=# ALTER ROLE bob SET search_path TO bobschema; 当用户在角色级别设置一个会话参数时,每一个由该角色启动的会话都使用该参数设置。角色级别的设置覆盖数据库级别的设置。
在会话中设置参数
任何会话参数都可以在一个活动数据库会话中用SET命令设置。例如:
=# SET statement_mem TO ‘200MB’; 该参数设置对于这个会话的剩余时间都有效,直到发出一个 RESET命令。例如:
=# RESET statement_mem; 会话级别的设置覆盖角色级别的设置。
查看服务器配置参数设置
SQL命令SHOW允许用户查看当前的服务器配置参数设置。例如,要查看所有参数的设置:
$ ud_sql -c ‘SHOW ALL;’ SHOW只列出协调节点实例的设置。要查看整个系统(协调节点和所有的数据节点)中一个特定参数的值,使用 gpconfig工具。例如:
$ gpconfig –show max_connections
配置参数种类
配置参数影响着多种服务器行为,例如资源消耗、查询调节以及认证。下列主题描述了UDB-TX分布式数据库配置参数的种类。
有关配置参数种类的细节,请见UDB-TX分布式数据库参考指南。
连接和认证参数 系统资源消耗参数 查询调节参数 错误报告和日志参数 系统监控参数 运行时统计信息收集参数 自动统计信息收集参数 客户端连接默认参数 锁管理参数 负载管理参数 外部表参数 数据库表参数 数据库和表空间/文件空间参数 以往的PostgreSQL版本兼容参数 UDB-TX分布式阵列配置参数 UDB-TX分布式的协调节点和数据节点镜像参数 UDB-TX分布式数据库扩展参数
启用高可用特性
可以配置UDB-TX分布式数据库的容错和高可用特性。 重要: 当数据丢失对于一个UDB-TX分布式数据库集群不可接受时,就必须启用协调节点和数据节点镜像。如果没有镜像,系统和数据的可用性就无法保障。有关协调节点和数据节点镜像的信息请见关于UDB-TX分布式数据库中的冗余和故障切换。 有关用来启用高可用性的工具的信息,请见UDB-TX分布式数据库工具指南。
UDB-TX分布式数据库高可用性概述 通过提供一个容错硬件平台、启用UDB-TX分布式数据库高可用特性以及执行定期的监控和维护过程来确保所有系统组件的健康,UDB-TX分布式数据库集群可以被配置成高可用的。 在UDB-TX分布式数据库中启用镜像 检测失效的数据节点 恢复失效的数据节点 恢复失效的协调节点
UDB-TX分布式数据库高可用性概述
通过提供一个容错硬件平台、启用UDB-TX分布式数据库高可用特性以及执行定期的监控和维护过程来确保所有系统组件的健康,UDB-TX分布式数据库集群可以被配置成高可用的。
硬件组件最终将会失效,不管是因为正常的磨损还是意外的情况。断电可能导致部件临时不可用。对可能失效的部件提供冗余后备可以让系统变成高可用的,这样当失效真正发生时服务可以继续而不中断。在一些情况下,冗余的代价比用户所能容忍的服务中断更高。当发生这种情况时,目标应该是确保整个服务能被恢复并且能在一个期望的时间表内被恢复。
UDB-TX分布式数据库的容错和数据可用性可以通过下列手段实现:
硬件级RAID存储保护
UDB-TX分布式的数据节点镜像
协调节点镜像
双集群
数据库备份和恢复
硬件级RAID 一种典范的UDB-TX分布式数据库部署会使用硬件级RAID为但磁盘失效提供高性能冗余,而不需要进入到数据库级别的容错。这在磁盘级别提供了一种较低层次的冗余。
数据节点镜像 UDB-TX分布式数据库在多个数据节点中存储数据,其中每个数据节点都是一个UDB-TX分布式数据库的Postgres实例。每个表的数据被基于分布策略散布在数据节点之间,表的分部策略在表创建时由DDL定义。当数据节点镜像被启用时,对每个数据节点都有一对主数据节点和镜像数据节点。主数据节点和镜像数据节点执行相同的IO操作并且存储同一数据的拷贝。
每个数据节点的镜像实例通常由gpinitsystem工具或者gpexpand工具初始化。运行在不同于主实例的主机上的镜像可以防止单机失效。有不同的策略来将镜像指派给主机。在选择主数据节点和镜像数据节点布局时,重点要考虑在单机失效情况下使处理倾斜最小化。
协调节点镜像 在高可用的集群中有两个协调节点,一个主协调节点和一个后备协调节点。和数据节点一样,协调节点和后备协调节点应该被部署在不同的主机上,这样集群能容忍单机失效。客户端会连接到主协调节点,并且只有主协调节点才能执行查询。后备协调节点通过从主协调节点复制预写式日志(WAL)来保持与主协调节点的同步。
如果主协调节点失效,管理员运行gpactivatestandby工具让后备协调节点接替成为新的主协调节点。可以为协调节点和后备协调节点配置虚拟IP地址,这样在当前协调节点改变时客户端程序无需切换到一个不同的网络地址。如果协调节点主机失效,虚拟IP地址可以被交换到实际活动的协调节点上。
双集群 通过维护两个UDB-TX分布式数据库集群(都存储相同的数据),可以提供额外层次的冗余。
在双集群上保持数据同步的两种方法是”双ETL”和”备份/恢复”。
双ETL提供了一个完整的后备集群,它具有和主集群完全像相同的数据。ETL(抽取、转换和装载)表示把到来的数据进行清洗、转换、验证并且装载到数据仓库中的处理。通过双ETL,这一处理会被并行执行两次,在每个集群上执行一次,并且每次都做验证。它还允许在两个集群上查询数据,这可以使查询吞吐量翻倍。应用可以从两个集群获益并且还能确保ETL在两个集群上成功并且被验证。
要用备份/恢复方法维护一个双集群,需要创建主集群的备份并且在第二个集群上恢复它们。这种方法需要双ETL策略更长的时间在第二个集群上同步数据,但是需要开发的应用逻辑更少。当数据修改和ETL以每日或者更低频率被执行时,用备份来填充第二个集群更加理想。
备份和恢复 推荐定期制作数据库的备份,除非该数据库可以容易地从源数据重新生成。应该取得备份来防止操作性、软件和硬件错误。
使用gpcrondump工具备份UDB-TX分布式数据库。gpcrondomp在数据节点间并行地执行备份,这样当集群中增加了新硬件时备份性能也会被放大。
在设计备份策略时,要重点关注的是在哪里存储备份数据。每个数据节点管理的数据可以被备份在该数据节点的本地存储中,但不应被长久存储 - 备份会减少该数据节点可用的磁盘空间,而且更重要的是一次硬件失效可能会同时摧毁该数据节点的实时数据和备份。在执行一次备份后,备份文件应该被从主集群移到独立的、安全的存储。或者,备份可以直接创建在独立的存储上。
备份数据库还有一些额外选项可用,包括:
Data Domain 通过本地API集成,备份可以被流式传送到一台Dell EMC Data Domain装置。 NetBackup 通过本地API集成,备份可以被流式传送到一个Veritas NetBackup集群。 NFS 如果在集群中每台UDB-TX分布式数据库主机上都创建有一个NFS挂载,备份可以被直接写到该NFS挂载。推荐使用一种横向扩展的NFS方案来确保备份不会受到NFS设备IO吞吐量瓶颈的影响。Dell EMC Isilon是一个可以随着UDB-TX分布式集群横向扩展的例子。 增量备份 UDB-TX分布式数据库对于追加优化和列存表允许分区级别的增量备份。在执行一次增量备份时,只有上一次备份以来有改变的追加优化和列存表的分区才会被备份(堆表总是会被备份)。恢复一个增量备份要求恢复上一个完全备份及其后的增量备份。
当数据库包含大型已分区表且大部分分区在两次备份期间保持不变时,增量备份是很有益处的。一个增量备份值保存改变过的分区和堆表。通过跳过未改变的分区,备份的尺寸和时间可以被显著地降低。
如果一个大型的事实表没有被分区,并且增加或者更改了单个行,整个表都会被备份,并且备份尺寸或者时间都没有省下来。因此,只推荐把增量备份用于大型的分区表以及相对较小的维表。
如果维护双集群并且使用增量备份,可以用增量备份来填充第二个集群。这可以使用–noplan选项来实现,它允许来自主站点的备份被更快地应用。
数据节点镜像概述
当UDB-TX分布式数据库高可用性被启用时,有两种类型的数据节点:主数据节点和镜像数据节点。每个主数据节点都有一个对应的镜像数据节点。主数据节点从协调节点接收请求来对该数据节点的数据库做更改并且接着把那些更改复制到对应的镜像。如果主数据节点变成不可用,数据库请求会被故障转移到镜像数据节点。
数据节点镜像采用了一种物理文件复制方案–主数据节点上的数据文件I/O会被复制到镜像数据节点,这样镜像的文件与主数据节点的文件一模一样。UDB-TX分布式数据库中的数据被表示为元组,它们被打包成块。数据库表被存储在由一个或者更多块组成的磁盘文件中。对于元组的一个更改会改变其所在的块,该块接着会被写入到主数据节点上的磁盘并且被通过网络复制到镜像数据节点。镜像会在其文件副本中更新相应的块。
对于堆表,块被保存在一个内存中的缓冲内,直到为了给新更改的块腾空间而将它们排出。这允许系统多次在内存中读写一个块而不需要执行昂贵的磁盘I/O。当块被从缓冲中排出时,它会被写入到磁盘并且复制到镜像中。当块被保存在缓冲中时,主数据节点和镜像数据节点有该块的不同映像。不过,数据库仍然是一致的,因为事务日志已经被复制。如果一个镜像接替了失效的主数据节点,其日志中的事务会被应用到数据库表上。
其他数据库对象(例如文件空间,它是内部由目录表示的表空间)也使用文件复制来以同步的方式执行多种文件操作。
追加优化表不使用缓冲机制。对追加优化表块的更改会被立刻复制到镜像。典型地,文件写操作是异步的,而打开、创建和同步文件是“同步复制的”,这意味着主数据节点会阻塞直到它收到来自镜像数据节点的确认。
如果主数据节点失效,文件复制进程会停止并且镜像数据节点自动地开始作为活动的数据节点实例。当前活动的镜像数据节点的系统状态会变成Change Tracking,这表示在主数据节点不可用期间由该镜像维护系统表以及所有被更新块的改变日志。当失效的主数据节点被修复并且准备好重新回到线上后,管理员可以发起一次恢复处理并且系统进入到Resynchronization状态。恢复处理会将记录下来的更改应用到已被修复的主数据节点。当恢复处理完成后,系统状态会变成Synchronized。
在主数据节点状态为活动时,如果镜像数据节点失效或者变成不可访问,主数据节点的系统状态会变成Change Tracking,并且它会跟踪更改,当镜像被恢复时将更改应用到镜像数据节点。
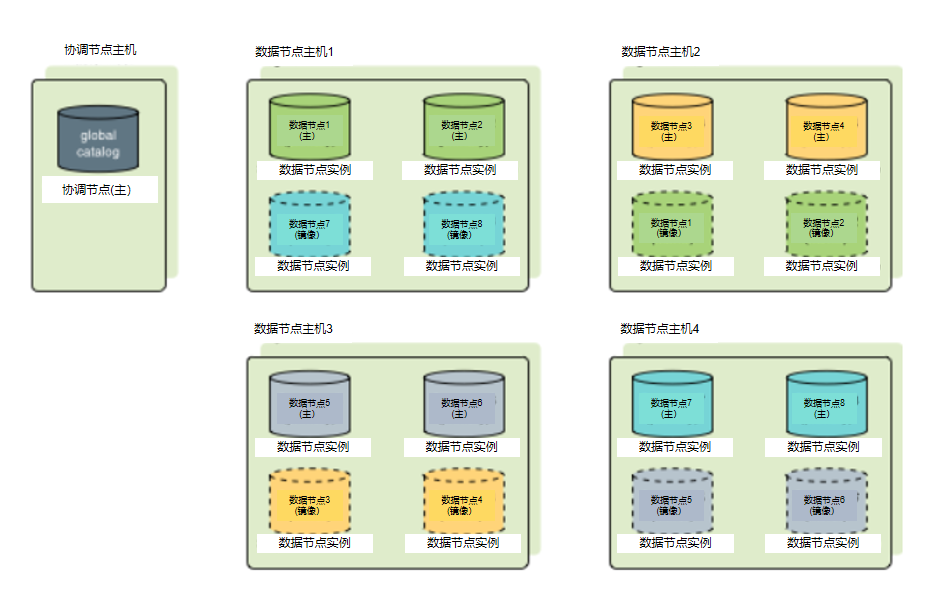
可以以不同的配置把镜像数据节点放置在集群中的主机上,只要求同一个数据节点的主实例和镜像实例在不同的主机上。每台主机必须有相同数量的主数据节点和镜像数据节点。默认的镜像配置是组镜像,在这种配置下,每台主机的主数据节点的镜像数据节点被放置在其他的一台主机上。如果单个主机失效,其后备主机上的活动主数据节点的数量会翻倍。图 1展示了一种组镜像配置。
图 1. UDB-TX分布式数据库中的组数据节点镜像
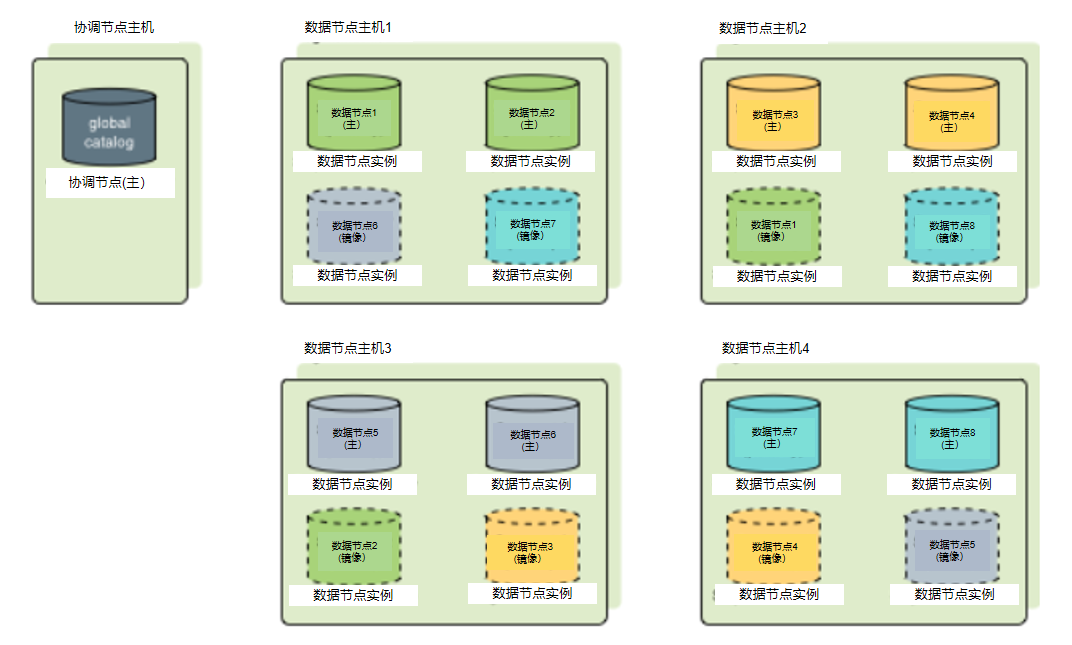
散布镜像把每台主机的镜像散布在多台主机上,这样如果任何一台主机失效,其他主机都不会有超过一个镜像被提升为活动主数据节点。只有当主机数量大于每台主机上的数据节点数量时才能使用散布镜像。图 2展示了在一种散布数据节点镜像配置中镜像的布置情况。
图 2. UDB-TX分布式数据库中的散布数据节点镜像
创建镜像数据节点的UDB-TX分布式数据库工具支持组和散布数据节点配置。自定义的镜像配置可以用一个文件描述,然后在命令行上传入。
协调节点镜像概述
可以在单独的主机或者同一台主机上部署协调节点实例的一个备份或者镜像。当主协调节点变得无法使用时,备份协调节点或者后备协调节点会作为一个温备提供服务。可在主协调节点在线时从中创建一个后备协调节点。
在取一个主协调节点实例的事务快照时,主协调节点会继续为用户提供服务。在取事务快照以及在后备协调节点上部署事务快照时,对主协调节点的更改也会被记录。在该快照被部署在后备协调节点上之后,那些更新会被部署以同步后备协调节点和主协调节点。
一旦主协调节点和后备协调节点被同步好,后备协调节点会通过walsender和walreceiver复制进程保持与主协调节点的同步。walreceiver是后备协调节点进程。walsender进程是主协调节点进程。这两个进程使用基于预写式日志(WAL)的流复制来保持主协调节点和后备协调节点同步。在WAL日志中,所有的修改都在被应用之前先写入到日志来确保任何进程内操作的数据完整性。 注意: WAL日志对数据节点镜像还不可用。 由于协调节点不保存用户数据,只有系统目录表被在主协调节点和后备协调节点之间同步。当这些表被更新时,更改会被自动地复制到后备协调节点来让它保持与主协调节点的同步。
图 3. UDB-TX分布式数据库中的协调节点镜像
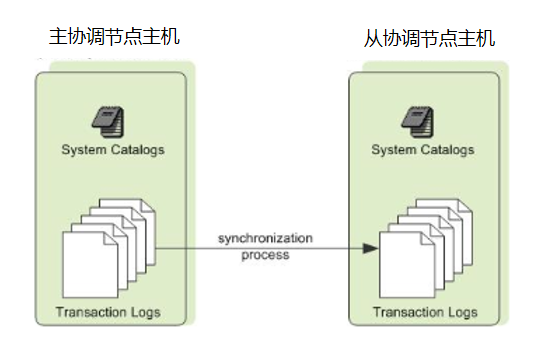
如果主协调节点失效,复制进程会停止并且管理员可以激活后备协调节点。在激活后备协调节点的过程中,复制好的日志可以重构主协调节点在最后一个成功提交事务时的状态。被激活的后备协调节点接下来就像UDB-TX分布式数据库的协调节点一样工作,在后备协调节点初始化时指定的端口上接受连接。
故障检测与恢复概述
UDB-TX分布式数据库服务器名为ftsprobe的(postgres)子进程处理故障检测。ftsprobe会监控UDB-TX分布式数据库阵列,它连接并且扫描所有的数据节点,并且数据库会按照配置的间隔进行这种处理。
如果ftsprobe无法连接到一个数据节点,它会在UDB-TX分布式数据库系统目录中标记该数据节点为”down”。该数据节点会保持无法操作的状态直到管理员发起恢复处理。
如果启用了镜像,在主副本不可用时,UDB-TX分布式数据库会自动故障转移到镜像副本。由于所有的数据在余下的活动数据节点上客户用,如果数据节点实例或者主机失效,系统也是可操作的。
要恢复失效的数据节点,管理员需要运行gprecoverseg恢复工具。这个工具定位失效的数据节点、验证它们是否有效并且与当前活动的数据节点比较事务状态来确定该数据节点离线期间所作的更改。gprecoverseg会与活动的数据节点同步发生改变的数据库文件并且重新让数据节点上线。管理员可以在UDB-TX分布式数据库在线且运行时执行恢复。
如果禁用了镜像,当一个数据节点实例失效时,系统会自动关闭。在操作能继续之前,管理员必须手工恢复所有的失效数据节点。
故障检测与恢复处理和配置选项的详细描述请见检测失效的数据节点。
在UDB-TX分布式数据库中启用镜像
可以在建立UDB-TX分布式数据库系统时使用gpinitsystem配置系统使用镜像,或者之后用gpaddmirrors以及gpinitstandby启用镜像。这个主题假定现有系统初始化时没有镜像,现在要向其中加入镜像。
启用数据节点镜像
镜像数据节点允许数据库查询在主数据节点不可用时故障转移到备用数据节点。默认情况下,镜像会被配置在主数据节点所在的主机阵列上。也可以为镜像数据节点选择一组完全不同的主机,这样它们就不会分享任何主数据节点的机器。
重要: 在在线数据复制处理期间,UDB-TX分布式数据库应该处于一种静止状态,不应运行负载和其他查询。 要增加数据节点镜像到一个现有系统(和主数据节点相同的主机)
在所有的数据节点主机上为镜像数据分配数据存储区域。数据存储区域必须与主数据节点的文件系统位置不同。
使用gpssh-exkeys确保数据节点主机能通过SSH和SCP免密码连接到彼此。
运行gpaddmirrors工具在UDB-TX分布式数据库系统中启用镜像。例如,在主数据节点端口号基础上加10000来计算得到镜像数据节点的端口号: $ gpaddmirrors -p 10000 其中-p指定要加在主数据节点端口号上的数字。使用默认的组镜像配置来增加镜像。
要增加数据节点镜像到一个现有系统(和主数据节点不同的主机)
确保在所有主机上都安装有UDB-TX分布式数据库软件。详细的安装指导请见UDB-TX分布式数据库安装指南。
在所有的数据节点主机上为镜像数据分配数据存储区域。
使用gpssh-exkeys确保数据节点主机能通过SSH和SCP免密码连接到彼此。
创建一个配置文件,其中列出要在其上创建镜像的主机名称、端口号和数据目录。要创建一个示例配置文件作为起点,可运行: $ gpaddmirrors -o filename
镜像配置文件的格式为:
filespaceOrder=[filespace1_fsname[:filespace2_fsname:…] mirror[content]=content:address:port:mir_replication_port: pri_replication_port:fselocation[:fselocation:…]
例如这是一个配置文件,其中有两个数据节点主机,每个主机上有两个数据节点,并且除了默认的pg_system文件空间之外不配置额外的文件空间:
filespaceOrder= mirror0=0:sdw1-1:52001:53001:54001:/gpdata/mir1/gp0 mirror1=1:sdw1-2:52002:53002:54002:/gpdata/mir1/gp1 mirror2=2:sdw2-1:52001:53001:54001:/gpdata/mir1/gp2 mirror3=3:sdw2-2:52002:53002:54002:/gpdata/mir1/gp3
运行gpaddmirrors工具在UDB-TX分布式数据库系统中启用镜像: $ gpaddmirrors -i mirror_config_file
其中-i提到所创建的镜像配置文件。
启用协调节点镜像
可以用gpinitsystem来配置一个带有后备协调节点的新UDB-TX分布式数据库系统,或者以后用gpinitstandby来启用后备协调节点。这个主题假定现有系统初始化时没有后备协调节点,现在要向其中加入一个后备协调节点。
有关工具gpinitsystem和gpinitstandby的信息请见UDB-TX分布式数据库工具指南。
要向一个现有系统增加一个后备协调节点
确保后备协调节点主机已经被安装且配置好UDB-TX分布式数据库: gpadmin系统用户已创建、UDB-TX分布式数据库二进制文件已安装、环境变量已设置、SSH密钥已交换并且数据目录已创建。
在当前活动的主协调节点主机上运行gpinitstandby工具向UDB-TX分布式数据库系统增加一个后备协调节点主机。例如: $ gpinitstandby -s smdw 这里-s指定后备协调节点主机的名称。
要把操作切换到后备协调节点上,请见恢复失效的协调节点. 可以在UDB-TX分布式数据库系统视图pg_stat_replication中显示这些信息。该视图列出有关walsender进程的信息,该进程被用于镜像UDB-TX分布式数据库的协调节点。例如,这个命令显示walsender进程的进程ID和状态:
$ psql dbname -c ‘SELECT procpid, state FROM pg_stat_replication;’ 有关pg_stat_replication系统视图的信息请见UDB-TX分布式数据库参考指南。
检测失效的数据节点
如果启用了镜像,UDB-TX分布式数据库会在主数据节点宕机后自动故障转移到一个镜像数据节点上。由于每一部分数据只有一个数据节点实例在线,用户可能不会意识到有一个数据节点宕机了。如果故障发生时有一个事务正在进行中,该事务会回滚并且自动在重新配置好的数据节点集合上重启。
如果整个UDB-TX分布式数据库系统由于一个数据节点失效(例如,如果没有启用镜像或者没有足够的数据节点在线以访问全部用户数据)而变得无法运转,用户在尝试连接到数据库时会看到错误。返回给客户端程序的错误可能表明失效。例如:
ERROR: All 数据节点 databases are unavailable 如何检测和管理数据节点失效 在UDB-TX分布式数据库的协调节点主机上,UDB-TX的postmaster进程会派生一个故障探测进程ftsprobe。它有时也被称作FTS(容错服务器)进程。如果FTS失败,postmaster进程会重启它。
FTS运行在一个循环中,每两次循环之间有一个睡眠间隔。在每一次循环时,FTS会通过向数据节点数据库建立一个TCP套接字连接来探测每一个主数据节点数据库,连接时使用注册在gp_数据节点_configuration表中的主机名和端口。如果连接成功,数据节点会执行一些简单的检查并且回报给FTS。这些检查包括在关键的数据节点目录上执行一次stat系统调用以及检查数据节点实例的内部故障。如果没有检测到问题,一个正面反馈会被发送给FTS并且不会为该数据节点数据库采取行动。
如果无法建立连接或者在超时后没有收到一个回复,则会重试。如果失败的探测次数超过配置的最大次数,FTS会探测该数据节点的镜像以确保它正常,然后更新gp_数据节点_configuration表标记主数据节点为”down”,并且设置该镜像作为主数据节点运行。FTS会在gp_configuration_history中更新被执行的操作。
当只有一个活动的主数据节点并且相应的镜像宕机时,该主数据节点会进入到”Change Tracking Mode”。在这种模式中,对该数据节点的更改会被记录,这样可以同步镜像而无需把主数据节点的完整数据复制给镜像数据节点。
gprecoverseg工具被用来把一个宕机的镜像恢复过来。默认情况下,gprecoverseg执行一次增量恢复,把该镜像置于resync模式中,这会开始把主数据节点记录的更改在镜像上进行重放。如果不能完成增量恢复,恢复会失败并且应该重新以-F选项运行gprecoverseg来执行完全恢复。这会导致主数据节点把所有的数据都复制给镜像。
在gp_segment_configuration表中,对于每个数据节点可以看到”change tracking”、”resync”或者”in-sync”三种模式,还可以看到”up”或”down”两种状态。
gp_segment_configuration表还有两个列role和preferred_role。它们的值可以是表示主数据节点的p或者表示镜像数据节点的m.role列显示该数据节点数据库的当前角色,而preferred_role显示该数据节点的原始角色。在一个平衡的系统中,所有数据节点的role和preferred_role都是匹配的。当它们不匹配时,就可能有每台硬件主机上活动主数据节点数量造成的倾斜。为了重新平衡该集群并且让所有的数据节点回到它们的首选角色,可以用-r选项运行gprecoverseg命令。
这里是影响FTS行为的服务器配置参数集合: gp_fts_probe_threadcount 用于探测数据节点的线程数。默认:16 gp_fts_probe_interval 多长时间开始一次新的FTS循环,以秒计。例如如果设置是60并且探测循环本身需要10秒,FTS处理会睡眠50秒。如果该设置是60并且探测循环需要75秒,FTS进程睡眠0秒。默认值是60,最大值是3600。 gp_fts_probe_timeout 在协调节点和数据节点之间的探测超时时长,以秒计。默认值是20,最大值是3600。 gp_fts_probe_retries 尝试探测一个数据节点的次数。例如如果该设置是5,在第一次尝试失败后将会有4次重试。默认值:5 gp_log_fts FTS的日志级别。值可能是”off”、”terse”、”verbose”或者”debug”。”verbose”设置可以被用在生产环境中为排查问题提供有用的数据。”debug”设置不应该被用在生产中。默认值:”terse” gp_segment_connect_timeout 允许一个镜像做出响应的最大时间(以秒计)。默认:180 除了FTS执行的故障检查之外,如果一个主数据节点无法把数据发送给其镜像,它可以把该镜像的状态改成down。主数据节点把数据放在队列中,并且在经过了gp_数据节点_connect_timeout秒后(表示一个镜像失效)导致镜像被标记为down而且主数据节点进入到变更追踪模式。
启用告警和通知
要接收数据节点失效之类的系统事件的通知,可启用电子邮件或SNMP告警。见启用告警和通知。
检查失效的数据节点
如果启用了镜像,在发生失效时,系统中会出现失效的数据节点而不会中断服务或者出现任何迹象。可以使用gpstate工具验证系统的状态。gpstate提供一个UDB-TX分布式数据库系统中每个单体组件的状态,包括主数据节点、镜像数据节点、协调节点和后备协调节点。
要检查失效的数据节点
在协调节点上,用-e选项运行gpstate工具显示有错误情况的数据节点: $ gpstate -e Change Tracking模式下的数据节点表示对应的镜像数据节点已经宕机。当一个数据节点不是其首选角色时,该数据节点没有按照系统初始化时指定给它的角色操作。这意味着系统可能处于一种不平衡的状态,因为一些数据节点主机上的活动数据节点比系统处于最好性能时多。
修复这种情况的指导请见从数据节点失效中恢复。
要得到一个失效数据节点的详细信息,可检查gp_数据节点_configuration目录表。例如:
$ psql -c “SELECT * FROM gp_数据节点_configuration WHERE status=’d’;”
对于失效的数据节点实例,要关注其主机、端口、首选角色和数据目录。这些信息将会有助于确定要排除故障的主机和数据节点实例。
要显示有关镜像数据节点实例的信息,可运行: $ gpstate -m
为失效数据节点检查日志文件
日志文件可以提供信息来帮助判断一个错误的成因。每个协调节点和数据节点实例都在其数据目录的pg_log中有它们自己的日志文件。协调节点的日志文件包含了大部分信息,应该总是首先检查它。
使用gplogfilter工具来检查UDB-TX分布式数据库的日志文件以获得额外的信息。要检查数据节点的日志文件,使用gpssh在数据节点主机上运行gplogfilter。
要检查日志文件
对于WARNING、ERROR、FATAL或者PANIC日志级别的消息,使用gplogfilter检查协调节点的日志文件:
$ gplogfilter -t
对于每个数据节点实例上的WARNING、ERROR、FATAL或者PANIC日志级别的消息,使用gpssh检查。例如: $ gpssh -f seg_hosts_file -e ‘source /usr/local/UDB-TX分布式-db/UDB-TX分布式_path.sh ; gplogfilter -t /data1/primary//pg_log/gpdb.log’ > seglog.out
恢复失效的数据节点
如果协调节点无法连接到一个数据节点实例,它会在UDB-TX分布式数据库的系统目录中把该数据节点标记为“down”。该数据节点实例会保持离线状态直到管理员采取步骤让它重新回到线上。恢复一个失效数据节点实例或者主机的处理取决于失效原因以及是否启用了镜像。一个数据节点实例可能由于很多原因变得不可用:
数据节点主机不可用,例如由于网络或者硬件失效。
数据节点实例没有运行,例如没有postgres数据监听器进程。
数据节点实例的数据目录损坏或者丢失,例如数据不可访问、文件系统损坏或者磁盘失效。 图 1展示了前述失效场景的高层排查步骤。 图 1. 数据节点失效故障排查矩阵

从数据节点失效中恢复
数据节点主机失效通常会导致多个数据节点失效:在该主机上的所有主数据节点或者镜像数据节点都被标记为“down”并且不可操作。如果没有启用镜像并且一个数据节点宕掉,系统会自动变成不可操作。
在启用了镜像的情况下恢复
确定可以从协调节点主机连接到该数据节点主机。例如: $ ping failed_seg_host_address
排查解决妨碍协调节点主机连接到数据节点主机的问题。例如,主机可能需要被重启或者替换。
在主机上线并且能连接到它后,从协调节点主机运行gprecoverseg工具来重新激活失效的数据节点实例。例如: $ gprecoverseg
恢复过程会启动失效的数据节点并且确定需要同步的已更改文件。该过程可能会花一些时间,请等待该过程结束。在此过程中,数据库的写活动会被禁止。
在gprecoverseg完成后,系统会进入到Resynchronizing模式并且开始复制更改过的文件。这个过程在后台运行,而系统处于在线状态并且能够接受数据库请求。
当重新同步过程完成时,系统状态是Synchronized。运行gpstate工具来验证重新同步过程的状态: $ gpstate -m
要让所有数据节点返回到它们的首选角色
当一个主数据节点宕掉后,镜像会激活并且成为主数据节点。在运行gprecoverseg之后,当前活动的数据节点仍是主数据节点而失效的数据节点变成镜像数据节点。这些数据节点实例并没有回到在系统初始化时为它们指定的首选角色。这意味着,如果数据节点主机上的活动数据节点数量超过了让系统性能最优的数量,系统可能处于一种潜在地非平衡状态。要检查非平衡的数据节点并且重新平衡系统,运行:
$ gpstate -e 所有数据节点都必须在线并且被完全同步以重新平衡系统。在重新平衡过程中,数据库会话保持连接,但正在进行的查询会被取消并且回滚。
运行gpstate -m来确保所有镜像都是Synchronized。 $ gpstate -m
如果有任何镜像处于Resynchronizing模式,等它们完成。
用-r选项运行gprecoverseg,让数据节点回到它们的首选角色。 $ gprecoverseg -r
在重新平衡之后,运行gpstate -e来确认所有的数据节点都处于它们的首选角色。 $ gpstate -e
要从双重故障中恢复 在双重故障中,主数据节点和它的镜像都宕掉。如果在不同的数据节点主机上同时发生硬件失效,就有可能发生这种情况。如果发生双重故障,UDB-TX分布式数据库会变得不可用。要从一次双重故障中恢复:
重启UDB-TX分布式数据库: $ gpstop -r
在系统重启后,运行gprecoverseg: $ gprecoverseg
在gprecoverseg完成后,使用gpstate检查镜像的状态: $ gpstate -m
如果仍有数据节点处于Change Tracking模式,运行一次完整复制恢复: $ gprecoverseg -F 如果无法恢复一台数据节点主机并且损失了一个或者多个数据节点,可以从备份文件中重新创建UDB-TX分布式数据库系统。请见备份和恢复数据库。
在没有启用镜像的情况下恢复
确定能够从协调节点主机连接到该数据节点主机。例如: $ ping failed_seg_host_address
排查解决妨碍协调节点主机连接到数据节点主机的问题。例如,主机可能需要被重新启动。
在主机在线之后,验证能够连接到它并且重启UDB-TX分布式数据库。例如: $ gpstop -r
运行gpstate工具验证所有的数据节点实例都在线: $ gpstate
当一台数据节点主机不可恢复时
如果一台主机是不可操作的(例如由于硬件失效导致),就需要把那些数据节点恢复到备用的硬件资源上。如果启用了镜像,可以使用gprecoverseg从数据节点的镜像把它恢复到另一台主机上。例如:
$ gprecoverseg -i recover_config_file
其中recover_config_file的格式是:
filespaceOrder=[filespace1_name[:filespace2_name:…]failed_host_address: port:fselocation [recovery_host_address:port:replication_port:fselocation [:fselocation:…]] 例如,要恢复到不同于失效主机的另一主机上且该主机没有配置(除默认的pg_system文件空间外)额外的文件空间:
filespaceOrder=sdw5-2:50002:/gpdata/gpseg2 sdw9-2:50002:53002:/gpdata/gpseg2 gp_segment_configuration和pg_filespace_entry系统目录表可以帮助确定当前的数据节点配置,这样才能规划镜像恢复配置。例如,运行下面的查询:
=# SELECT dbid, content, hostname, address, port, replication_port, fselocation as datadir FROM gp_数据节点_configuration, pg_filespace_entry WHERE dbid=fsedbid ORDER BY dbid; 新恢复的数据节点主机必须预装好UDB-TX分布式数据库软件并且按照现有数据节点主机相同的方式配置。
关于数据节点恢复处理
这个主题描述由gprecoverseg管理工具发起的数据节点恢复过程。它描述gprecoverseg执行的动作以及UDB-TX分布式的文件复制和FTS(容错服务)进程如何完成用gprecoverseg发起的恢复。
尽管gprecoverseg是一种在线操作,但其中有两个很短暂的时段所有的I/O都会被暂停。首先,当恢复开始时,在镜像上创建空数据文件时IO会被暂停。其次,在数据文件被同步后,从主数据节点向镜像复制系统文件(例如事务日志)时会暂停IO。这些暂停的长短主要受到必须在镜像上复制的文件系统文件数目以及必须被复制的系统平面文件尺寸影响。在数据库表从主数据节点复制到镜像的过程中,系统处于在线和可用的状态,恢复期间对数据库做的任何更改都会被直接复制到镜像。
要开始恢复,管理员要运行gprecoverseg工具。gprecoverseg会为恢复准备数据节点并且开始进行同步。当同步完成并且数据节点的状态在系统目录中被更新后,数据节点被恢复完成。如果被恢复的数据节点没有运行在它们的首选角色下,可以用gprecoverseg -r让系统重新恢复平衡。
如果没有-F选项,gprecoverseg会增量地恢复数据节点,只复制从镜像进入到down状态以来发生的更改。通过删除镜像的数据目录并且接着从主数据节点同步所有持久数据文件到镜像,-F选项可以完全恢复镜像。
在恢复处理之前和期间,可以运行gpstate -e来查看数据节点的镜像状态。主数据节点和镜像数据节点的状态会在恢复处理进行中被更新。
考虑一对主数据节点和镜像数据节点,其中主数据节点处于活动状态而镜像数据节点处于down的状态。下面的表展示了镜像恢复开始前数据节点的状态。
| 首选角色 | 当前角色 | 模式 | 状态 | |
|---|---|---|---|---|
| 主数据节点 | p (主) | p (主) | c (改变跟踪) | u (up) |
| 镜像数据节点 | m (镜像) | m (镜像) | s (同步中) | d (down) |
这些数据节点都处于它们的优先角色,但镜像数据节点处于宕机状态。主数据节点已启动并且处于改变跟踪模式,因为它无法把改变发送到它的镜像。
数据节点恢复准备
gprecoverseg工具为恢复操作准备好数据节点然后退出,允许UDB-TX分布式的文件复制进程从主数据节点复制数据到镜像。
在gprecoverseg执行期间会完成下列处理步骤。
标识出宕机的数据节点。
初始化镜像数据节点进程。
对于完全恢复(-aF):
宕机的数据节点的数据目录会被删除。
创建一个新的数据目录。
gp_segment_configuration系统表中的数据节点模式被更新为’r’(重新同步模式)。
后台会执行下面这些:
允许到协调节点的被禁止的IO连接,但是不允许来自被恢复数据节点的读写。
在主数据节点上扫描持久化的表。
对于每个持久化文件对象(pg_class系统表中的relfilenode),在镜像上创建一个数据文件。
数据文件的数量越大,IO被暂停的时间越长。
对于增量恢复,IO会被暂停一段更短的时段,因为只有在该镜像被标记为宕机之后在主数据节点上增加(或者删除)的文件系统对象才需要在镜像上创建(或者删除)。
gprecoverseg脚本完成。 一旦gprecoverseg已经完成,数据节点就处于下表所展示的状态。
| 首选角色 | 当前角色 | 模式 | 状态 | |
|---|---|---|---|---|
| 主 | p (主) | p (主) | r (重新同步中) | u (up) |
| 镜像 | m (镜像) | m (镜像) | r (重新同步中) | u (up) |
数据文件复制
文件复制进程会在后台执行数据文件的重新同步。运行gpstate -e可以检查重新同步的进展。在这一处理完成后,UDB-TX分布式系统进入到对负载完全可用的状态。
在重新同步过程中遵照以下步骤:
数据拷贝(完全恢复和增量恢复): 在文件系统对象被创建后,会为受影响的数据节点开始数据拷贝。ResyncManager进程扫描持久化表系统目录来寻找要被同步的文件对象。ResyncWorker进程把那些文件对象从主数据节点同步到镜像数据节点。
在数据拷贝期间数据库事务所作的任何改变或者创建的新数据会被直接镜像到镜像数据节点。
一旦数据拷贝完成了同步持久化数据文件,文件复制会把当前主数据节点上的共享内存状态更新为’insync’。
平面文件复制 在这一阶段,主数据节点数据目录中的系统文件会被拷贝到该数据节点的数据目录中。在下列平面文件被从主数据目录拷贝到该数据节点数据目录的过程中,IO被暂停:
pg_xlog/*
pg_clog/*
pg_distributedlog/*
pg_distributedxidmap/*
pg_multixact/members
pg_multixact/offsets
pg_twophase/*
global/pg_database
global/pg_auth
global/pg_auth_time_constraint
这些文件被拷贝后,IOSUSPEND结束。
在协调节点上的容错服务器(ftsprobe)进程下一次苏醒时,它将把主数据节点和镜像数据节点的状态设置为同步(mode=s, state=u)。一次分布式查询也将会触发ftsprobe去更新该状态。
当所有数据节点恢复和文件复制处理完成后,gp_数据节点_configuration系统表和gp_state -e的输出中的数据节点状态如下表所示。
| 首选角色 | 当前角色 | 模式 | 状态 | |
|---|---|---|---|---|
| 主 | p (主) | p (主) | s (已同步) | u (up) |
| 镜像 | m (镜像) | m (镜像) | s (已同步) | u (up) |
影响数据节点恢复的因素 下面是一些能影响数据节点恢复过程的因素。
数据库对象的数量,主要是表和索引。
数据节点数据目录中的数据文件数量。
在重新同步期间更新数据的负载类型 – DDL和DML(插入、更新、删除和截断)。
数据的尺寸。
系统文件的尺寸,例如事务日志文件、pg_database、pg_auth和pg_auth_time_constraint。
恢复失效的协调节点
如果主协调节点失效,日志复制会停止。使用gpstate -f命令来检查后备复制的状态。使用gpactivatestandby来激活后备协调节点。在激活后备协调节点过程中,UDB-TX分布式数据库会重构协调节点主机为最后一次成功提交事务时的状态。
要激活后备协调节点
确保为系统已经配置了一个后备协调节点主机。见启用协调节点镜像。
从正在激活的后备协调节点主机运行gpactivatestandby工具。例如: $ gpactivatestandby -d /data/协调节点/gpseg-1 其中-d指定正在激活的协调节点主机的数据目录。
在激活后备之后,它会变成UDB-TX分布式数据库阵列中的活动或者主协调节点。
在该工具结束后,运行gpstate来检查状态: $ gpstate -f 最新被激活的协调节点的状态应该是Active。如果配置了一个新的后备主机,它的状态是Passive。在没有配置后备协调节点时,该命令会显示-No entries found,该消息表示没有配置后备协调节点实例。
在切换到最新的活动协调节点主机后,在其上运行ANALYZE。例如: $ psql dbname -c ‘ANALYZE;’
可选:如果运行gpactivatestandby工具时没有指定一个新的后备主机,之后可使用gpinitstandby配置一个新的后备协调节点。应在活动协调节点主机上运行gpinitstandby例如: $ gpinitstandby -s new_standby_协调节点_hostname
在恢复后还原协调节点镜像
在激活一台后备协调节点进行恢复后,该后备协调节点会成为主协调节点。如果后备协调节点具有和原始协调节点主机相同的能力和可靠性,可以继续把该实例当作主协调节点。
必须初始化一个新的后备协调节点继续提供协调节点的镜像,除非在激活前一个后备协调节点时已经这样做了。在活动的协调节点主机上运行gpinitstandby来配置一个新的后备协调节点。
可以在原来的主机上恢复主协调节点和后备协调节点。这个过程会交换主协调节点主机和后备协调节点主机的角色,只有强烈希望在恢复场景之前的相同主机上运行协调节点实例时才应该执行这样的处理。
更多关于UDB-TX分布式数据库工具的信息请见UDB-TX分布式数据库工具指南。
在原来的主机上恢复协调节点和后备实例(可选)
确认原来的协调节点主机有可靠的运行条件,确保以前的失效原因已被修复。
在原来的协调节点主机上,移动或者移除数据目录gpseg-1。这个例子把该目录移动到backup_gpseg-1: $ mv /data/协调节点/gpseg-1 /data/协调节点/backup_gpseg-1 一旦后备被成功地配置,就可以移除备份目录。
在原来的协调节点主机上初始化一个后备协调节点。例如,从当前的协调节点主机(smdw)运行这个命令: $ gpinitstandby -s mdw
在初始化完成后,检查后备协调节点(mdw)的状态,用-f 选项运行gpstate来检查状态: $ gpstate -f 状态应该是In Synch。
在后备协调节点上停止UDB-TX分布式数据库的协调节点实例。例如: $ gpstop -m
从原始的协调节点主机mdw运行gpactivatestandby工具,该主机当前是一个后备协调节点。例如: $ gpactivatestandby -d $协调节点_DATA_DIRECTORY 其中-d选项指定正在激活的主机的数据目录。
在该工具完成后,运行gpstate来检查状态: $ gpstate -f 验证原来的主协调节点状态为Active。当没有配置一个后备协调节点时,该命令显示-No entries found并且该消息表示没有配置一个后备协调节点实例。
在后备协调节点主机上,移动或者移除数据目录gpseg-1。这个例子移动该目录: $ mv /data/协调节点/gpseg-1 /data/协调节点/backup_gpseg-1 一旦成功地配置好后备,就可以移除备份目录。
在原来的协调节点主机运行主UDB-TX分布式数据库协调节点之后,可以在原来的后备协调节点主机上初始化一个后备协调节点。例如: $ gpinitstandby -s smdw
可以显示UDB-TX分布式数据库系统视图pg_stat_replication中的信息。该视图列出用于UDB-TX分布式数据库协调节点镜像的walsender进程的信息。例如,这个命令显示walsender进程的进程ID和状态:
$ psql dbname -c ‘SELECT procpid, state FROM pg_stat_replication;’
备份和恢复数据库
这个主题描述如何使用UDB-TX分布式的备份和恢复特性。
定期执行备份能确保在数据损坏或者系统失效发生时能恢复数据或者重建UDB-TX分布式数据库系统。用户还可以使用备份从一个UDB-TX分布式数据库系统迁移数据到另一个。
扩展UDB-TX分布式系统
管理UDB-TX分布式数据库访问
使用数据库
这一节中的主题描述了如何创建和管理数据库对象以及如何在数据库中操纵数据。此外还有一些主题介绍了在UDB-TX分布式这一MPP环境中的并行数据装载和SQL查询编写。
管理性能
这一节中的主题涵盖了UDB-TX分布式数据库性能管理,包括如何监控性能以及如何配置负载来安排好资源利用。
UDB-TX分布式数据库工具指南
并行数据装载UDLOAD
udload工具使用可读外部表和并行文件服务器udfdist来装载数据。它处理并行的基于文件的外部表设置并且允许用户在一个单一配置文件中配置他们的数据格式、外部表定义。相较于批量insert或copy语句他具有极高的性能,因为它通过并行文件服务直接将text或csv格式的表数据并行装载到数据节点中。
udload可以在任何一台可以访问数据库所有主机的机器上进行,如果使用一台独立的主机则需解压udb-da安装包使用其中带的udload工具,如果是小型非长时间运行的数据导入任务建议可以直接在协调节点Coordinator主机上进行(默认已带udload工具)。
准备数据文件
将业务系统的数据导出为csv格式数据,上传到udload工具所在主机的文件系统下
创建目标表
事先创建好需要导入的表
编辑yaml配置文件
创建udload工具的配置文件
---
VERSION: 1.0.0.1
DATABASE: db_name
USER: db_username
HOST: master_hostname
PORT: master_port
UDLOAD:
INPUT:
- SOURCE:
LOCAL_HOSTNAME:
- hostname_or_ip
PORT: http_port
| PORT_RANGE: [start_port_range, end_port_range]
FILE:
- /path/to/input_file
SSL: true | false
CERTIFICATES_PATH: /path/to/certificates
- FULLY_QUALIFIED_DOMAIN_NAME: true | false
- COLUMNS:
- field_name: data_type
- TRANSFORM: 'transformation'
- TRANSFORM_CONFIG: 'configuration-file-path'
- MAX_LINE_LENGTH: integer
- FORMAT: text | csv
- DELIMITER: 'delimiter_character'
- ESCAPE: 'escape_character' | 'OFF'
- NULL_AS: 'null_string'
- FORCE_NOT_NULL: true | false
- QUOTE: 'csv_quote_character'
- HEADER: true | false
- ENCODING: database_encoding
- ERROR_LIMIT: integer
- LOG_ERRORS: true | false
EXTERNAL:
- SCHEMA: schema | '%'
OUTPUT:
- TABLE: schema.table_name
- MODE: insert | update | merge
- MATCH_COLUMNS:
- target_column_name
- UPDATE_COLUMNS:
- target_column_name
- UPDATE_CONDITION: 'boolean_condition'
- MAPPING:
target_column_name: source_column_name | 'expression'
PRELOAD:
- TRUNCATE: true | false
- REUSE_TABLES: true | false
SQL:
- BEFORE: "sql_command"
- AFTER: "sql_command"
参数说明:
| 名称 | 描述 |
| :——— | :——————————————————————- |
| VERSION | 可选。当前版本是1.0.0.1 |
| DATABASE | 可选。指定要连接到哪个数据库。默认为当前系统用户名。|
| USER | 可选。指定用于连接的数据库角色。默认为当前用户。|
| HOST | 可选。指定数据库协调节点Coordinator主机名。如果没有指定,默认为localhost。|
| PORT | 可选。指定数据库协调节点Coordinator的端口。如果没有指定,默认为5678。|
| UDLOAD | 必需。UDLOAD说明小节。UDLOAD说明必须定义有一个INPUT小节和一个OUTPUT小节。|
| INPUT | 必需。定义要装载的输入数据的位置和格式。|
| -SOURCE | 必需。SOURCE块属于INPUT小节,定义源文件的位置。一个INPUT小节可以定义多个SOURCE块。每个定义的SOURCE块对应于将在本地机器上启动的一个udfdist文件分发实例。每个定义的SOURCE块必须有一个FILE说明。|
| -LOCAL_HOSTNAME | 可选。指定udload本地机器的主机名或者IP地址。如果这个机器有多个网络接口卡(NIC),用户可以指定多个,以便允许网络流量同时使用所有的NIC。默认是仅使用本地机器的主要主机名或者IP。|
| -PORT | 可选。指定udfdist文件分发程序使用的特定端口号。用户还可以提供一个PORT_RANGE来从指定的范围中选择可用的端口。如果PORT和PORT_RANGE同时被定义,那么PORT优先。如果PORT和PORT_RANGE都没有定义,默认为在8000和9000之间选择一个可用端口。|
| -FILE | 必需。指定本地文件系统上的一个文件位置、命名管道或者目录位置,其中包含要被装载的数据。用户可以声明多个文件,只要所有指定文件中数据的格式相同。支持扩展名为.gz或者.bz2的压缩文件,这些文件将被自动解压缩。在指定要装载哪些源文件时,用户可以使用通配符(*)或其他C风格的模式匹配来指示多个文件。被指定的文件假定在相对于udload被执行的当前目录的位置(或者用户可以声明绝对路径)。|
| -COLUMNS | 可选。以field_name:data_type这样的格式指定源数据文件的模式。如果输入COLUMNS没有指定,则使用输出TABLE的模式,意味着源数据必须与目标表具有相同的列序、列数以及数据格式。默认的source-to-target映射基于这一节定义的列名与目标TABLE中列名之间的匹配。默认映射可以使用MAPPING小节覆盖。|
| -FORMAT | 可选。指定源数据文件的格式:TEXT格式,CSV格式。如果没有指定,这个默认为TEXT。|
| -DELIMITER | 可选。指定在每行数据内分隔列的单个ASCII字符。在TEXT模式中默认是一个制表符,在CSV模式中默认是一个逗号。用户还可以指定一个非可打印ASCII字符或者非可打印Unicode字符,例如:”\x1B”或者 “\u001B”。对于非可打印字符也支持转义字符串语法E’character-code’。ASCII或Unicode字符必须被封闭在单引号中。例如:E’\x1B’或者E’\u001B’。|
| -NULL_AS | 可选。指定表示空值的字符串。TEXT模式中默认是\N(反斜线-N),CSV模式中默认是没有引用的空的值。即便在TEXT模式中,对于想要把空值与空字符串区分开来的情况,用户也可以使用空字符串。任何匹配这个字符串的源数据项将被认为是一个空值。|
| -QUOTE | 当FORMAT是CSV时,这个元素是必需的。为CSV模式指定引用字符。默认是双引号(”)。|
| -HEADER | 可选。指定数据文件中的第一行是一个头部行(包含列名)并且不应被包括在要被装载的数据中。如果使用多个数据源文件,所有的文件必须有一个头部行。默认是假定输入文件没有头部行。|
| -ENCODING | 可选。源数据的字符集编码。可指定一个字符串常量(例如’SQL_ASCII’)、一个整数编码编号,或者指定’DEFAULT’以使用默认客户端编码。如果没有指定,默认的客户端编码会被使用。|
| -ERROR_LIMIT | 可选。为这个装载操作启用单行错误隔离模式。当被启用时,在输入被处理期间只要没有达到错误限制计数,任何DataNode会抛弃有格式错误的输入行。如果错误限制没有达到,所有好的行将会被装载并且任何错误行都将被抛弃或者被捕捉在错误日志信息中。默认是在遇到第一个错误时中止装载操作。注意单行错误隔离只适用于有格式错误的数据行,例如有额外或者缺失的属性、有错误数据类型的属性或者有无效的客户端编码序列。如果遇到约束错误(例如主键约束)仍将导致装载操作中止。|
| -LOG_ERRORS | 当ERROR_LIMIT被声明时,这个元素是可选的。值可以是true或者false。默认值是false。如果值是true,当运行在单行错误隔离模式中时,格式错误的行会被内部记录下来。用户可以用数据库的内建SQL函数ud_read_error_log(’table_name’)检查格式错误。用户可以用数据库的函数ud_truncate_error_log()从错误日志中删除格式错误。|
| OUTPUT | 必需。定义要被装载到数据库中的目标表和最终数据列值。|
| -TABLE | 必需。要装载的目标表名。|
| -MODE | 可选。如果没有指定,则默认为INSERT。有三种可用的装载模式:INSERT - 使用下列方法装载数据到目标表中:INSERT INTO target_table SELECT * FROM input_data; UPDATE - 更新目标表中MATCH_COLUMNS属性值等于输入数据并且UPDATE_CONDITION为true(可选条件)的行的UPDATE_COLUMNS。MERGE - 插入新行并且更新FOOBAR属性值等于相应输入数据而且MATCH_COLUMNS为true(可选条件)的已有行的UPDATE_COLUMNS。当源数据中的MATCH_COLUMNS值在目标表数据中没有相应值时会被标识成新行。在那种情况下,源文件中的整个行会被插入,而不仅仅是MATCH和UPDATE列。如果有多个相等的新MATCH_COLUMNS值,只有其中一个新行将被插入。使用UPDATE_CONDITION可过滤掉要抛弃的行。|
| -MATCH_COLUMNS | 如果MODE为UPDATE或者MERGE,则这个元素是必需的。指定被用作更新的连接条件的列。对于要在目标表中更新的行,指定目标列中的属性值必须等于相应的源数据列值。|
| -UPDATE_COLUMNS | 果MODE为UPDATE或者MERGE,则这个元素是必需的。指定对符合MATCH_COLUMNS条件和可选UPDATE_CONDITION的行要更新的列。|
| -UPDATE_CONDITION | 可选。指定目标表中要被更新的行(在MERGE情况下是要被插入的行)必须满足的一个布尔条件(类似于在WHERE子句中声明的那样)。|
| -MAPPING | 可选。如果指定一个映射,它会覆盖默认的source-to-target列映射。默认的source-to-target映射基于源COLUMNS小节定义的列名与目标TABLE中列名之间的匹配。映射可以被指定为:target_column_name: source_column_name或者target_column_name: ‘expression’其中expression是在查询的SELECT列表中指定的任意表达式,例如常量值、列引用、操作符调用、函数调用等等。|
| PRELOAD | 可选。指定在装载操作之前运行的操作。目前唯一的预装载操作是TRUNCATE。|
| -TRUNCATE | 可选。如果设置为true,udload将在装载目标表之前移除其中所有的行。|
| -REUSE_TABLES| 可选。如果设置为true,udload将不会删除它创建的外部表对象和阶段性对象。这些对象将被重用于未来使用同一装载说明的装载操作。这会提高小型装载的性能(正在进行的到同一目标表的小型装载)。如果LOG_ERRORS: true被指定,REUSE_TABLES: true必须被指定以保留数据库错误日志中的格式错误。如果REUSE_TABLES: true没有被指定,格式错误信息会在udload操作之后被删除。|
| SQL | 可选。定义在装载操作之前或者之后要运行的SQL命令。用户可以指定多个BEFORE或者AFTER命令。按照想要的执行顺序列出命令。|
| -BEFORE | 可选。在装载操作开始之前要运行的一个SQL命令。将命令封闭在引号中。|
| -AFTER | 可选。在装载操作完成之后要运行的一个SQL命令。将命令封闭在引号中。|
执行udload
-f : 指定配置文件路径
-h -p -U 分别是要连接的数据库协调节点主机地址、端口、用户,如果在yaml配置文件中已经设置,则不需要填写
PXF
PXF提供的连接器可以用于访问存储在UDB-TX分布式数据库外部源中的数据。这些连接器将外部数据源映射到UDB-TX分布式数据库的外部表(external table)中。在创建外部表时,你可以通过在命令中提供服务器名称和配置文件名称来标识外部数据存储和数据格式。您可以通过UDB-TX分布式数据库查询外部表引用的数据,您也可以使用外部表将数据加载到数据库中以获得更高的性能。
UDB-TX集群包含一个coordinater节点和多个数据节点主机。数据节点主机上的PXF客户端进程为对外部表进行查询的每个datanode instance分配工作线程。多个datanode主机的PXF代理与外部数据存储并行通信。
连接器
PXF提供创建了与Hadoop (HDFS,Hive,Hbase),对象存储(Azure,Google Cloud Storage, Minio, S3)和sql数据库(通过jdbc)的连接器。
创建一个外部表
PXF实现了一个叫做pxf的协议,你可以使用这个协议去创建一个外部表。在创建pxf协议的外部表前您须通过create extension pxf在数据库中创建好pxf扩展。
指定pxf协议的CREATE EXTERNAL TABLE命令语法如下:
CREATE [WRITABLE] EXTERNAL TABLE <table_name>
( <column_name> <data_type> [, ...] | LIKE <other_table> )
LOCATION('pxf://<path-to-data>?PROFILE=<profile_name>[&SERVER=<server_name>][&<custom-option>=<value>[...]]')
FORMAT '[TEXT|CSV|CUSTOM]' (<formatting-properties>);
在创建语句CREATE EXTERNAL TABLE中的LOCATION子句是一个URI。这个URI标识描述外部数据位置的路径和其他信息。例如:如果外部数据存储的是HDFS,则填写指定HDFS文件的绝对路径。如果外部数据存储的是HIVE,则需要指定符合模式的HIVE表名称。使用问号(?)引入的URI的查询部分来标识PXF服务器和配置文件名称。PXF可能需要额外的信息来读取和写入某些数据格式,可以使用LOCATION字符串的可选组件 = 来提供配置文件的信息,并通过字符串的组件提供格式信息。
| 参数 | 描述 |
| :——— | :——————————————————————- |
| <path‑to‑data> | 目录,文件名,通配符模式,表名等。的语法取决于外部数据源 |
| PROFILE=<profile_name> | PXF用于访问数据的配置文件。 PXF支持Hadoop services, object stores, and other SQL databases. |
| SERVER=<server_name> | PXF用于访问数据的命名服务器配置。可选的; 如果未指定,PXF将使用default服务器。 |
| <custom‑option>=
配置pxf
您可以通过PXF连接器读取数据或将数据写入外部数据存储。要访问外部数据存储,您必须提供服务器位置。PXF服务器名称是位于$PXF_BASE/servers/中的目录的名称。您在服务器配置中提供的信息是特定于连接器的。例如,PXF JDBC连接器服务器定义可以包括JDBC驱动程序类名称,URL,用户名和密码的设置。您还可以在JDBC服务器定义中配置特定于连接的属性和特定于会话的属性。PXF为每个连接器提供一个服务器模板文件。此模板标识必须配置才能使用连接器的典型属性集。
您将为UDB-TX分布式数据库用户需要访问的每个外部数据存储配置服务器定义。例如,如果您需要访问两个Hadoop集群,则将为每个集群创建PXF Hadoop服务器配置。如果需要访问Oracle和MySQL数据库,则将为每个数据库创建一个或多个PXF JDBC服务器配置。
服务器模板文件
PXF服务器的配置信息位于$PXF_BASE/servers/<server_name>/中的一个或多个
unvdb@cn1$ ls $PXF_BASE/servers/default
adl-site.xml hbase-site.xml jdbc-site.xml s3-site.xml
core-site.xml hdfs-site.xml mapred-site.xml wasbs-site.xml
gs-site.xml hive-site.xml minio-site.xml yarn-site.xml
例如,s3-site.xml模板文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>fs.s3a.access.key</name>
<value>YOUR_AWS_ACCESS_KEY_ID</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>YOUR_AWS_SECRET_ACCESS_KEY</value>
</property>
<property>
<name>fs.s3a.fast.upload</name>
<value>true</value>
</property>
</configuration>
您可以在配置文件中以明文形式为PXF指定凭据。
Note: Hadoop连接器的模板文件仅提供所需信息的示例。您无需修改Hadoop模板,而是将几个Hadoop* -site.xml文件从Hadoop集群复制到PXF Hadoop服务器配置路径下即可。
关于默认服务器
PXF定义了一个名为default的特殊服务器。目录路径为$PXF_BASE/servers/default/。您可以配置默认PXF服务器并将其分配给任何外部数据源。例如,您可以将PXF默认服务器分配给Hadoop集群,或者分配给用户经常访问的MySQL数据库。
如果您在CREATE EXTERNAL TABLE命令LOCATION子句中省略了SERVER=<server_name>设置,则PXF将自动使用default服务器配置。
Note: 当您的Hadoop集群使用Kerberos身份验证时,您必须将Hadoop服务器配置为PXF default服务器。
配置服务器
将PXF连接器配置为外部数据存储时,将为该连接器添加命名的PXF服务器配置。在执行的任务中,您可以:
1.确定是要配置default PXF服务器,还是为服务器配置选择新名称。
2.创建目录$PXF_BASE/servers/<server_name>。
3.将模板或其他配置文件复制到新的服务器目录。
4.为模板文件中的属性填写适当的默认值。
5.添加环境所需的所有其他配置属性和值。
6.如关于配置PXF用户中所述为服务器配置配置一个或多个用户。
7.将服务器和用户配置同步到数据库集群所有主机(命令:pxf cluster sync)。
Note: 添加或更新PXF服务器配置后,必须将PXF配置重新同步到UDB-TX数据库集群。
配置连接器示例
此处以Hadoop连接器为例介绍一下连接器配置过程。配置PXF Hadoop连接器需要将配置文件从Hadoop群集复制到协调节点Coordinator主机。如果你使用的是MapR Hadoop发行版,则还必须将某些JAR文件复制到Coordinator主机。操作步骤如下:
1.登录到Coordinator节点:
ssh udbda@<cn1>
2.确定您的PXF Hadoop服务器配置的名称。如果您的Hadoop集群是Kerberized,则必须使用defaultPXF服务器。
3.如果您没有使用默认的PXF服务器,请创建$PXF_BASE/servers/<server_name>目录。例如,使用以下命令创建名为hdp3的Hadoop服务器配置:
mkdir $PXF_BASE/servers/hdp3
4.转到服务器目录。例如:
cd $PXF_BASE/servers/default
或
cd $PXF_BASE/servers/hdp3
5.PXF服务需要从core-site.xml和其他Hadoop配置文件中获取需要的信息。使用你选择的工具从你的Hadoop集群namenode节点主机上拷贝core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml文件到当前主机上(您的文件路径可能会根据使用的Hadoop发行版而有所不同)。例如,这些命令使用scp去拷贝文件:
cd $PXF_BASE/servers/default
scp hdfsuser@namenode:/etc/hadoop/conf/core-site.xml .
scp hdfsuser@namenode:/etc/hadoop/conf/hdfs-site.xml .
scp hdfsuser@namenode:/etc/hadoop/conf/mapred-site.xml .
scp hdfsuser@namenode:/etc/hadoop/conf/yarn-site.xml .
6.如果你想要使用PXF的HIVE连接器访问hive表的数据,同样拷贝hive的配置到Coordinator主机上。例如:
scp hiveuser@hivehost:/etc/hive/conf/hive-site.xml .
7.如果你想要使用PXF的HBASE连接器访问hbase表数据,同样需要拷贝hbase的配置到Coordinator上。例如:
scp hbaseuser@hbasehost:/etc/hbase/conf/hbase-site.xml .
8.如果你要使用PXF访问MapR Hadoop发行版,你必须要从你的MapR拷贝匹配的JAR文件到GPDB master上(您的文件路径可能会根据使用的MapR版本而有所不同)。例如:这些是使用scp命令拷贝文件
cd $PXF_BASE/lib
scp mapruser@maprhost:/opt/mapr/hadoop/hadoop-2.7.0/share/hadoop/common/lib/maprfs-5.2.2-mapr.jar .
scp mapruser@maprhost:/opt/mapr/hadoop/hadoop-2.7.0/share/hadoop/common/lib/hadoop-auth-2.7.0-mapr-1707.jar .
scp mapruser@maprhost:/opt/mapr/hadoop/hadoop-2.7.0/share/hadoop/common/hadoop-common-2.7.0-mapr-1707.jar .
9.同步PXF的配置到数据库集群其他主机。例如:
pxf cluster sync
10.UDB-TX分布式数据库最终用户访问Hadoop服务。默认情况下,PXF服务尝试使用数据库的用户去验证访问HDFS, Hive, and HBase。为了支持此功能,如果要使用这些PXF连接器,则必须为Hadoop以及Hive和HBase配置代理设置,例如:
vi $PXF_BASE/servers/default/hdfs-site.xml
#修改以下配置的<username>为数据库用户
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>hadoop.proxyuser.<username>.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.<username>.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
</configuration>
11.授予HDFS文件和目录的读取权限,这些文件和目录将作为数据库中的外部表进行访问。 如果启用了用户模拟(默认设置),则必须向每个数据库用户/角色名称授予此权限,这些用户/角色名称将使用引用HDFS文件的外部表。
12.如果您的Hadoop集群使用Kerberos保护,则为HDFS配置PXF必须为每个数据节点主机生成Kerberos主体和密钥表。
管理PXF
启动PXF:
#登录到coordinator主机
ssh udbda@cn1
#设置环境变量
source /path/to/installed/udb_env.sh
#启动
pxf cluster start
停止PXF:
pxf cluster stop
监控PXF:
pxf cluster status